- 会員限定
- 2018/06/26 掲載
データ統合基盤の構築方法、ガートナーが解説する技術と組織の両面の取り組み方
今後10年はホットな分野に
記事をお気に入りリストに登録することができます。
データの爆発的な増加と発生場所の広域化によって、データ統合作業は困難さは増す一方だ。だが、こうした中にあっても、データ分析による他社との差別化に向け、データ統合作業を確実に遂行することがITスタッフに強く求められている。とはいえ、課題は多岐にわたり、それらは一筋縄では解決できないものばかりだ。こうした状況にあって、データ統合にどう取り組んでいけばよいのか。ガートナーでリサーチ ディレクターを務めるリック・グリーンウォルド氏が、データ統合の“近代化”の切り口から、技術と組織の両面での適切な取り組み方について解説する。

(©wei - Fotolia)
データ分析を難しくさせるこれだけの理由
関連記事
データ活用の重要性がビジネスのデジタル化に伴い急速に高まっている。基幹業務だけでなく、「開発・生産・物流」、「営業・マーケティング・顧客サービス」、「エコシステム」といった領域にもIoTやスマホ、ネットワーク化などの大波が押し寄せ、そこで生まれるデータ活用の良し悪しが、企業の競争力を左右するまでになっている。
「だが、皮肉なことに、ビジネスのデジタル化が進んでも、データ活用の難しさは変わらないままだ」と指摘するのは、ガートナーでリサーチ ディレクターを務めるリック・グリーンウォルドである。
理由の1つが、IoTは多様なモノの可視化を可能にした半面で、生じるデータは爆発的に増え、分析処理が長引かざるを得なくなっていることだ。
また、データの生成場所が広がったものの、それらの統合分析を阻むデータ形式の個別最適化の問題は、多くの企業で依然として残されたままだ。分析作業の全社的な広がりを背景に、データ管理のガバナンス強化が求められているものの、具体的な手法は非常に見極めにくく、徹底は一筋縄では難しい。データごとに収集タイミングが異なり、その溝をいかに埋めるかも課題となる。
データ統合で考慮すべき「4つの観点」
目指すべき理想像は明らかだ。それが、ビジネスの参加者全員が、あらゆるデータをストレスなく利用できる環境である。その実現のためには、データを次の3つの観点――センサーレベルかシステムレベルかといった「粒度」、リアルタイムかバッチかといった「遅延」、物理的か仮想敵かといった統合の「物理的な程度」、――から捉え、膨大かつ散在する多様な情報の統合手法を検討する必要があるという。グリーンウォルド氏は次のように続ける。
「データ統合を完了できたとしても、あらゆる部署でデータを容易に扱えるよう、再度、“分散”させる必要が生じることも当然、考えられる。そのために、データを3つの観点からどう制御すべきかの解を発見することこそデータ統合における最大のチャレンジとなるはずだ」(グリーンウォルド)
