障害はどの部署の責任…? アプリ vs インフラの対立をなくす「実践ノウハウ」
- ありがとうございます!
- いいね!した記事一覧をみる
会員(無料)になると、いいね!でマイページに保存できます。
マルチクラウドやハイブリッドクラウドなど、ITシステムの複雑化が急速に進む現代。多様なAPI連携やサービス呼び出しが絡み合う環境下で、人間がすべてを把握し判断する従来型の運用は、やがて限界を迎えつつある。システム障害時の長引く調査、クラウドコストの最適化を巡る部門間の対立──これらの課題が、IT部門のリソースを奪い、本来のビジネス成長に向けた活動を阻害しているのだ。根本的な解決策をどう見つけるべきか。

(Photo/Shutterstock.com)
複雑化する「ITシステム運用」で直面する実態
企業のITシステムが複雑化する中で、運用現場の課題は深刻さを増している。運用現場でよく見られるのが、「チームのサイロ化」と「情報の偏在」だ。特定の人しか触れない独自ツールやミドルウェアが乱立し、隣のチームがどのような情報を見ているのかすら分からない状況の企業は少なくない。
そうした結果、現場ではどのような問題が起きるのか。象徴的なのが、問題発生時に開設される「ウォールーム」だ。関係者を一斉に集め、ホワイトボードの前に長時間拘束する状況は、多くのIT担当者にとって馴染み深い「あるある」だろう。しかし、それぞれが異なるツールで断片的な情報を持ち寄っても、「調べないと分からない」「聞かないと分からない」ことから、すぐに問題解決につながらず、膨大な時間を費やすことになるのだ。それは問題発生時のみならず、サイロ化したチームでは情報が偏在し、それぞれが独自の基準を持っている場合が多いため、さまざまな壁にぶち当たることが多い。
具体的に、現場を停滞させている代表的な「2つの困りごと」を見ていこう。1つ目は「リソース最適化」の壁だ。リーダーから「クラウドコストが高止まりしているから、なんとかしてほしい」と指示を受けた担当者は、人力で対象のリソースリストを作成し、システムの運用チームにリソース変更を依頼する。しかし、システムのチームからは「その根拠は何か」「システム影響はないのか」と問い詰められ、担当者は板挟みになってしまう。結局、最適化の判断が難しく、属人的な対応に終始することになる。
2つ目は「トラブル対応の不毛なループ」だ。システムトラブルが発生した際、アプリチームはさまざまな監視ツールを駆使して調査を行い、「インフラの問題だ」と結論づけてインフラチームに調査を依頼する。しかし、異なるツールを使っているインフラチームは「インフラの異常はない。アプリの問題だ」と突き返す。互いに自領域の問題ではないと主張し、画面や情報源が分散しているため、原因の切り分けだけで時間が経過していくというものだ。
こうした「人力での調査」や「分断された監視ツール」といった既存のアプローチでは、複雑化したシステムの運用はもはや限界に達している。では、この八方塞がりの状況を打破し、運用チームの不毛な対立を解消する落としどころはどこにあるのか。
そうした結果、現場ではどのような問題が起きるのか。象徴的なのが、問題発生時に開設される「ウォールーム」だ。関係者を一斉に集め、ホワイトボードの前に長時間拘束する状況は、多くのIT担当者にとって馴染み深い「あるある」だろう。しかし、それぞれが異なるツールで断片的な情報を持ち寄っても、「調べないと分からない」「聞かないと分からない」ことから、すぐに問題解決につながらず、膨大な時間を費やすことになるのだ。それは問題発生時のみならず、サイロ化したチームでは情報が偏在し、それぞれが独自の基準を持っている場合が多いため、さまざまな壁にぶち当たることが多い。
