- 会員限定
- 2017/03/10 掲載
Amazon S3がダウン! なにが障害をここまで大きくしたのか? AWSの報告を読み解く
記事をお気に入りリストに登録することができます。
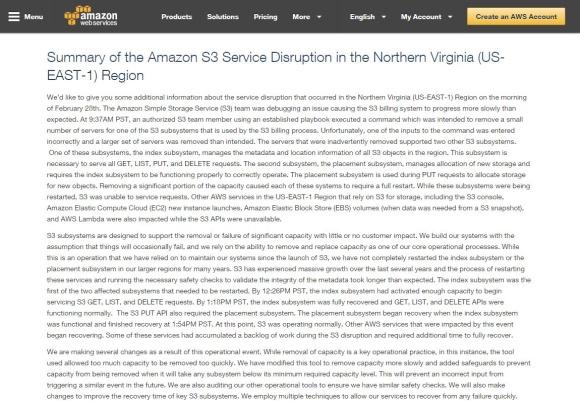
AWSの米国東部リージョン(US-EAST-1、バージニア北部)において2月28日に発生したAmazon S3の障害の原因と対策などについて、AWSが報告を公開しました。
ITジャーナリスト/Publickeyブロガー。大学でUNIXを学び、株式会社アスキーに入社。データベースのテクニカルサポート、月刊アスキーNT編集部 副編集長などを経て1998年退社、フリーランスライターに。2000年、株式会社アットマーク・アイティ設立に参画、オンラインメディア部門の役員として2007年にIPOを実現、2008年に退社。再びフリーランスとして独立し、2009年にブログメディアPublickeyを開始。現在に至る。
Amazon S3がダウンした直接の原因は、Amazon S3課金システムのデバッグ作業中に入力したコマンドのミスによって多数のサーバが削除されたことでした。また、それによって引き起こされたサブシステムの再起動に時間がかかったことが、障害を長引かせる要因になっています。
この記事ではAWSの報告内容を整理し、発生した出来事を時系列でみたあと、障害の背景にあった技術的な要因と対策を紹介します。
コマンドの入力ミスで多数のサーバを削除、復帰にも長時間かかる
そもそもの障害の発端は、Amazon S3課金システムの処理速度が想定よりも遅くなっていたため、Amazon S3チームがデバッグ作業を行っていたことでした。・2月28日 午前9時37分(太平洋標準時)
関連記事
デバッグ作業において、Amazon S3課金プロセスを実行する一部のサブシステムに対して、少数のサーバを削除するコマンド群(原文では「playbook」と表記されているため、AnsibleのPlaybook、あるいは同様に一連のコマンドを記したスクリプトファイルと思われる)を実行。このとき入力されたコマンドの1つに間違いがあり、Amazon S3のメタデータを管理していた「インデックスサブシステム」と、オブジェクトを保存する位置を指定する「配置サブシステム」のサーバ群の大半が削除されてしまいます。
(新野注:原文は「one of the inputs to the command was entered incorrectly」とあり、playbookの内容を間違えたのか、あるいはそれを実行するためのコマンドを間違えたのかは判然としません)
サブシステムはある程度の障害に対する自動回復の能力を備えていましたが、その限界を超えて多数のサーバが削除されてしまったため、それぞれ完全な再起動(フルリスタート)が必要となります。
そこで再起動が実行されました。この2つのサブシステムが完全に復帰するまでAmazon S3の処理が停止。同一リージョン内にはAmazon S3のストレージサービスに依存して稼働するほかのサービス、例えばAmazon EC2、Amazon EBS、AWS Lambdaなど多数のサービスにも影響が出ました。
この再起動とその後の整合性確認の処理には予想以上に時間がかかってしまい、障害が長引く要因となってしまいました。
・12時26分
約3時間後、インデックスサブシステムが十分な能力を発揮するまでに復帰。そこから約50分後の13時18分には完全に正常状態へ復帰。
・13時54分
配置サブシステムも復帰。この時点でようやくAmazon S3が通常動作へ復帰し、影響を受けていたそのほかのサービスも復帰を開始しました。
なにが障害をここまで大きくしたのか?
今すぐビジネス+IT会員にご登録ください。
すべて無料!ビジネスやITに役立つメリット満載!
-
ここでしか見られない
1万本超のオリジナル記事が無料で閲覧可能
-
多角的にニュース理解
各界の専門家がコメンテーターとして活躍中!
-
スグ役立つ会員特典
資料、デモ動画などを無料で閲覧可能!セミナーにご招待
-
レコメンド機能
あなたに合わせた記事表示!メールマガジンで新着通知
関連タグ
関連コンテンツ
あなたの投稿
PR
PR
PR
