- 2026/05/08 掲載
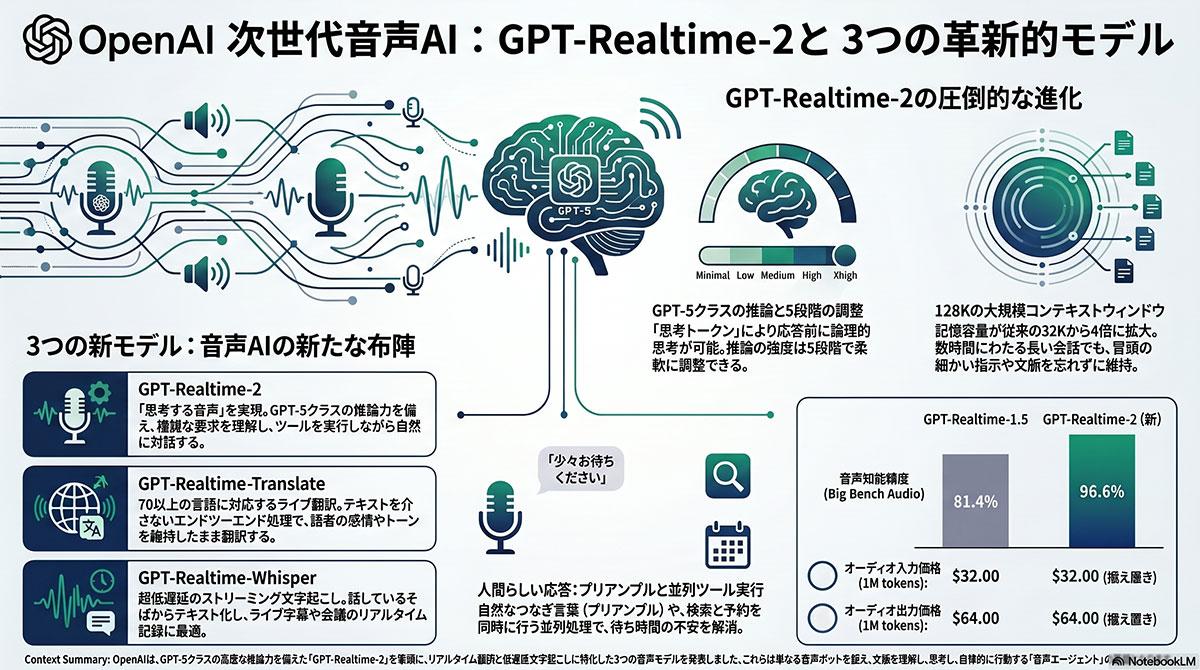
OpenAI、GPT-5クラスの推論力を備えた音声モデル「GPT-Realtime-2」など3種を公開
最大12万8000トークンのコンテクストウインドウに対応
米OpenAIは2026年5月7日、リアルタイムAPI向けに新たな音声特化型AIモデル3種を公開した。GPT-5クラスの推論能力を持つ主力の「GPT-Realtime-2」に加え、リアルタイム翻訳に特化した「GPT-Realtime-Translate」、低遅延で文字起こしを行う「GPT-Realtime-Whisper」を提供する。音声処理における遅延や文脈理解の課題を解消する。

(画像:ビジネス+IT)
あわせて公開した「GPT-Realtime-Translate」は、70以上の言語の音声をリアルタイムで双方向に翻訳し、13の言語で直接音声出力する。生の音声をエンドツーエンドで処理する手法を採用し、話者の声のトーンや感情のニュアンスを維持したまま翻訳内容を伝える。人間の同時通訳と比較して運用費用を抑え、1分あたり約0.034ドルで提供する。「GPT-Realtime-Whisper」は、発話と同時に文字起こしを実行する低遅延のストリーミングモデルであり、会議の記録作成や業務フローの自動化に利用する。これら3つのモデルはすべてOpenAIのリアルタイムAPI経由で開発者向けに提供を開始した。
OpenAIがGPT-5クラスの推論力を持つ音声AIモデル「GPT-Realtime-2」など3種発表
(図版:ビジネス+IT)
これまでの音声AIプラットフォームは、ユーザーの発話をテキストに変換し、言語モデルで処理した後に再び音声へ変換するカスケード型構成が主流であった。この手法は処理過程での情報の欠落や遅延の蓄積が避けられなかった。新モデル群は音声をネイティブに処理するマルチモーダル基盤を利用し、情報伝達の速度と正確性を向上させている。
不動産情報のZillowや旅行予約のPriceline、通信大手のDeutsche Telekomなどがカスタマーサポートや多言語コミュニケーションの分野でこれらのモデルのテスト運用を開始した。顧客対応においてキーボード入力に依存せず、口頭のみで手続きを完結させるエージェントの開発が進んでいる。
AI・生成AIのおすすめコンテンツ
Googleで見つけやすく
共有する
-
0
-
1
-
0
-
0
-
0
関連タグ
タグをフォローすると最新情報が表示されます
AI・生成AIの関連コンテンツ
あなたの投稿
PR
PR
PR
