- 2026/05/20 掲載
Googleが動画版ナノバナナ「Gemini Omni」を発表、対話で動画を生成する時代へ
マルチモーダルで対話形式で動画の生成や編集を行う機能
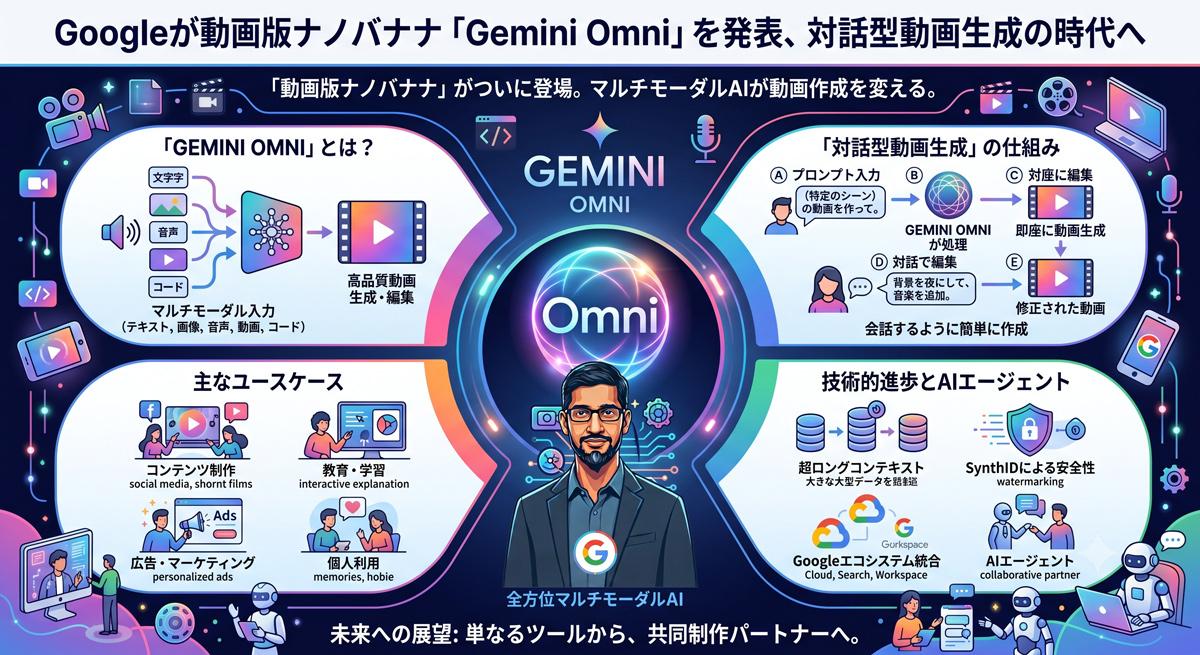
米グーグル(Google)は2026年5月19日、年次開発者会議「Google I/O」において、新たなAIモデル「Gemini Omni」を発表した。同モデルはテキストや画像、音声、動画を組み合わせて入力し、対話形式で動画の生成や編集を行う機能を備える。複雑なソフトウェアを使用せず、自然言語による指示のみで直感的な映像制作を可能にする。

(画像:Google)
同モデルは重力や運動エネルギー、流体力学などの直感的な物理法則を内部で処理している。これにより、元の被写体の動きやペース、物理的な一貫性を維持したまま、映像を破綻させずに編集を加える。例えば、歩いている人物の動画において、被写体の動作はそのままに背景の時間を「早朝」から「深夜」に変更したり、全く別の風景に差し替えたりする処理を行う。元の映像が持つ文脈を保ちつつ、元々存在しなかったキャラクターや視覚効果を追加することも可能としている。また、クレイアニメ風や3Dボクセルアート風など、映像全体の表現スタイルも自然言語の指示で変更できる。
Google 動画版ナノバナナ「Gemini Omni」発表、対話で動画生成の時代へ
(図版:ビジネス+IT)
マルチモーダル機能による入力の多様性も強みとする。テキスト、画像、音声、ビデオを複合的に読み込み、それらを統合して新たな動画を出力する。利用者が自身で撮影した動画に対して参考用の画像を添えて指示を出すことで、意図に沿った映像を作成できる。
さらに、クリエイター向けツール「Google Flow」と連携し、複数パターンの映像を一括で生成する機能を提供する。1枚の画像データからAIに最適なカメラアングルを探索させ、16通りの異なる動画を同時に生成するなど、大規模な制作作業に対応する。Gemini Omniファミリーの第一弾となる「Gemini Omni Flash」は、同社のGeminiアプリやGoogle Flow AI studio、YouTube Shortsなどにおいてすでに機能の提供を開始している。
AI・生成AIのおすすめコンテンツ
Googleで見つけやすく
共有する
-
0
-
3
-
0
-
3
-
3
関連タグ
タグをフォローすると最新情報が表示されます
AI・生成AIの関連コンテンツ
あなたの投稿
PR
PR
PR
