- 会員限定
- 2024/11/20 掲載
Mistral AIの「Pixtral 12B」「Pixtral Large」とは何か? 手書きからWeb制作も可能に
テキストだけでなく、画像認識能力も持つ、いわゆるマルチモーダルモデルとして、OpenAIのGPT-4o、アンソロピックのClaude3.5 Sonnet、またオープンソースではマイクロソフトのPhi-3.5などが人気を博している。これに対し、Mistralが2024年9月と11月にリリースしたマルチモーダルモデル「Pixtral 12B」「Pixtral Large」がその人気リストの上位に食い込むかもしれない。強みは、画像認識能力に加え、テキスト処理能力も高い点にある。Pixtralとはどのようなモデルなのか、その詳細を解説したい。
英大学院修了後、RPA企業に勤務。大手通信社シンガポール支局で経済・テクノロジーの取材・執筆を担当。その後、Livit Singaporeでクライアント企業のメディア戦略とコンテンツ制作を支援(主にドローン/AI領域)。2026年2月、シンガポールで「SimplyPNG」を設立し、AI画像編集のモデル運用とGPUコスト最適化を手がける。主にEC向け画像処理ワークフローの設計・運用自動化に注力。
(出典:MistralのWebサイト)
マルチモーダルAI「Pixtral 12B」「Pixtral Large」とは?
フランスのAIスタートアップMistral AIは9月、同社初となるマルチモーダルAIモデル「Pixtral 12B」をリリースした。Pixtral 12Bとは、テキストと画像を組み合わせた分析が可能なマルチモーダルAIモデルで、高いテキスト処理能力に加えて、画像認識能力を持つのが特徴だ。
Pixtral 12Bは、120億のパラメータを持ち、画像とテキストデータを交互に学習させる手法で訓練された。この学習方法により、マルチモーダルタスクでの高いパフォーマンスを実現しつつ、テキストのみのベンチマークでも高い性能を維持しているという。
さらにMistralは11月、7月に発表された大規模言語モデル「Mistral Large 2」をベースに画像を理解できるよう調整した「Pixtral Large」を発表。Pixtral Largeのパラメータ数は1240億にのぼり、多様な言語を取り扱える。
Pixtralのアーキテクチャは、画像をトークン化するビジョンエンコーダーと、テキストトークンを予測するマルチモーダルトランスフォーマーデコーダーの2つのコンポーネントで構成されている。
ビジョンエンコーダーは4億のパラメータを持ち、ゼロから訓練された。一方、マルチモーダルデコーダーは、Mistralの既存モデル「Mistral Nemo」をベースに構築されている。
Pixtralの特徴は、可変サイズの画像に対応していることだ。Mistralによると、画像を16×16ピクセルのパッチに分割し、各パッチを画像トークンに変換する方式を採用。これにより、画像の元の解像度とアスペクト比を保ったまま処理が可能となり、複雑な図表やドキュメントの高解像度での理解や、小さなアイコンやクリップアートの高速推論など、柔軟な対応が可能になった。
また、12万8000トークンの長いコンテキストウィンドウをサポートしており、この範囲内で任意の数の画像を処理できる点も特徴だ。これにより、複数の画像を含む長文のドキュメントや、画像と詳細なテキスト説明が混在するコンテンツなどを、一度に分析することができる。
Pixtralのリリースにより、MistralはOpenAI、アンソロピック、グーグルなどが主導するマルチモーダルAI開発の競争に本格参入したことになる。Pixtral 12Bは120億パラメータという比較的小規模なモデルでありながら、大規模モデルに匹敵する性能を示しており、新しく1240億のパラメータを持つPixtral Largeの登場で、今後のAI市場に与える影響は大きいと予想される。
ベンチマーク詳細、その精度、その強みとは?
