- 会員限定
- 2010/06/10 掲載
サイレント障害とは何か?従来の障害検知手法で発見できない問題
発生の仕組みと対処方法について解説
記事をお気に入りリストに登録することができます。
システムの運用監視では、障害の迅速な検知と対処は重要な問題である。通常は、さまざまな監視ツールを利用して、サーバやルータなどの機器の死活監視やCPUの使用率、ネットワークトラフィックの状態などの監視を行うのが通例だ。しかし、このような監視手法では発見できない障害=サイレント障害というものが存在する。サイレント障害の正体と、その対処方法について見ていくことにしよう。
AeroVision
富士総合研究所(現みずほ情報総研)のSEを経て、出版業界に転身。1993年からフリーランスライターとして独立しAeroVisionを設立。以来、IT系雑誌、単行本、Web系ニュースサイトの取材・執筆やテクニカル記事、IT技術解説記事の執筆、および、情報提供などを業務とする。主な著書に『これならできるVPNの本』(技術評論社、2007年7月)、『新米&シロウト管理者のためのネットワークQ&A』(ラトルズ、2006年5月)など多数。
システム障害はどのように検知するか?
|
|
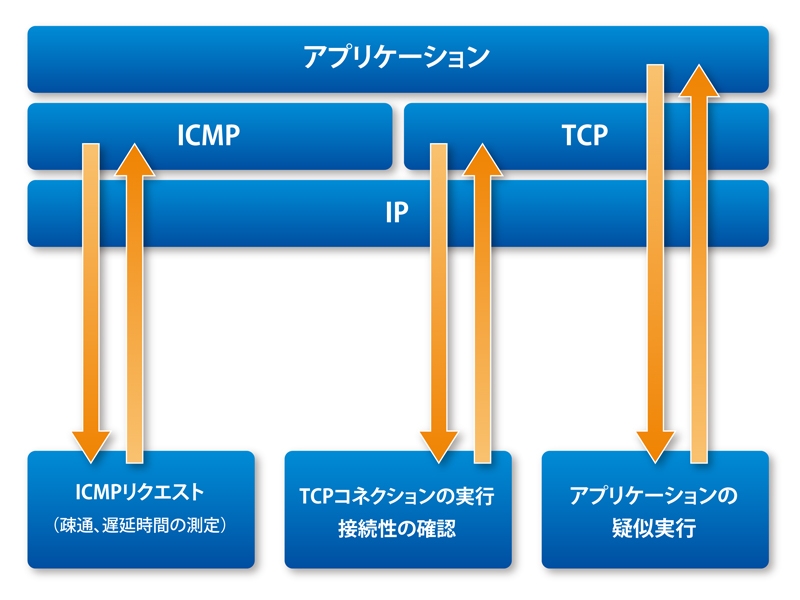
システム監視については、ネットワークの疎通状況やサーバのハードウェア/ソフトウェアの稼働状況、サーバやパフォーマンスの性能監視など、その適用範囲は広い。たとえば、ネットワークやサーバの稼働状況の監視方法については、最も基本的(初歩的)なものに「ICMP」(ping、tracerouteなど)というプロトコルを使った方法がある(図1)。
「ping」「traceroute」コマンドを実行すれば、接続先に至るネットワーク経路の疎通状況や、通信の遅延状況、ルータやサーバの物理的な稼働状況(死活監視)などがわかる。また、サーバに対してテストの接続要求(TCPコネクション要求)を実行したり、サービスへの疑似的な実行を行って、サーバ上のサービスが正常に稼働しているかを監視することができる。
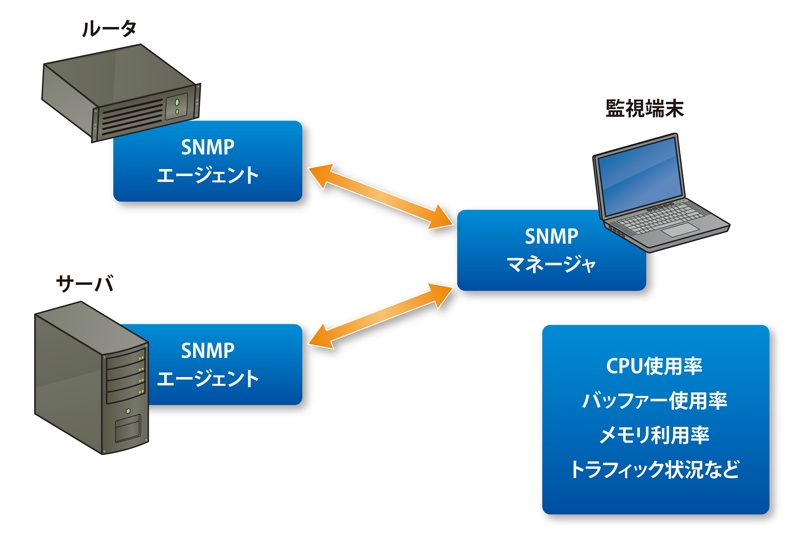
さらには、「SNMP」というネットワーク監視のプロトコル上で、「MIB」という性能監視のためのプロトコルを使い、サーバやルータのCPUの使用率や空きメモリ、回線利用率などの検査を定期的に行い、パフォーマンスを監視する手法も利用されている(図2)。
これらの手法を用いたシステム監視システムではアラート(警告通知)を表示するため、一定の値を「しきい値」として設定し、事前に設定したしきい値を上回る、あるいは、下回った場合にアラートを通知するようになっている。このようなシステム障害への対処方法によって、問題が発生した時に、アラートが通知されることで障害を検知し、その原因を特定して問題を修復するというのが、一般的なアプローチ方法だ。
【次ページ】サイレント障害とは?
関連タグ
あなたの投稿
PR
PR
PR