具体的に、現場を停滞させている代表的な「2つの困りごと」を見ていこう。1つ目は「リソース最適化」の壁だ。リーダーから「クラウドコストが高止まりしているから、なんとかしてほしい」と指示を受けた担当者は、人力で対象のリソースリストを作成し、システムの運用チームにリソース変更を依頼する。しかし、システムのチームからは「その根拠は何か」「システム影響はないのか」と問い詰められ、担当者は板挟みになってしまう。結局、最適化の判断が難しく、属人的な対応に終始することになる。
2つ目は「トラブル対応の不毛なループ」だ。システムトラブルが発生した際、アプリチームはさまざまな監視ツールを駆使して調査を行い、「インフラの問題だ」と結論づけてインフラチームに調査を依頼する。しかし、異なるツールを使っているインフラチームは「インフラの異常はない。アプリの問題だ」と突き返す。互いに自領域の問題ではないと主張し、画面や情報源が分散しているため、原因の切り分けだけで時間が経過していくというものだ。
こうした「人力での調査」や「分断された監視ツール」といった既存のアプローチでは、複雑化したシステムの運用はもはや限界に達している。では、この八方塞がりの状況を打破し、運用チームの不毛な対立を解消する落としどころはどこにあるのか。
属人化からの脱却…部門間の対立をなくす「データの統一基準」とは
運用現場の停滞を引き起こす本当の課題は、担当者のスキル不足やコミュニケーションの欠如ではない。「データに基づく統一基準がないこと」と「環境横断でプロセスが確立されていないこと」にある。
日本アイ・ビー・エム テクノロジー事業本部 オートメーション・テクニカル・スペシャリストの浦野祐紀氏は、「システムが密接に関連し合う中で、チームはサイロ化し、情報が偏在する状況になりがちです」と指摘する。

日本アイ・ビー・エム
テクノロジー事業本部
オートメーション・テクニカル・スペシャリスト
浦野祐紀 氏
リソースの最適化において真に必要なのは、人力による根拠の薄いリスト化ではなく、「複雑な環境でも統一基準で、数値根拠を用いて最適化判断ができる」プロセスだ。また、トラブルシューティングにおいては、ツールを跨いだ伝言ゲームではなく、「アプリ・インフラの両チームが統合された共通画面を用い、チーム横断で同じ情報を見ながら迅速に状況共有できる環境」が不可欠となる。
これらを実現するためには、環境横断でシステム全体の状況をリアルタイムに把握する「可観測性(オブザーバビリティ)」と、膨大なデータから最適なアクションを導き出す、自動化された分析・判断の仕組みが不可欠である。
浦野氏は、「人間が目視で限界を感じる領域を高度な分析による知見と自動化ツールで支援するフルスタックで自動化された可観測性こそが、IT運用をあるべき姿へと導くと考えます」と強調する。
日本アイ・ビー・エム テクノロジー事業本部 オートメーション・テクニカル・スペシャリストの浦野祐紀氏は、「システムが密接に関連し合う中で、チームはサイロ化し、情報が偏在する状況になりがちです」と指摘する。
テクノロジー事業本部
オートメーション・テクニカル・スペシャリスト
浦野祐紀 氏
リソースの最適化において真に必要なのは、人力による根拠の薄いリスト化ではなく、「複雑な環境でも統一基準で、数値根拠を用いて最適化判断ができる」プロセスだ。また、トラブルシューティングにおいては、ツールを跨いだ伝言ゲームではなく、「アプリ・インフラの両チームが統合された共通画面を用い、チーム横断で同じ情報を見ながら迅速に状況共有できる環境」が不可欠となる。
