- 会員限定
- 2024/08/16 掲載
データファブリックとは何か?ガートナー解説するAI時代のデータ管理術
生成AIの能力を最大限使いこなすために重要となるデータ活用。そのデータ活用をより効果的に行うために注目されいるのが「データ・ファブリック」と呼ばれるデータ管理のアプローチだ。データ・ファブリックとは具体的にどんなアプローチで、導入によりどんな効果が出るのか。「データカタログ」「ナレッジグラフ」「データ統合」「DataOps」領域で優れた評価を得た具体的なベンダーなどについてガートナーのエティシャム・ザイディ氏が解説する。
(出典:ガートナー(2024年5月))
データ・ファブリックとは何か?新しいデータ管理のアプローチ
データ活用高度化の歴史はデータ管理の進化の歴史でもある。データウェアハウス(DWH)の登場により企業でデータ活用が本格化した2000年代当時、分析用データの“器”はDWH以外にデータマートなど社内に複数存在することが一般的だった。その後、2010年代に入って広がったのが、いわばデータを事前分類したセマンティック・レイヤを介して、各データソースから必要なデータへのアクセスを実現するデータ仮想化だ。
このデータ仮想化について、「従来からの異なるデータソースに起因する『真実が複数ある』問題が解消されました」と語るのは、ガートナー バイス プレジデント, アナリストのエティシャム・ザイディ氏だ。

バイス プレジデント, アナリスト
エティシャム・ザイディ氏
ただザイディ氏は、データ仮想化で上記の問題が解決したとは言え、いまだにアナリティクスデータとオペレーションデータの統合までには至っていないという課題が存在すると指摘する。
そうした状況の中で、新たなデータ管理のアプローチとして企業の関心を集めているのが「データ・ファブリック」だ。
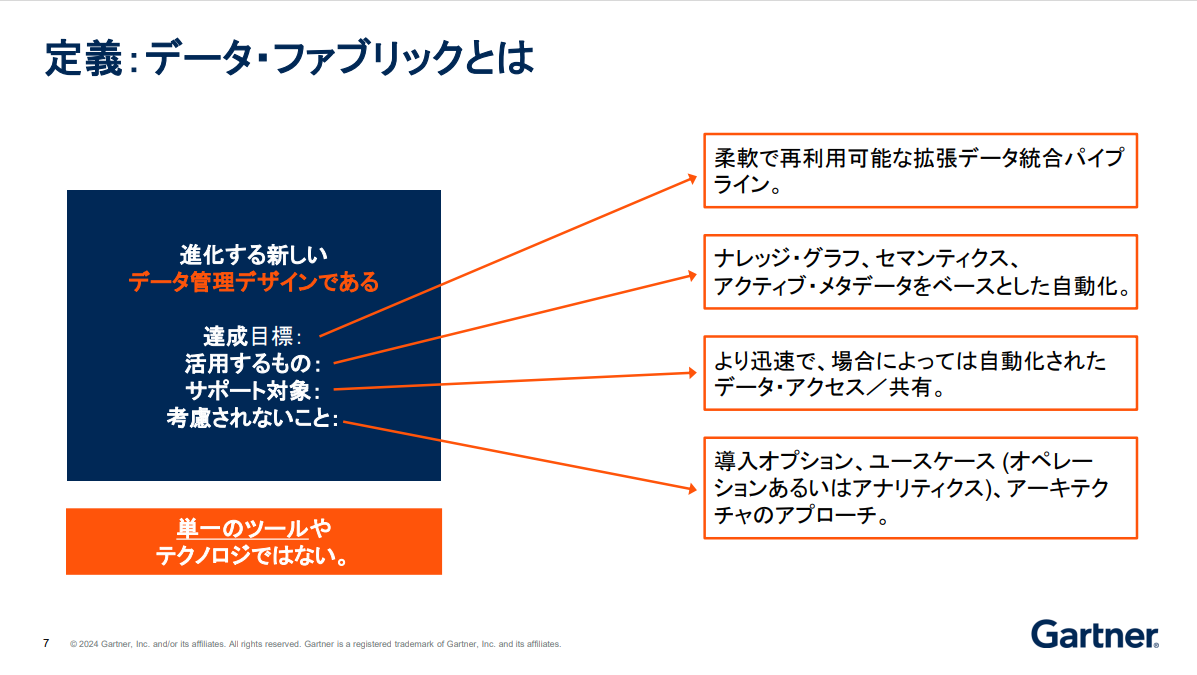
データファブリックとは、ツールやプラットフォームを意味するのではなく、「再利用可能な自動化データ統合パイプラインを実現するデータ管理デザイン」というのがガートナーの定義だ。簡単にいえば、企業内外にあるデータを最適な場所に配置し、必要に応じて取り出せる状態にするデータ管理手法のこと。その一番の特徴としては、ナレッジ・グラフやセマンティクスによるデータの関連性や意味の把握に基づくレコメンデーションや、アクティブ・メタデータによるデータ統合の自動化が挙げられる。
このデータファブリックが注目されるのは、データ統合の難しさがAIの活用を阻んでいる現状があるからだ。
「データファブリックは、オンプレやクラウドなど環境を問わず実装でき、データの保管場所は問いません。ひいては、企業全体でのデータ共有を実現します。加えて、データの場所はもちろん、統合のための変換方法などもレコメンドし、データの準備時間を抜本的に短縮します」(ザイディ)
では、データファブリックを実装するためには何が必要になるのだろうか。
データ利用の改善率は「4倍」に?
