- 会員限定
- 2024/03/27 掲載
Stability AIも「Stable Code 3B」で参入、激化する「コード生成AI」シェア獲得競争
生成AIが得意とするのはテキストや画像生成だけではない。プログラムのコード生成も得意分野の1つ。この2年ほどで「コード生成AI」領域の研究開発が進み、コード生成の精度は大きく改善、現在はユーザー獲得をめぐる競争が激化している。コード生成AIの進化の過程を鑑みつつ、Stability AIの「Stable Code 3B」などの最新モデルはどれほどの実力を持つのか、その現状を探ってみたい。
英大学院修了後、RPA企業に勤務。大手通信社シンガポール支局で経済・テクノロジーの取材・執筆を担当。その後、Livit Singaporeでクライアント企業のメディア戦略とコンテンツ制作を支援(主にドローン/AI領域)。2026年2月、シンガポールで「SimplyPNG」を設立し、AI画像編集のモデル運用とGPUコスト最適化を手がける。主にEC向け画像処理ワークフローの設計・運用自動化に注力。

(Photo/Shutterstock.com)
〈オススメ記事〉
・ChatGPT以前のソフトウェア開発は「石器時代」、プログラミングが劇的大変化のワケ(https://www.sbbit.jp/article/cont1/131345)
・ChatGPT以前のソフトウェア開発は「石器時代」、プログラミングが劇的大変化のワケ(https://www.sbbit.jp/article/cont1/131345)
OpenAIが主導してきたコード生成AIモデルの開発
プログラムのコード生成も例外ではなく着実に前進しており、開発競争は激化の様相となっている。
そんなコード生成分野の開発をリードしてきたのはOpenAIだ。テキスト生成を得意とするGPTモデルを開発しつつ、それらのモデルをコーディングデータセットでファインチューニングする形で、コード生成に強い大規模言語モデルの開発を推進してきた歴史を持つ。
そんなOpenAIのコード生成AI開発の歴史において重要な出来事となるのが、2021年7月の論文発表だろう。この論文が重要視される理由は大きく2つある。1つは、OpenAIが当時最新のテキスト生成AIだったGPT-3をコーディングデータで微調整したコード生成AI「Codex 12B」を開発・発表し、テキストだけでなく、コーディングも生成AIの可能性領域であることを示した点にある。
もう1つがこのCodex 12Bのコーディング能力を評価するために「HumanEval」という新たなベンチマークが導入されたことだ。この「HumanEval」は、その後の大規模言語モデル開発において、モデルのコード生成能力を評価するスタンダードの1つとなり、さまざまなモデルを直接比較できる非常に有用な指標となっている。
HumanEvalは、164のPythonによるプログラミング問題によって構成されるデータセットで、コーディングタスクにおける言語理解、推論、アルゴリズム、数学能力を評価するように設計されている。一般的に、1回の試行で問題解決できる割合(pass@1)が評価対象となるが、10回(pass@10)や100回(pass@100)の試行結果も付随して論文に記載されることもある。
HumanEvalには以下のような問題が含まれる。

(出典:Arxiv.org)
これは「リスト内の各要素に1を加え、新しいリストとして返す」という比較的シンプルなPythonの問題。この問題に関しては、Codex 12Bは90%の確率で正しいコードを生成できたと報告されている。