これらを実現するためには、環境横断でシステム全体の状況をリアルタイムに把握する「可観測性(オブザーバビリティ)」と、膨大なデータから最適なアクションを導き出す、自動化された分析・判断の仕組みが不可欠である。
浦野氏は、「人間が目視で限界を感じる領域を高度な分析による知見と自動化ツールで支援するフルスタックで自動化された可観測性こそが、IT運用をあるべき姿へと導くと考えます」と強調する。
トラブル原因を瞬時に特定? IBMが誇る“2つの運用高度化ツール”
この課題に対して、IBMは「困った時に導いてくれる」2つの強力なソリューションを提供している。リソースの継続的最適化を担う「IBM Turbonomic」と、システムの健康状態を可視化する「IBM Instana」だ。
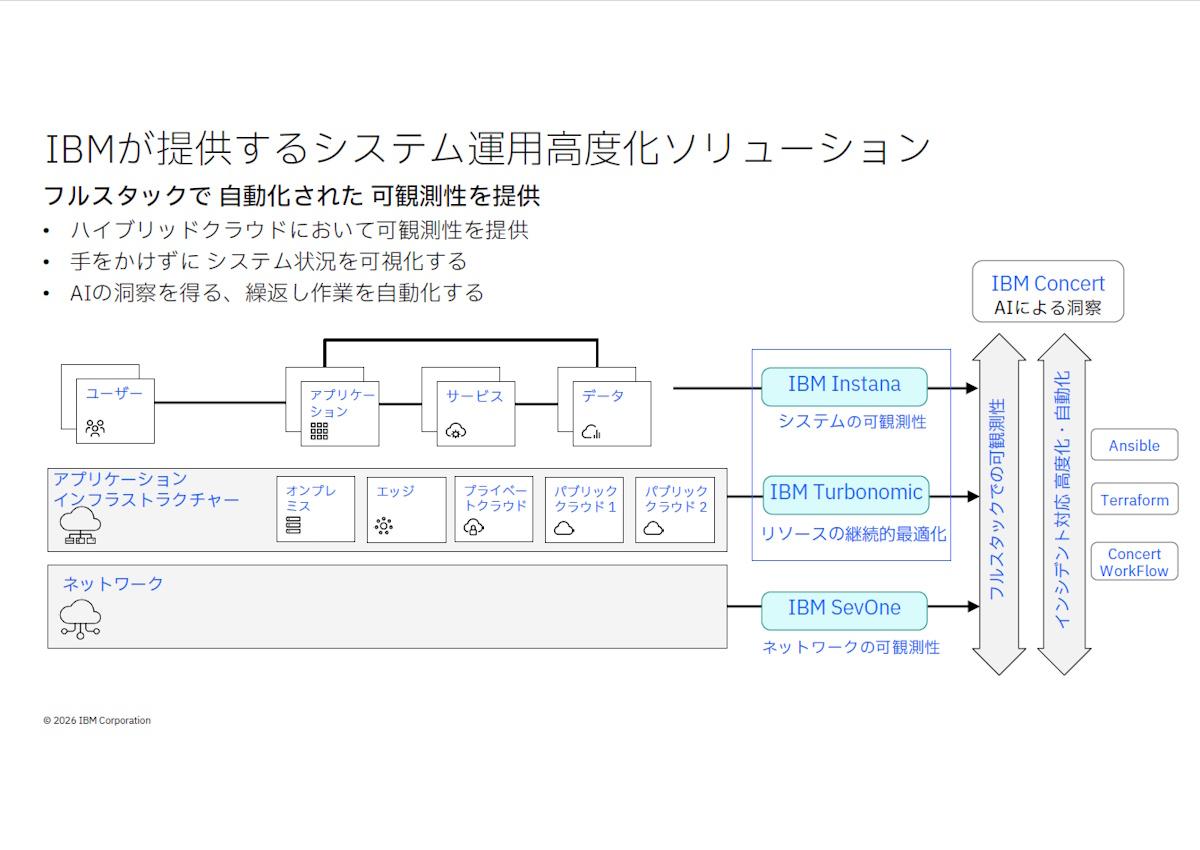
IBMが提供するシステム運用高度化ソリューション
第1に、リソース最適化の司令塔となる「IBM Turbonomic」は、マルチクラウドやハイブリッドクラウド環境において、アプリケーションのパフォーマンスを保証しつつ、コストを最小化する役割を果たす。Turbonomicは、「ITリソース使用状況の可視化」「リソース最適化の推奨アクションの生成」「推奨アクションの実行・自動化」という3つのステップでリソースを継続的に最適化する。
ここで重要なのは「Slow is new Down(ユーザー体験を損なう遅延はダウンと同義である)」という思想だ。Turbonomicは単なるコスト削減ツールではない。不要なリソース(EBSボリュームなど)の削除や、最適なインスタンスへの変更によるコストダウンを提案するだけでなく、性能劣化が疑われる場合にはパフォーマンス向上のためのリソース増強も提案する。
さらに、Turbonomicの最大の強みは、推奨アクションの生成条件が「ホワイトボックス」であることだ。なぜそのアクションが必要なのか、集計期間やパーセントタイルを用いた閾値などの条件を管理者がきめ細かく設定でき、ロジックが明確なため、「どのリソースをどう変えるべきか」を数値根拠で説明できる。
これにより、これまで「根拠は何か」と反発していたチーム間の合意形成が極めてスムーズになる。また、従量課金であるパブリッククラウドのリソースを対象に、平日日中のみ仮想マシンを稼働させ、夜間・休日は自動停止させるといったスケジューリング機能も備えており、検証環境などのコスト削減にも絶大な効果を発揮する。
第2に、トラブルシュートの診断医となる「IBM Instana」は、インフラからアプリケーションまでフルスタックでシステムを可視化し、原因究明を劇的に加速させる。
Instanaの魅力は、その導入と運用のシンプルさにある。Linux環境であればワンライナーのコマンドでエージェントをインストールするだけで、OS、コンテナ、ミドルウェア、アプリケーションといった動作する技術スタックを自動的に検知し、依存関係をマップ化する。
さらに、アプリケーションリクエストをトレースし、処理数、エラー率、応答性能といった「ゴールデンシグナル」を自動的に可視化する。Instanaはこれらのメトリクスを継続的に学習することで、動的なしきい値を設定することができる。それにより、「突然処理数が減った」「エラーが増えた」といった普段と異なる挙動(未知の異常)を即座に検知し、アラートを発報する。
