- 2026/04/04 掲載
グーグル、エージェント特化のAIオープンモデル「Gemma 4」公開
高度な推論を必要とするエージェント型ワークフローに最適化
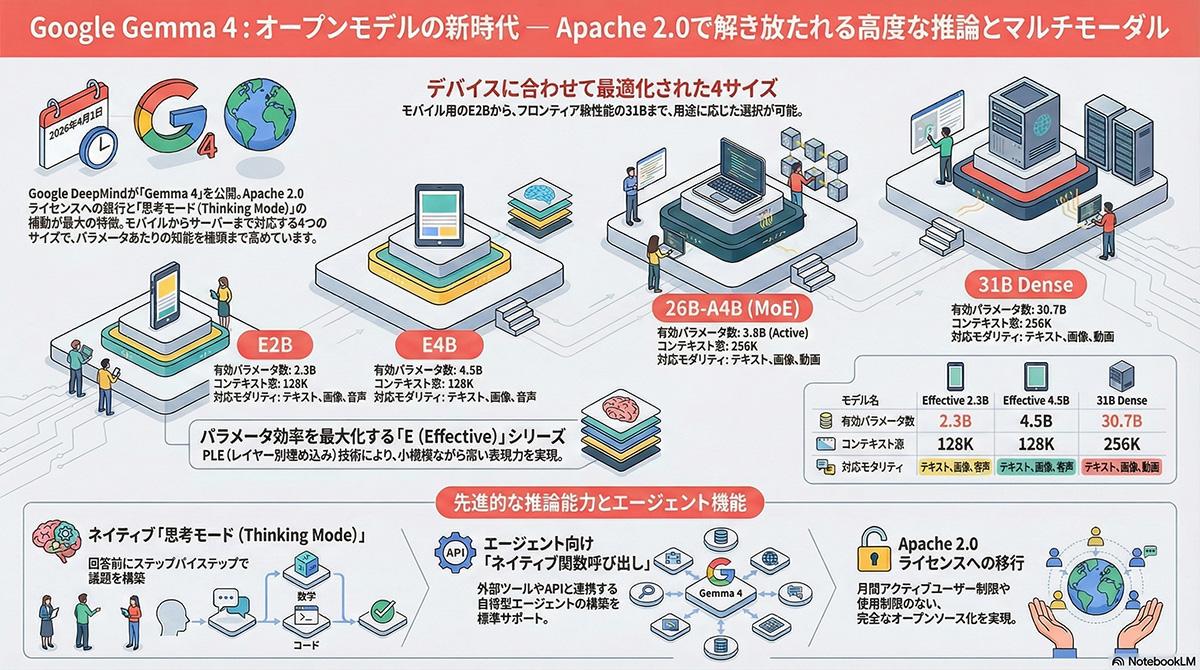
米Googleは2026年4月2日(現地時間)、高度な推論やエージェント型のワークフローに特化したオープンモデル「Gemma 4」を公開した。Gemmaシリーズとして初めて商用利用の制限が少ないApache 2.0ライセンスを採用した。テキスト、画像、動画に加え、音声入力をネイティブでサポートする。

(画像:ビジネス+IT)
提供されるモデルは、モバイル端末やIoTデバイスでのエッジ推論に向けてメモリ効率を最大化した「E2B(Effective 2B)」および「E4B」、小規模なワークステーションやPC上で高速な推論を実現する「26B MoE(Mixture of Experts)」、ファインチューニングの基盤となる「31B Dense」の4種類である。26B MoEモデルは推論時に約40億パラメータのみをアクティブにするスパースアーキテクチャを採用しており、小規模モデルと同等の推論コストで大規模モデルの品質を実現する。全モデル共通で256Kトークンのコンテキストウィンドウを備え、140以上の言語に対応している。
グーグル、エージェント特化のオープンモデルAI「Gemma4」公開
(図版:ビジネス+IT)
入力データとして、従来のテキスト、画像、動画に加えて、新たに音声データを処理するマルチモーダル機能を搭載した。複雑なタスクに対して最終的な回答を出力する前に推論プロセスを生成する「思考モード(Thinking mode)」も組み込まれており、開発者はシステム命令を通じて思考の深さや効率を調整できる。
ハードウェアへの最適化も同時に進められている。NVIDIAはGemma 4を自社のGPU向けに最適化し、RTX搭載PCやエッジデバイス向けのJetson Orin Nano、新たなデータセンター向け環境であるDGX SparkでローカルAIエージェントを実行できる環境を整えた。AMDもプロセッサおよびGPUにおけるGemma 4のサポートを発表している。加えて、GoogleはAndroidの「AICore Developer Preview」を通じてGemma 4のアーリーアクセスを開始した。現在Gemma 4向けに開発されたコードは、年内に登場予定の「Gemini Nano 4」搭載端末においても自動的に動作する見込みである。
AI・生成AIのおすすめコンテンツ
Googleで見つけやすく
共有する
-
0
-
1
-
0
-
0
-
0
関連タグ
タグをフォローすると最新情報が表示されます
AI・生成AIの関連コンテンツ
あなたの投稿
PR
PR
PR
