- 2026/04/22 20:30 掲載
トヨタ、Woven City AI Vision Engineを発表、世界最高水準の事象予測を実証
カメラ映像から空間内の事象を言語化し高度に理解する独自のAI
トヨタ自動車とウーブン・バイ・トヨタは22日、カメラ映像から空間内の事象を言語化して高精度に理解する独自の人工知能「Woven City AI Vision Engine」を発表した。静岡県裾野市の実証都市「ウーブン・シティ」で社会実装を試行し、動画理解性能で世界最高水準を実現している。同日開設した開発拠点「インベンターガレージ」で報道陣向けに初公開した。

(画像:ビジネス+IT)
■お詫びと訂正[2026/05/07 14:40追加修正]
本記事のタイトルおよび本文、ならびに本文を元に生成AIで作成した図版画像について内容に誤りがありました。また、本文について誤りと誤解を招く表現がありました。今回トヨタ自動車およびウーブン・バイ・トヨタが発表したAIモデル名ついて、正式名称「Woven City AI Vision Engine」のところ「WAVE」と、誤った略称で記述しておりました。また「Woven City Integrated ANZEN System」についても「Woven City 統合安全システム」と誤った記述がされておりました。件名およびに本文、図版は修正済みです。ご迷惑をおかけした読者ならびに関係者にお詫び申し上げます。
件名修正前:トヨタ、動画理解AI「WAVE」を発表
修正後:トヨタ、Woven City AI Vision Engineを発表
リード修正前:人工知能「Woven City AI Vision Engine(WAVE)」を発表した。
リード修正後:人工知能「Woven City AI Vision Engine」を発表した。
本文1修正前:トヨタ自動車が発表したWAVEは
本文1修正後:トヨタ自動車が発表したWoven City AI Vision Engineは、
本文2修正前:「Woven City Integrated ANZEN System(統合安全システム)」を構築した
本文2修正後:「Woven City Integrated ANZEN System」を構築した
図版1修正前:世界最高水準動画AI「ウーブンAI(WAVE)」
図版1修正後:世界最高水準動画AI「Woven City AI Vision Engine」
図版2修正前:Woven City 統合安全システム
図版2修正後:Woven City Integrated ANZEN System
本記事のタイトルおよび本文、ならびに本文を元に生成AIで作成した図版画像について内容に誤りがありました。また、本文について誤りと誤解を招く表現がありました。今回トヨタ自動車およびウーブン・バイ・トヨタが発表したAIモデル名ついて、正式名称「Woven City AI Vision Engine」のところ「WAVE」と、誤った略称で記述しておりました。また「Woven City Integrated ANZEN System」についても「Woven City 統合安全システム」と誤った記述がされておりました。件名およびに本文、図版は修正済みです。ご迷惑をおかけした読者ならびに関係者にお詫び申し上げます。
件名修正前:トヨタ、動画理解AI「WAVE」を発表
修正後:トヨタ、Woven City AI Vision Engineを発表
リード修正前:人工知能「Woven City AI Vision Engine(WAVE)」を発表した。