万が一エラーが発生した際にも、直感的なドリルダウン操作によって、エラーの詳細やログ、スタックトレースを瞬時に特定可能だ。アプリチームとインフラチームが共通の画面で同じ情報(ゴールデンシグナルやエラートレース)を見ながら調査できるため、「あちらの問題だ」という不毛な責任の押し付け合いがなくなり、平均復旧時間(MTTR)を大幅に短縮できる。
第1に、リソース最適化の司令塔となる「IBM Turbonomic」は、マルチクラウドやハイブリッドクラウド環境において、アプリケーションのパフォーマンスを保証しつつ、コストを最小化する役割を果たす。Turbonomicは、「ITリソース使用状況の可視化」「リソース最適化の推奨アクションの生成」「推奨アクションの実行・自動化」という3つのステップでリソースを継続的に最適化する。
ここで重要なのは「Slow is new Down(ユーザー体験を損なう遅延はダウンと同義である)」という思想だ。Turbonomicは単なるコスト削減ツールではない。不要なリソース(EBSボリュームなど)の削除や、最適なインスタンスへの変更によるコストダウンを提案するだけでなく、性能劣化が疑われる場合にはパフォーマンス向上のためのリソース増強も提案する。
さらに、Turbonomicの最大の強みは、推奨アクションの生成条件が「ホワイトボックス」であることだ。なぜそのアクションが必要なのか、集計期間やパーセントタイルを用いた閾値などの条件を管理者がきめ細かく設定でき、ロジックが明確なため、「どのリソースをどう変えるべきか」を数値根拠で説明できる。
これにより、これまで「根拠は何か」と反発していたチーム間の合意形成が極めてスムーズになる。また、従量課金であるパブリッククラウドのリソースを対象に、平日日中のみ仮想マシンを稼働させ、夜間・休日は自動停止させるといったスケジューリング機能も備えており、検証環境などのコスト削減にも絶大な効果を発揮する。
第2に、トラブルシュートの診断医となる「IBM Instana」は、インフラからアプリケーションまでフルスタックでシステムを可視化し、原因究明を劇的に加速させる。
Instanaの魅力は、その導入と運用のシンプルさにある。Linux環境であればワンライナーのコマンドでエージェントをインストールするだけで、OS、コンテナ、ミドルウェア、アプリケーションといった動作する技術スタックを自動的に検知し、依存関係をマップ化する。
さらに、アプリケーションリクエストをトレースし、処理数、エラー率、応答性能といった「ゴールデンシグナル」を自動的に可視化する。Instanaはこれらのメトリクスを継続的に学習することで、動的なしきい値を設定することができる。それにより、「突然処理数が減った」「エラーが増えた」といった普段と異なる挙動(未知の異常)を即座に検知し、アラートを発報する。
万が一エラーが発生した際にも、直感的なドリルダウン操作によって、エラーの詳細やログ、スタックトレースを瞬時に特定可能だ。アプリチームとインフラチームが共通の画面で同じ情報(ゴールデンシグナルやエラートレース)を見ながら調査できるため、「あちらの問題だ」という不毛な責任の押し付け合いがなくなり、平均復旧時間(MTTR)を大幅に短縮できる。
強制力と納得感を両立する運用ルールの策定と、未来への展望
これらのソリューションは、実際の現場でどのように機能するのか。ある企業では、再起動を伴う仮想マシンの最適化アクションの実行に、システム運用側が躊躇するという課題があった。そこでTurbonomicを導入し、「3カ月放置された推奨アクションは、定期メンテナンス時に自動実行する」という運用ルールを策定した。