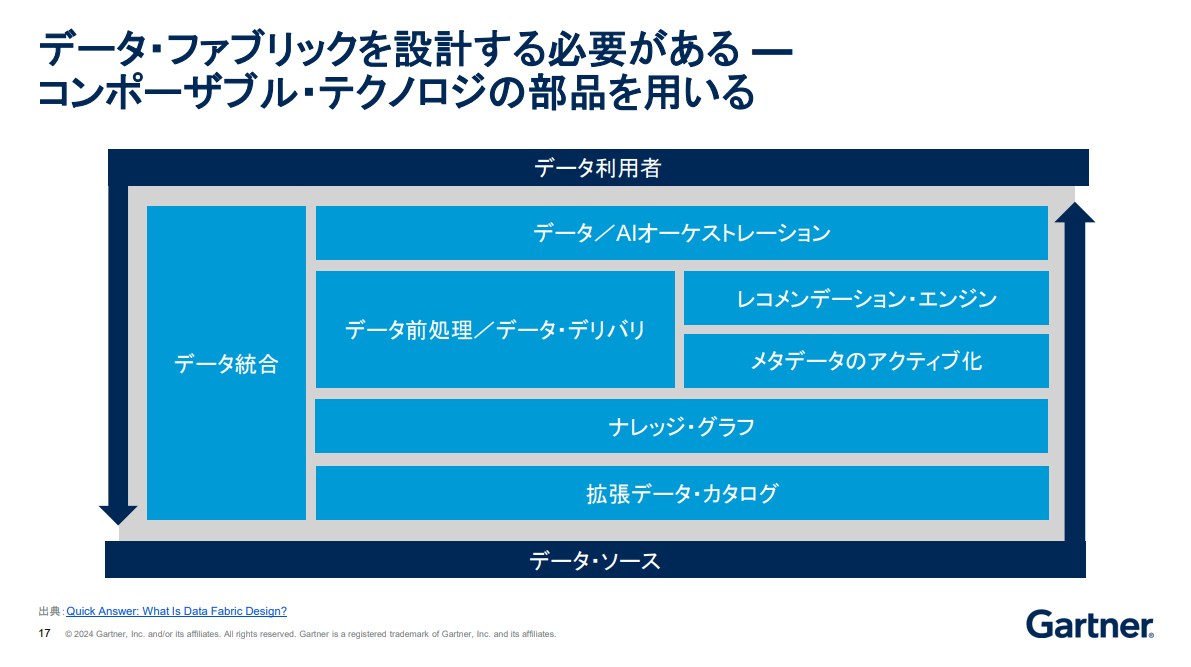
ガートナーのレポートでは、データファブリックの整備によってデータ設計や統合、品質/マスタリングのための労力は5年までに3~4割削減され、データ利用の改善率も4倍に高まると試算されている。データファブリック構築に必要とされる技術要素は多岐にわたるが、そのすべてを一度に整備する必要はなく、コンポーザブルなテクノロジー部品により順次揃えていくのが基本的なアプローチだ。
(出典:ガートナー(2024年5月))
そこでの最初の導入機能として挙がるのが、すでに市販されている拡張データカタログである。
「メタデータはデータの可視化で鍵を握り、拡張データカタログによるメタデータ収集により、ビジネス側の社内データに対するセマンティックな検索がまずは可能になります」(ザイディ氏) 【次ページ】AIの「ハルネーション抑制」も担う「ある技術」とは
データ戦略のおすすめコンテンツ
関連タグ
タグをフォローすると最新情報が表示されます
あなたの投稿
PR
PR
PR
