- 2021/03/16 12:57 掲載
NTTデータ、業務領域特有の用語や文脈を理解する言語モデルの提供体制確立
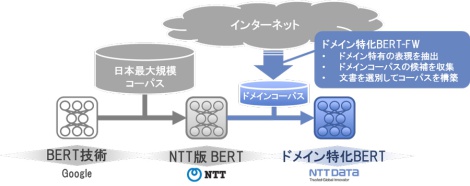
本FWの利用により、NTTデータは業界を限定しないさまざまなドメインに特化したBERTを短期間で構築し、お客さまに高性能な言語処理サービスを素早く提供できるようになりました。
本FWは、専門用語や特有の文脈を含む文書を解析する際に、言語モデル自体をお客さまの業務文書に最適化することで従来のBERTと比べて高精度の結果を得ることができます。また、言語モデル構築の一連の流れは自動化されているため、専門家によるチューニングを行う場合と比べて短期間でモデルを構築することが可能です。
本FWの適用により、専門用語や特有の文脈への対応が必要だった分野での自然言語処理技術活用の幅が大きく広がることを見込んでいます。2021年4月以降順次、文書を扱う業務の効率化やサービスの高度化を検討している企業を募り、2021年度中にお客さまとの共同検証の5件実施を目指します。
■背景
近年、深層学習をはじめとしたAI技術が目覚ましい進歩を遂げており、自然言語処理技術のビジネス適用も進んでいます。BERTの活用も盛んに試行されていますが、実ビジネスで取り扱う文書では業界特有の専門性の高い用語や言い回しが多く、これらの要因により十分な精度が得られないことが課題となっていました。これに対して、NTTデータでは金融業界文書に特化した金融版BERTを開発し、2020年7月より実施している金融業界向けの自然言語処理の実証実験において活用しています。こうした業界特化の言語モデルは金融業界以外のお客さまにおいても高いニーズがあります。それらに迅速に応えるため、お客さまの業務データごとに適した追加学習データを自動収集する仕組みであるドメイン特化BERT-FWを開発しました。
共有する
-
0
-
0
-
0
-
0
-
0
関連タグ
タグをフォローすると最新情報が表示されます
あなたの投稿
PR
PR
PR
