- 会員限定
- 2026/02/04 掲載
Google、「Gemini 3 Flash」に高精度な画像分析機能「Agentic Vision」を追加
人が画像を確認する際にズームインするように、AIが自律的に対象を検査することが可能に
Googleは2026年1月27日、生成AIモデル「Gemini 3 Flash」に新たな画像分析機能「Agentic Vision」を追加したと発表した。従来の一回限りの画像読み取りとは異なり、AIが自らPythonコードを実行して画像の拡大や注釈付けを行い、細部を能動的に再検査する仕組みを導入した。この「思考、実行、観察」のループにより、視覚ベンチマークにおいて品質が5~10%向上したとしている。

(画像:Google)
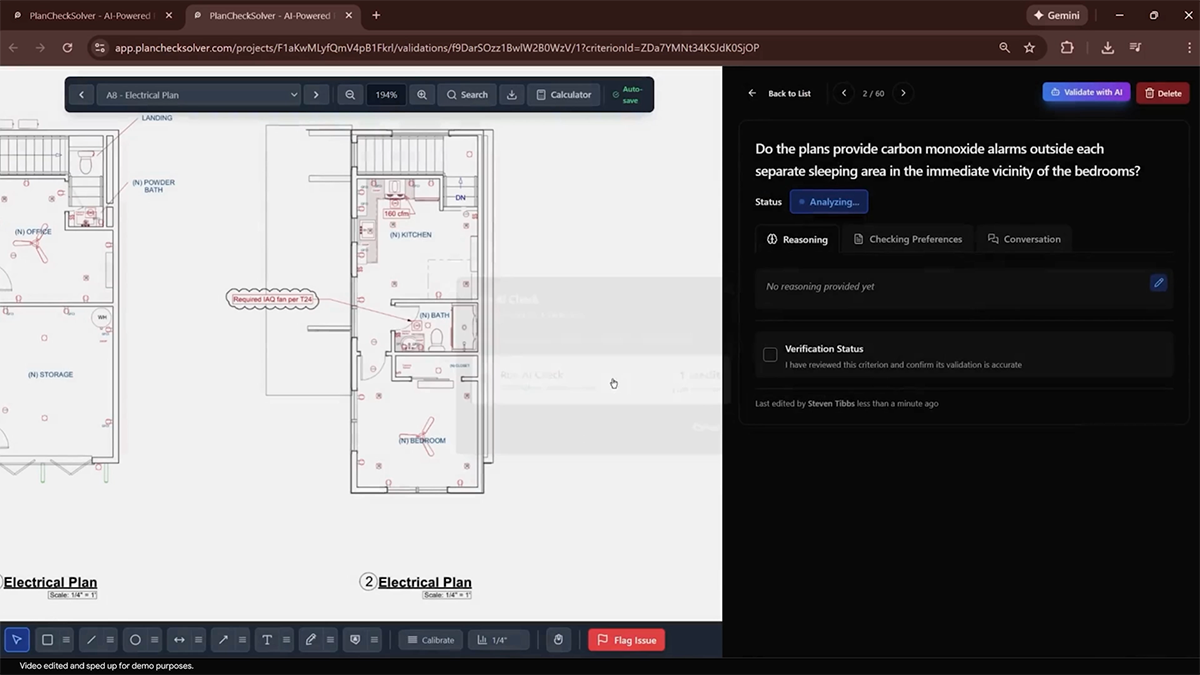
画像を自動でズームして細部を確認する
(画像:Google)
Agentic Visionでは画像を精査するため「Think(思考)、Act(実行)、Observe(観察)」というループ処理を行う。AIモデルはまずユーザーの指示と画像を分析し(Think)、Pythonコードを生成・実行して画像の切り出し、回転、注釈付け、計算などを行う(Act)。その結果得られた新しい画像の情報はAIモデルのコンテキストに追加され、より詳細な情報に基づいて最終的な画像についての回答が生成される(Observe)。このプロセスにより、人間が画像の詳細を確認するためにズームインするように、AIが自律的に対象を検査することが可能となった。
具体的な活用例として、Googleは「視覚的なスクラッチパッド(メモ帳)」としての利用を挙げている。例えば、画像内の物体の数を数えるタスクにおいて、AIは認識した対象一つひとつに境界線や番号を描画し、視覚的にマーキングを行うことで、数え間違いや重複を防止する。また、建築図面の検証などの高解像度画像を用いるケースでは、特定のセクションを切り出して反復的に検査することで、複雑な基準への適合性を確認できるとしている。さらに、高密度な表データを解析し、Python環境で決定論的な計算を行うことで、グラフ描画などの視覚化タスクにおけるハルシネーション(もっともらしい誤り)を低減させることも可能である。
Googleによると、このコード実行機能の有効化により、主要な視覚ベンチマーク全体で一貫して5~10%の品質向上が確認された。Agentic Visionは現在、Google AI StudioおよびVertex AIのGemini APIを通じて利用可能であり、Geminiアプリにおいても順次展開が開始されている。同社は今後、ウェブ検索や逆画像検索といったツールの統合や、Flash以外のモデルサイズへの機能拡大も計画している。
AI・生成AIのおすすめコンテンツ
Googleで見つけやすく
共有する
-
1
-
2
-
0
-
0
-
0
関連タグ
タグをフォローすると最新情報が表示されます
AI・生成AIの関連コンテンツ
あなたの投稿
PR
PR
PR