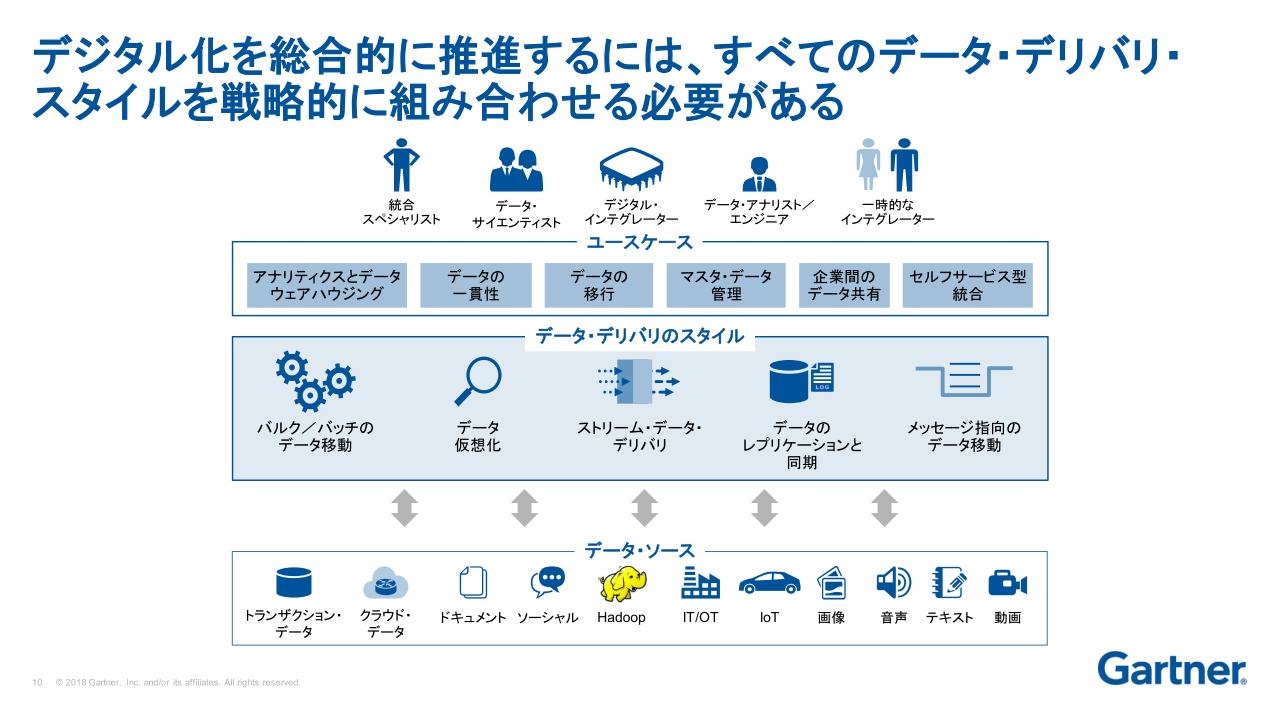
過去を振り返ると、データ統合技術は時代に合わせて進化してきた。それらは、「データ・ソース」「デリバリ方式」「利用法」の3層で捉えられる。はるか以前は各層ごとに1つ、ないしはごく限られ選択肢しか存在しなかった。
それが時代を経るにつれ、例えばデータ・ソースでは昔ながらのテキストのほかクラウドやIoT、デリバリ方式ではストリームデリバリやデータ仮想化、利用法ではDWHやMDM、セルフサービス型統合などの選択肢が追加されてきた。
最後に判断するのは「AI」ではなく「人」
そして現在、データ統合技術は各層ごとの選択肢の掛け合わせによって近代化が進められているという。代表例が、バルク/バッチ処理の時間的な溝を補完するためのストリームによるデータ転送である。また、顧客のより精緻な把握などのために、キャンペーンや個客の声といった関連データベース(DB)の鮮度をCDC(Change Data Capture)で保ちつつ、仮想化で各データを一元的に扱えるようにしたり、多様なデータを仮想化集約したうえで、ELTにより各業務システムに必要なデータだけを抽出して転送していったケースもある。
一方で、グリーンウォルド氏はデータ統合の周辺技術の動向についても次のように解説する。まず、データ分析を支援するセルフサービスツールは今後、分析作業のみならず統合作業でも活用度合いはより大きくなるという。
「データ統合はデータの一貫性や整合性の確保を必要とする難しい作業で、取り組みの中身は大多数のスタッフにとって難解極まりない。セルフサービスツールは知識の溝を埋めるだけでなく、複雑なデータ統合処理そのものの隠蔽化にも効果的なツールだ。これにより、統合の複雑さが一般スタッフの分析作業に与える影響を心配しなくてもよくなるわけだ」(グリーンウォルド氏)
また、AIはデータのプロファイル作成などの自動化が見込める点で、統合作業に今後広く用いられるようになると予想する。
とはいえ、データ統合は極端に言えば2つのデータを「適切」にまとめる作業で、適切か否かの判断は最終的には人でしか行うことができない。従って、AIへの過度な期待は禁物のようだ。
データ統合の整備手法を俯瞰して見ると、現在、オンプレミスとクラウドを組み合わせたハイブリッド型による統合プラットフォームを形成するかたちで進んでいるという。
グリーンウォルド氏は、「このアプローチは、あらゆるデータへの柔軟なアクセスという点で極めて妥当。だが、全データの統合となれば手間や処理は膨大になものとなるため、作業円滑化のために統合対象の適切な絞り込みが必要となる。
とはいえ、その判断もAIはデータの利用頻度の点で知見をもたらすものにすぎず、結局は人が行うしかない」と強調する。
【次ページ】データ専門家とアプリ開発者の協業が成功の鍵
関連タグ
あなたの投稿
PR
PR
PR
