- 2026/05/23 09:00 掲載
GPT5.5は「136」Opus 4.7が「132」AIの知能指数をはかる「AI IQ」公開
最先端のフロンティアモデルを単一のスコアで可視化
エンジニアで起業家のライアン・シー氏は2026年5月、主要な人工知能(AI)モデルの性能を人間の知能指数(IQ)スケールで換算・評価するプロジェクト「AI IQ」を公開した。GPT-5.5やClaude Opus 4.7といった最先端のフロンティアモデルを単一のスコアで可視化し、複雑化するAIモデルの性能比較に新たな評価軸を導入した。

(画像:ビジネス+IT)
同プロジェクトは複数の公開ベンチマークを基に各モデルの推定IQを算出し、人間のIQ分布を示す標準的なベルカーブ上にマッピングする。複数の指標が並ぶ従来のランキング表に代わり、直感的な性能比較を可能にした。業界内ではこの手法に対し、複雑なAI市場の性能評価に明確さをもたらすと評価する声がある一方、多角的な推論能力を単一の数値に還元することの危うさを指摘する意見も存在し、評価が分かれている。
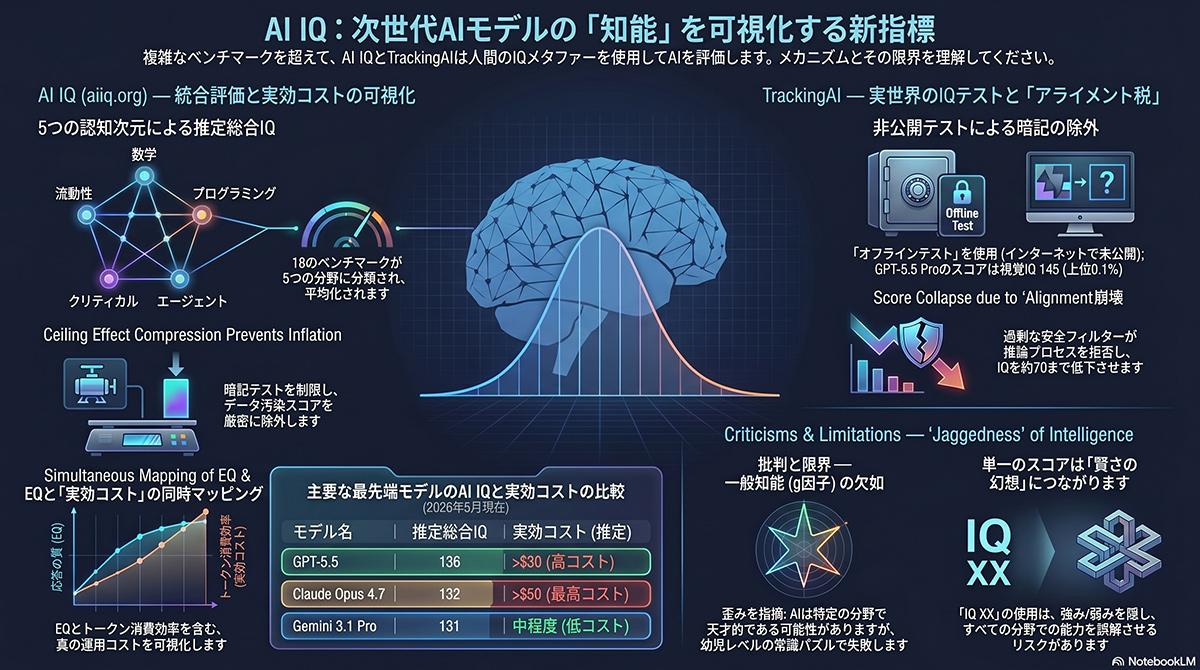
AIの知能指数を図る「AI IQ」公開
(図版:ビジネス+IT)
AIモデルのIQ評価を巡っては、学習データへのテスト内容の混入(データ汚染)という技術的課題も浮き彫りになっている。外部評価サイト「TrackingAI」が実施した検証によると、インターネット上に公開されている既存のIQテストではGPT-5.5が140を超えるスコアを記録した。しかし、学習データに一切含まれない完全に非公開のオフラインテスト環境では、同モデルのスコアが70付近まで低下した。対照的に、同条件の非公開テストでClaude Opus 4.7は118を記録しており、評価環境の前提条件によってモデル間の優位性が大きく変動する事実が確認された。
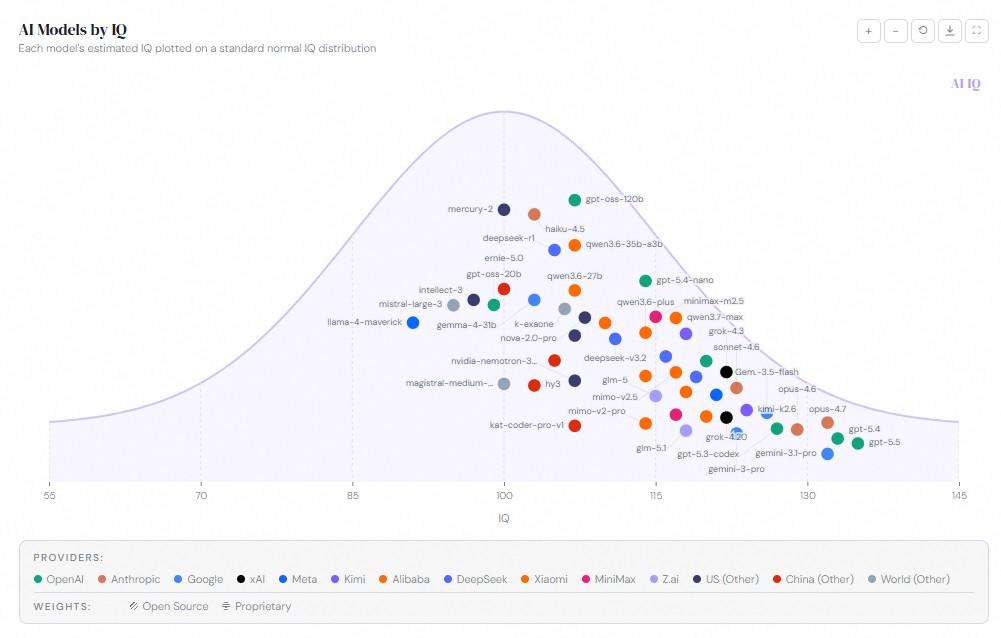
各モデルの推定IQを標準正規IQ分布上にプロットしたもの(図版:AI IQ)
実務環境における性能分析では、GPT-5.5がトークンの出力速度やコスト効率面で優位に立ち、Claude Opus 4.7が適応型推論や複雑なタスク処理において高いパフォーマンスを示す傾向にある。AI IQのような統合的な単一指標の登場と、独立環境でのプライベートな検証結果の双方が、利用者のモデル選定における新たな判断基準として機能している。
AI・生成AIのおすすめコンテンツ
Googleで見つけやすく
共有する
-
0
-
2
-
0
-
2
-
1
関連タグ
タグをフォローすると最新情報が表示されます
AI・生成AIの関連コンテンツ
あなたの投稿
PR
PR
PR