リード修正後:人工知能「Woven City AI Vision Engine」を発表した。
本文1修正前:トヨタ自動車が発表したWAVEは
本文1修正後:トヨタ自動車が発表したWoven City AI Vision Engineは、
本文2修正前:「Woven City Integrated ANZEN System(統合安全システム)」を構築した
本文2修正後:「Woven City Integrated ANZEN System」を構築した
図版1修正前:世界最高水準動画AI「ウーブンAI(WAVE)」
図版1修正後:世界最高水準動画AI「Woven City AI Vision Engine」
図版2修正前:Woven City 統合安全システム
図版2修正後:Woven City Integrated ANZEN System
トヨタ自動車とウーブン・バイ・トヨタが発表したWoven City AI Vision Engineは、テキスト、画像、動画を統合的に処理するマルチモーダル大規模言語モデルである。街の監視カメラや車載カメラの映像から、時間の経過と空間状況の変化をリアルタイムで言語化し、死角にいる歩行者や対向車の動きを検知して次に起こる事象を予測する。動画理解の性能を評価する世界的ベンチマーク「MVBench」において、73.81%というトップレベルのスコアを獲得した。約80億パラメーターという軽量なモデルサイズでありながら、微細粒度と粗粒度の2段階による独自の階層的圧縮手法を用いることで、長時間の映像でも計算コストの増大や品質劣化を防ぎ、他社の巨大モデルを凌駕する精度を達成している。
トヨタは、Woven City AI Vision Engineと個人の行動特性を予測する「Behavior AI」、ドライバーへの最適な運転支援を行う「Drive Sync Assist」を連携させた「Woven City Integrated ANZEN System(統合安全システム)」を構築した。人間、車、道路インフラの情報を単一のシステムとして融合させ、歩行者の急な飛び出しやスマートフォン操作による注意散漫を事前に察知し、必要に応じた減速や警告、ステアリング補正を同期して実施する。自動運転技術単独に頼るのではなく、インフラを含めた事象の変化の先読みによって危険を能動的に回避し、交通事故ゼロ社会の実現を目指す方針を示した。
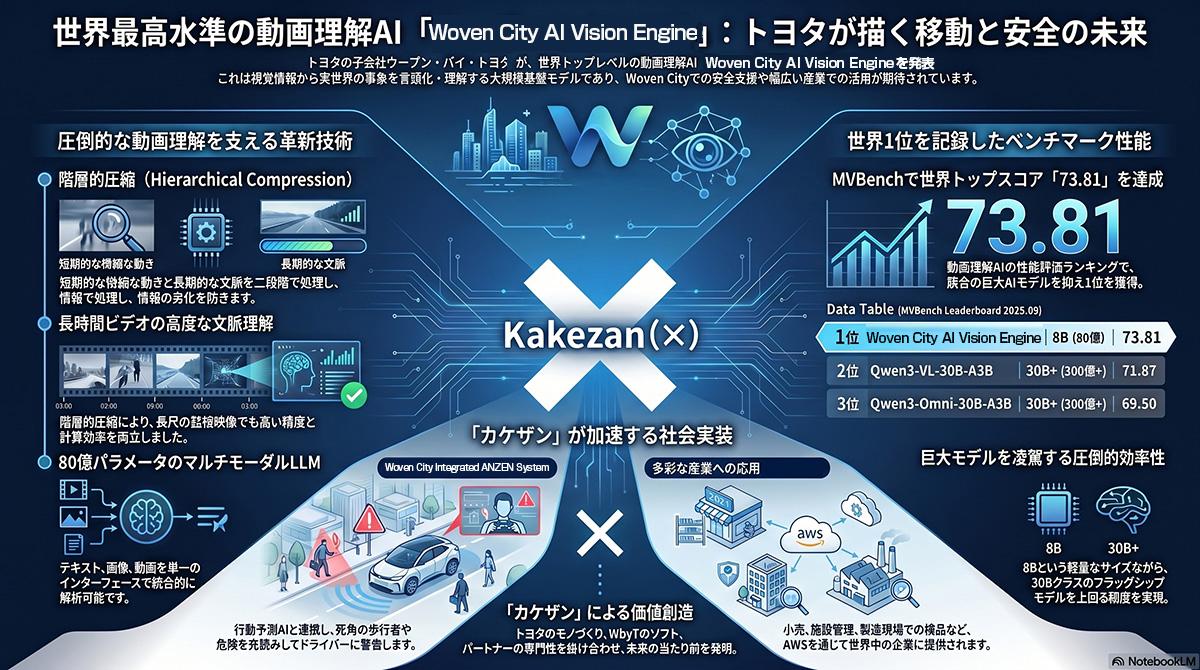
トヨタ自動車とウーブン・バイ・トヨタが世界最高水準の動画理解AI「Woven City AI Vision Engine」発表(図版:ビジネス+IT)
同日の技術説明会では、豊田章男会長の思考や発言を学習した「豊田章男AI」も披露され、モビリティ開発における多様なAIの活用事例が示された。また、ウーブン・シティで新たな製品やサービスを開発する協業パートナー「Inventor」に、第一興商、Joby Aviation、一般社団法人AIロボット協会、トヨタファイナンシャルサービスの4法人が新たに参画したことも併せて発表された。今後は大企業やスタートアップの知見を掛け合わせ、実証実験を通じた実環境でのフィードバックサイクルを回しながら、モビリティエコシステムの構築と社会実装を加速させる。
AI・生成AIのおすすめコンテンツ
Googleで見つけやすく
共有する
-
0
-
0
-
0
-
4
-
1
関連タグ
タグをフォローすると最新情報が表示されます
AI・生成AIの関連コンテンツ
あなたの投稿
PR
PR
PR
