- 2026/02/26 掲載
【世界最速軽量】米Inception、拡散モデル型の推論LLM「Mercury 2」を発表
従来の自己回帰モデルの限界を超え、複数のテキストブロックを並列処理することで高速化を図る
AIスタートアップのInception Labsが、拡散モデルを採用した世界初の推論LLMであるMercury 2を発表した。従来の自己回帰型モデルが抱える処理速度の限界を打ち破り、複数のテキストブロックを並列処理することで推論を大幅に加速させている。同等クラスの既存モデルと比較して5倍以上の速度を記録し、生成AIのアーキテクチャに新たな選択肢を提示した。

(画像:ビジネス+IT)
世界初の拡散モデル型の推論LLM「Mercury 2」とは?
Inception Labsが開発したMercury 2は、拡散モデルに基づいて設計された世界最速クラスの推論LLMである。従来のLLMが1トークンずつ順番にデータを処理する自己回帰型のシーケンシャルデコードを採用しているのに対し、Mercury 2は複数のトークンを並列で生成し、少数のステップで処理を収束させる仕組みを備えている。
拡散モデル型高速推論LLM「Mercury 2」とは?
(図版:ビジネス+IT)
このアーキテクチャの変更により、NVIDIAのBlackwell GPU環境において1秒あたり1009トークンという高速なテキスト生成能力を実現した。エンドツーエンドのレイテンシはわずか1.7秒にとどまり、Gemini 3 Flashの14.4秒やClaude Haiku 4.5の23.4秒と比較して圧倒的な処理速度を記録している。
料金体系の面でも競争力を高めており、100万入力トークンあたり0.25ドル、100万出力トークンあたり0.75ドルに設定されている。これは同等の処理能力を持つ競合モデルの半額から4分の1程度のコストである。推論性能においても、科学計算や研究レベルのコーディング能力を評価するSciCode、指示追従能力を測るIFBench、過去の数学競技問題を用いたAIMEなどのベンチマークテストでトップクラスのスコアを獲得した。最大12万8000トークンのコンテキストウィンドウに対応し、外部ツールのネイティブ利用やJSON形式での出力機能も備えている。
同社は2025年にも前身となる小規模チャット向けモデルである初代Mercuryを公開しており、標準GPU上で低レイテンシーなリアルタイム音声応答を実現していた。当時から人間同士のような自然なテンポの対話を可能にする速度が評価され、Microsoftの自然言語インターフェースプロジェクトで初のLLMパートナーに選定される実績を残している。
今回のMercury 2は、その並列生成プロセスをさらに洗練させ、高度な推論能力と長大なコンテキスト処理を統合した次世代モデルとして、遅延が許されない音声アシスタントや自動コーディングツールへの組み込みが想定されている。現在はOpenAI互換のAPIを通じて早期アクセスが提供されており、ブラウザ上のデモ環境で挙動を確認できる。
LLMの2大潮流、自己回帰モデルと拡散モデルとは?
ChatGPTをはじめとする現代の主要な大規模言語モデルの大半は、トランスフォーマーと呼ばれるアーキテクチャを基盤としている。トランスフォーマーに基づく自己回帰型モデルは、入力された直前の文脈から次に続く単語を確率的に予測し、文章の先頭から1トークンずつ順番にテキストを生成していく。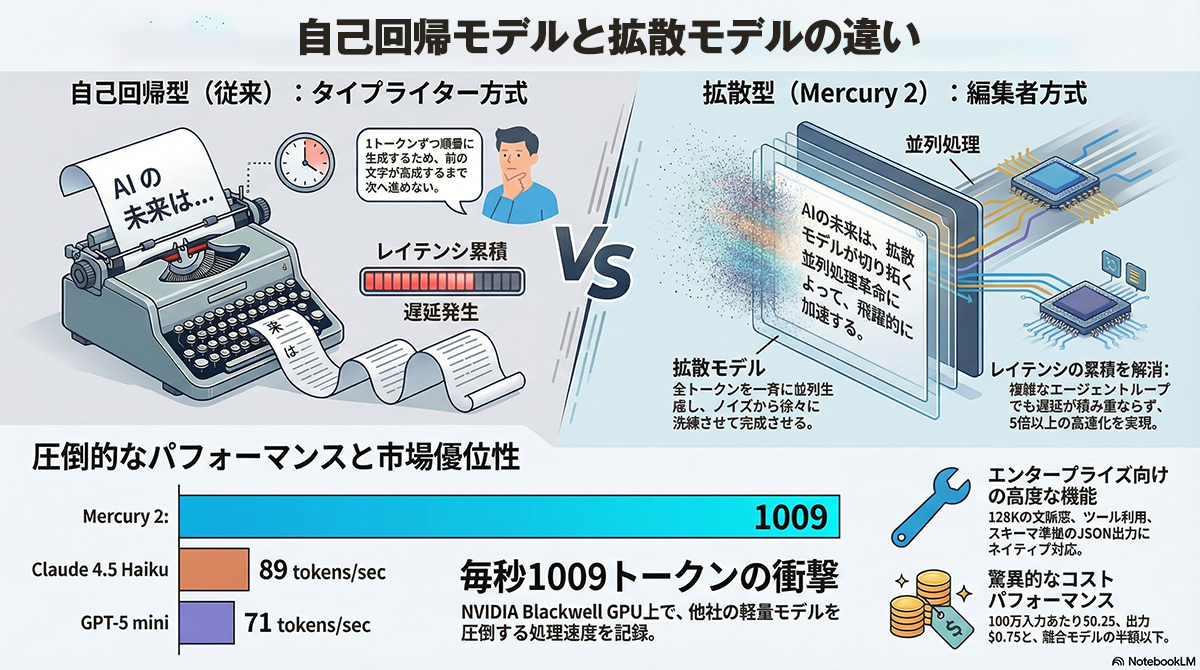
(図版:ビジネス+IT)
しかしAIが単一のプロンプトに答えるだけでなく、検索パイプラインや情報の抽出ジョブなどバックグラウンドで複雑な処理ループを実行するようになると、この逐次的な生成プロセスはシステム全体の遅延を蓄積させるボトルネックとなっていた。すべてのステップや再試行において発生する待機時間が、リアルタイム性を損なう要因として浮上していたのである。
これに対してMercury 2が採用した拡散モデルは、テキストを1語ずつ順番に紡ぐのではなく、複数のテキストブロックを同時に修正しながら全体を完成させる手法をとる。画像生成AIなどで主流となっていた技術をテキストの生成に応用した形である。
Inception Labsはこの処理プロセスを、編集者が下書きの最初から順番に目を通すのではなく、原稿全体を見渡して一斉に手を入れていく作業に例えている。拡散モデルを言語生成に応用する試みは他社も進めており、Google DeepMindは過去にGemini Diffusionというモデルのプロトタイプを提示し、当時のGemini 2.0 Flash Liteと同等の性能を実証していた。
しかし、推論能力を統合し、本番環境で稼働する商用モデルとして一般公開されたのはMercury 2が初となる。AI技術の進展に伴い、システム全体の応答速度がユーザー体験に直結する時代を迎えている。多くのAI企業が市場を支配するトランスフォーマーアーキテクチャの次の技術を模索する中で、並列処理による圧倒的な速度とコスト効率を実現した拡散モデルが、今後の言語モデルの新たな基盤として定着するかが業界の焦点となっている。
AI・生成AIのおすすめコンテンツ
Googleで見つけやすく
共有する
-
0
-
0
-
0
-
1
-
0
関連タグ
タグをフォローすると最新情報が表示されます
AI・生成AIの関連コンテンツ
あなたの投稿
PR
PR
PR