(出典:Arxiv.org)
2つ目は「リスト内の整数のうち、偶数位置にあるすべての奇数要素を加算して合計を返す」という1つ目の問題に比べ、若干複雑さが増した問題。Codex 12Bの1回目試行における正解率は17%まで下がってしまう。このほかにもさまざまな難易度のPythonのプログラミング問題が用意されている。
HumanEvalスコアを時系列でトラッキングすることで、コード生成AIの進化具合を観察することも可能だ。
まず上記論文で披露されたOpenAIのCodex 12BのHumanEvalスコア(pass@1)は28.81%だった。2021年7月時点では、まだ競合モデルもなく、これがこの時点における最高スコアとみなされている。同時にGPT-3でもHumanEvalテストが実施されたが、スコアは0%と、当時のテキスト生成モデルにはコーディング能力がなかったことが示唆される結果となった。
その後開発が進み、生成AIのコーディング能力も大きく改善しており、HumanEvalスコアも右肩上がりで上昇中だ。
直近で最も包括的なHumanEvalスコア比較は、グーグルGeminiのテクニカルレポートに見ることができる。同レポートによると、最も高いHumanEvalスコアを記録したのはグーグルGemini Ultraで、その数値は74.4%に達したという。これにGemini Proが67.7%、アンソロピックのClaude2が70%、GPT-4が67%、Grokが63.2%、GPT-3.5が48.1%などと続く。
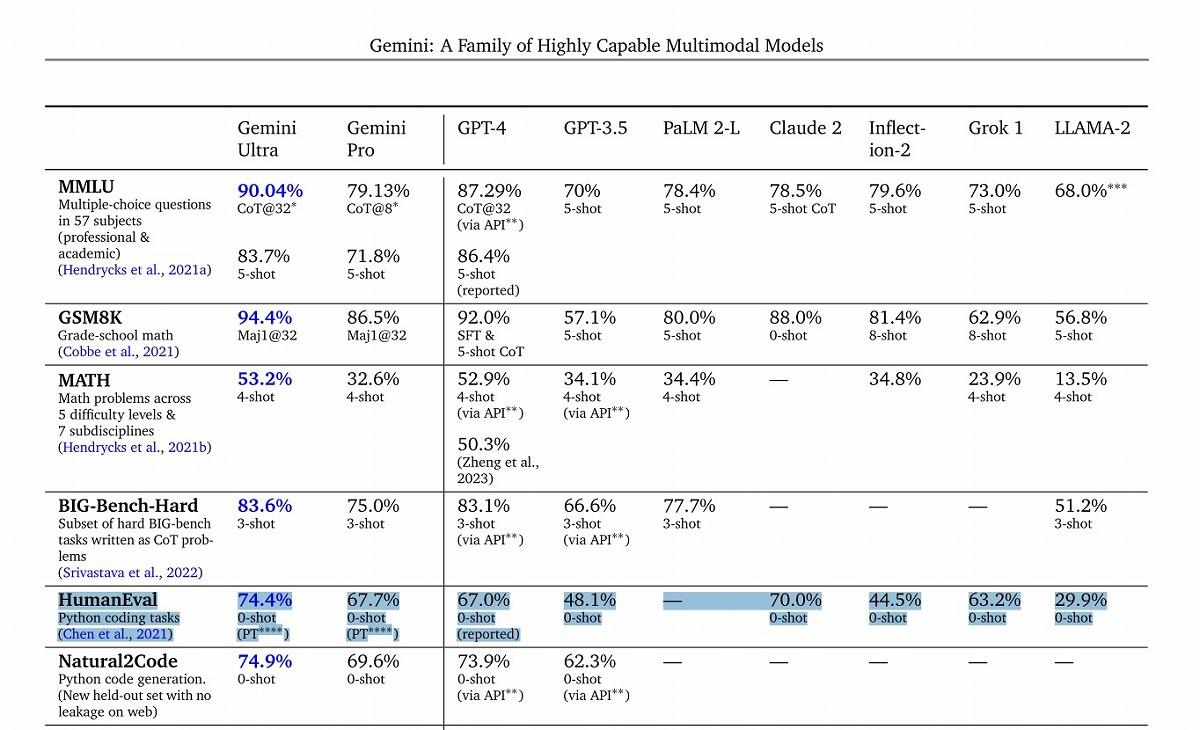
(出典:グーグルGeminiのテクニカルレポート(https://storage.googleapis.com/deepmind-media/gemini/gemini_1_report.pdf))
システム開発総論のおすすめコンテンツ
関連タグ
タグをフォローすると最新情報が表示されます
あなたの投稿
PR
PR
PR