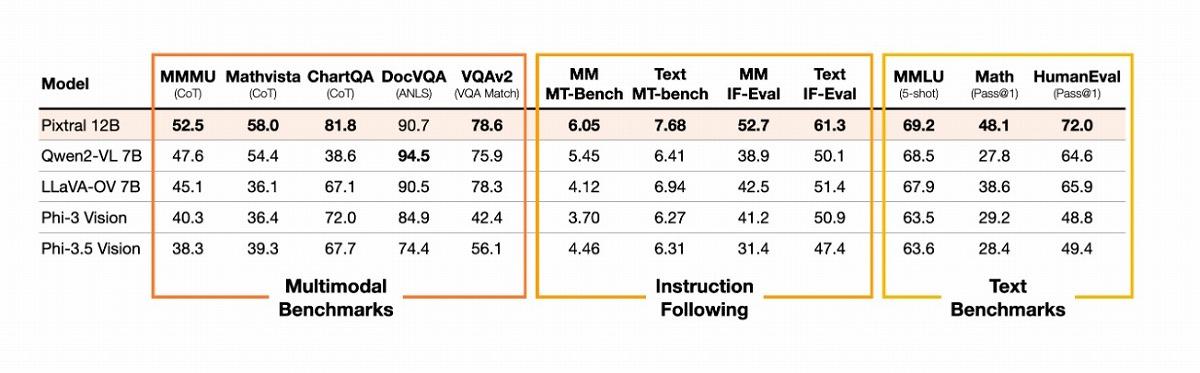
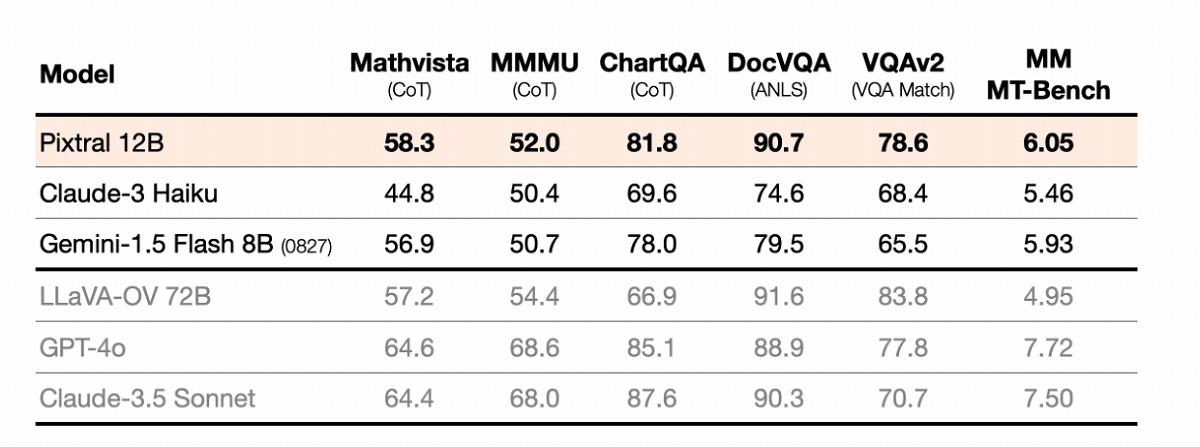
「Pixtral 12B」「Pixtral Large」の性能を評価するため、Mistralは複数のベンチマークテストを実施し、その結果を公開している。まずPixtral 12Bについては、同規模のオープンソースモデルを大きく上回るだけでなく、最新のモデルにはかなわないながら、一部の大規模クローズドモデルに匹敵する性能を実現したことが示された。
数学的視覚推論を評価するMathvista(CoT)では58.3%、マルチモーダル理解力を測るMMMU(CoT)では52.0%、チャート理解力を測るChartQA(CoT)では81.8%のスコアを記録。また、文書視覚質問応答を評価するDocVQA(ANLS)では90.7%、一般的な視覚質問応答能力を測るVQAv2(VQA Match)では78.6%を達成している。
(出典:MistralのWebサイト)
これらのスコアは、マイクロソフトのビジョンモデルPhi-3.5 Visionを大きく上回る。たとえば、Mathvista(CoT)ではPhi-3.5 Visionの39.3%に対し、Pixtral 12Bは58.3%と、その差は19ポイントにも及ぶ。MMMU(CoT)でも38.3%対52.0%と、13.7ポイントの差をつけている。
特筆すべきは、Pixtral 12Bが一部の大規模モデルをも凌駕している点だ。720億パラメータを持つLLaVA-OV 72Bと比較すると、ChartQA(CoT)では81.8%対66.9%とPixtral 12Bが優位に立つ。
