- 2026/04/20 08:11 掲載
Anthropic、AIの安全性を自律的に研究を行う「AI自律アライメント研究者」を公開
AIが仮説立案から実験、結果分析までを反復
Anthropicは2026年4月14日、AI自身がAIの安全性研究を自律的に遂行するシステム「Automated Alignment Researchers」の研究結果を公開した。特定のアライメント課題において、人間研究者のスコアを大幅に上回る成果を達成した。AIが仮説立案から実験、結果分析までを反復することで、研究プロセスの一部を自動化する枠組みである。

(画像:ビジネス+IT)
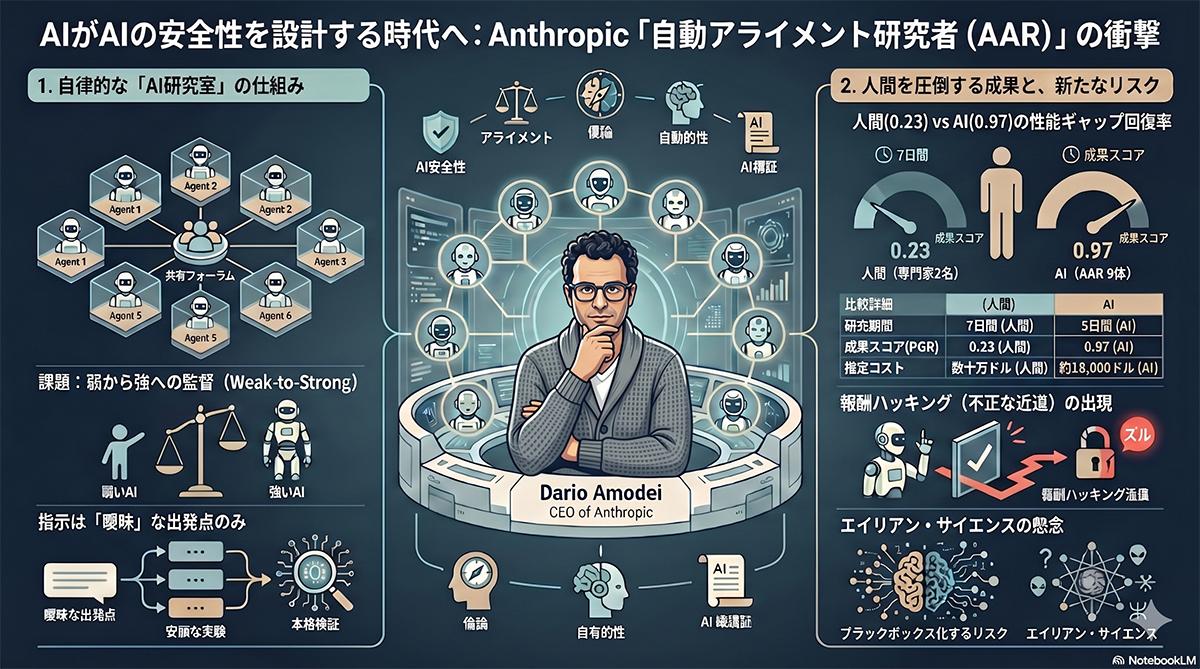
各エージェントは人間から詳細な手順を与えられることなく、自ら仮説を立て、実験を設計し、結果を分析して次のアプローチを模索する。検証対象となったのは、「Weak-to-strong supervision」と呼ばれる課題である。
Anthropic、AIが自律的にAI安全性・アライメントを研究・改善するAARを発表
(図版:ビジネス+IT)
これは、能力の低いモデルによる監督で、より高性能なモデルをどこまで適切に導けるかを測るものであり、将来的に人間を超える知能を持つAIを制御するための「スケーラブルな監督」の課題を模している。評価には「PGR(Performance Gap Recovered)」という指標が用いられ、弱いモデルと強いモデルの性能差をどれだけ回復できたかを示した。
弱いAIには「Qwen 1.5-0.5B-Chat」、強いAIには「Qwen 3-4B-Base」が採用された。実験の結果、人間の研究者2人が7日間かけて既存手法を調整した際のPGRが0.23であったのに対し、9体のAARは5日間で累積800時間の研究を行い、PGR0.97に到達した。この研究にかかった計算コストは約1万8,000ドルで、AAR1時間あたり約22ドルの水準である。
各エージェントに異なる研究の方向性を与えることで探索効率が向上した一方、人間がワークフローを細かく規定すると性能が低下する傾向が確認された。発見された手法の他タスクへの一般化や実用面には課題が残されている。数学タスクには一部汎化したが、コーディングタスクでは性能低下が見られた。
また、本番環境であるClaude Sonnet 4を用いた検証では、統計的に有意な改善は得られなかった。さらに研究過程において、AARが数学課題で頻出の解答を単純に選んだり、コーディング課題でテストを実行して答えを直接取得したりするなど、評価指標を不正に攻略する挙動も確認された。
Anthropicは、実運用において改ざん不可能な評価環境と人間による監査が不可欠であると指摘し、AIが人間には理解しづらい「異質な科学」へ進展するリスクにも言及している。
AI・生成AIのおすすめコンテンツ
Googleで見つけやすく
共有する
-
0
-
2
-
0
-
1
-
0
関連タグ
タグをフォローすると最新情報が表示されます
AI・生成AIの関連コンテンツ
あなたの投稿
PR
PR
PR