浦野氏は、「Turbonomicの提案は事前に協議された99パーセンタイルなどのホワイトボックスなロジックであり、パフォーマンス改善も含まれる。このため、運用部門とユーザー部門の双方が納得(Win-Winの合意形成)した運用ができ、見事クラウドコストの削減に成功しました」と事例の成果を振り返る。
また、複雑なバンキングシステムにおいて、想定外の大量アクセスによる高負荷障害が発生したケースでも、Instanaが威力を発揮した。従来の5~10分間隔のサンプリング監視では捉えきれなかった瞬間的な問題を、Instanaの1秒間隔の詳細監視と依存関係の自動可視化がカバー。多様な技術を自動検出し、根本原因をリアルタイムに分析することで、早期の問題解決を実現したのだ。
「困った時に導いてくれる」パートナーとしてのソリューションの導入は、IT運用が直面する限界を突破する第一歩である。TurbonomicやInstanaを活用してデータに基づく統一基準を設け、システムの状況をフルスタックで可視化することで、現場のエンジニアは「調べる作業」や「責任の押し付け合い」から解放される。
システムの高度化・自動化の先には、IBM ConcertのようなAIによるさらなる洞察と、Ansibleなどの構成管理ツールを組み合わせた自動化の加速が待っている。デジタル変革が加速する今、属人的で疲弊する運用から脱却し、AI主導の可観測性を中核とした「新しい運用の世界」へ足を踏み入れるべき時が来ているのだ。
浦野氏は、「Turbonomicの提案は事前に協議された99パーセンタイルなどのホワイトボックスなロジックであり、パフォーマンス改善も含まれる。このため、運用部門とユーザー部門の双方が納得(Win-Winの合意形成)した運用ができ、見事クラウドコストの削減に成功しました」と事例の成果を振り返る。
また、複雑なバンキングシステムにおいて、想定外の大量アクセスによる高負荷障害が発生したケースでも、Instanaが威力を発揮した。従来の5~10分間隔のサンプリング監視では捉えきれなかった瞬間的な問題を、Instanaの1秒間隔の詳細監視と依存関係の自動可視化がカバー。多様な技術を自動検出し、根本原因をリアルタイムに分析することで、早期の問題解決を実現したのだ。
「困った時に導いてくれる」パートナーとしてのソリューションの導入は、IT運用が直面する限界を突破する第一歩である。TurbonomicやInstanaを活用してデータに基づく統一基準を設け、システムの状況をフルスタックで可視化することで、現場のエンジニアは「調べる作業」や「責任の押し付け合い」から解放される。
システムの高度化・自動化の先には、IBM ConcertのようなAIによるさらなる洞察と、Ansibleなどの構成管理ツールを組み合わせた自動化の加速が待っている。デジタル変革が加速する今、属人的で疲弊する運用から脱却し、AI主導の可観測性を中核とした「新しい運用の世界」へ足を踏み入れるべき時が来ているのだ。
・関連ソリューション(Instana)
https://www.ibm.com/jp-ja/products/instana
・お問い合わせ
https://www.ibm.com/jp-ja/forms/mkt-mail-automation
https://www.ibm.com/jp-ja/products/instana
・お問い合わせ
https://www.ibm.com/jp-ja/forms/mkt-mail-automation
関連タグ
タグをフォローすると最新情報が表示されます