(出典:MistralのWebサイト)
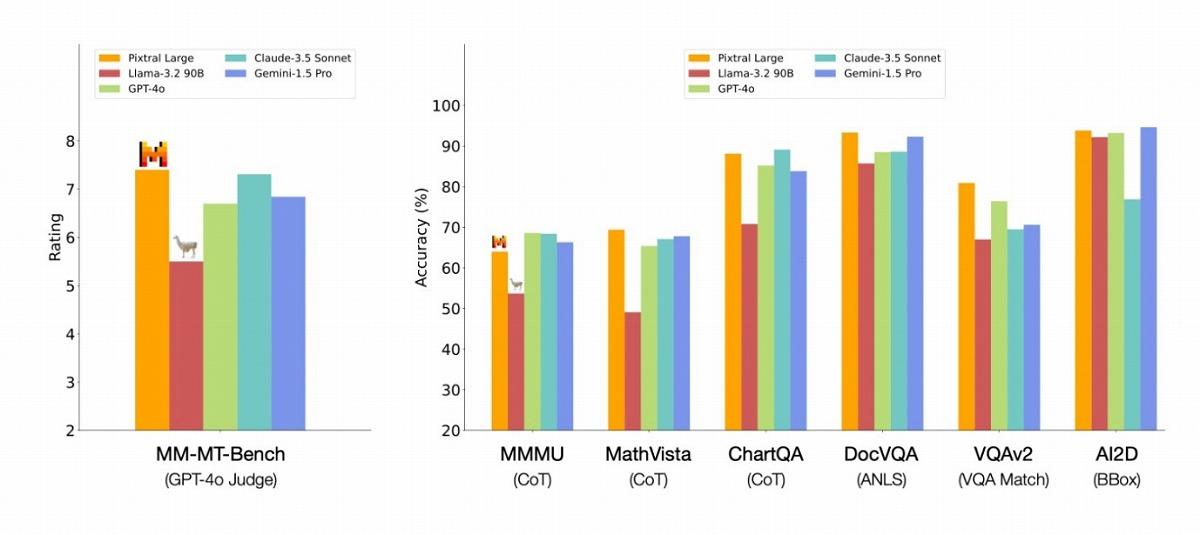
一方、Pixtral Largeは、GPT-4o、Claude-3.5 Sonnet、Gemini-1.5 Proなどの錚々たる大規模言語モデルと比較しても正面からそれらの各種スコアを上回る。MM-MT-Benchでは、これらを上回ってトップになったと主張している。
Mistralは、Pixtralの強みとして、マルチモーダルタスクと従来のテキストタスクの両方で高いパフォーマンスを発揮する点を挙げている。特に指示追従(instruction following)能力において、他のオープンソースマルチモーダルモデルを大きく上回ると指摘する。テキストのみの指示追従能力を評価するIF-EvalとMT-Benchでは、最も近いオープンソースモデルと比較して20%の相対的改善を達成したという。
また、Mistralは独自にマルチモーダル版のIF-EvalとMT-Benchを作成し、Pixtral 12Bの評価を行っている。これらのベンチマークでも、Pixtral 12Bは他のオープンソースモデルを上回る結果を示したとされる。
Pixtralは、複雑な図表や文書の理解、チャート分析、マルチモーダル推論、指示追従などのタスクで大いに活用できそうだ。また画像の解像度とアスペクト比を保ったまま処理できる点も実際のユースケースに生きてくると思われる。 【次ページ】Pixtralの活用事例:ウェブデザイン
AI・生成AIのおすすめコンテンツ
関連タグ
タグをフォローすると最新情報が表示されます
AI・生成AIの関連コンテンツ
あなたの投稿
PR
PR
PR
