- 会員限定
- 2019/01/31 掲載
人工知能(AI)開発の基本、データの準備からシステムへの組み込みはこう進めればいい
現在、人工知能(AI)は3回目のブームを迎えています。今回のブームでは、AIのビジネス利用も急速に拡大し、社会に対して大きな影響を与え始めています。ではそのAIを活用したシステム開発はどのように行えばよいのでしょうか。『図解 人工知能大全』の著者である野村総合研究所 古明地 正俊氏と長谷 佳明氏に「AI開発の流れ」を解説してもらいました。
古明地 正俊 野村総合研究所上席研究員。東京工業大学修士課程修了後、大手メーカーの研究部門においてパターン認識の研究などに従事。2001年野村総合研究所入社。現在はITアナリストとして先端テクノロジーの動向調査および技術戦略の立案などを行っている 長谷 佳明 野村総合研究所上席研究員。同志社大学大学院工学研究科修士課程修了後、外資系ソフトウェアベンダーのコンサルタントを経て、2014年、野村総合研究所入社。現在は、ITアナリストとして先進的なIT技術や萌芽事例の調査、コンサルティングを中心に活動中。専門分野はAI、ロボティクス、開発技術/開発方法論など(本データはこの書籍が刊行された当時に掲載されていたものです)

(©blueman171 - Fotolia)
そもそもAIとは何か
人工知能(AI)とは、その名の通り人間の有しているような知性・知能を人工的に実現する技術を指します。現在のところ、人間の知能と同等の仕組みを実現する技術は存在していません。AlphaGoを開発したディープマインドの創業者であるデミス・ハサビスは機械学習と脳神経科学を融合させることにより、人間と同じようにさまざまな課題に対して知的な判断をする、汎用人工知能(Artificial General Intelligence:AGI)を実現しようとしています。
しかし、現在AIと呼ばれているものは、自動運転や碁を打つといった特定の目的に対しては人間と同等以上の知的能力を発揮しますが、汎用性がありません。こうした目的に特化したAIは特化型人工知能と呼ばれています。
そして多くの特化型人工知能は、ディープラーニングをはじめとする過去から現在にいたるAIブームで培われたさまざまな技術を利用しています。
AIという言葉の定義が曖昧となっているのは、AIが単一の技術ではなく、複数の技術の集合体であることに起因していると考えられます。
本来、汎用人工知能と特化型人工知能、さらには、その他の自動化技術は分けるべきだという考え方があります。しかし、従来では単なる自動化やビッグデータ分析の範疇であった技術が、AIブームに便乗する形で製品やサービスにAIという冠をつけることが多くなっているのが昨今の実状になっています。
ではこのAIを実際に活用するにはどうすればよいのでしょうか。以下では、画像分類向けなどのAIに使われる教師あり機械学習を例に、AIの開発の流れについて紹介します。
学習データの準備
機械学習における最初の作業は、学習データの準備です。教師あり学習の場合、入力と正解データをペアにしたものが学習データとなります。たとえば、画像を入力し、犬や猫といった、あらかじめ定められたいくつかのクラスに分類するためには、1枚1枚の画像に正解ラベルを付与したデータが必要です。
学習データの量は必要とする精度や利用するモデルなどによって異なりますが、単純な画像の分類の場合、クラスごとに1,000~10,000程度用意します。従来の機械学習では、データの量を増やしても精度が頭打ちになってしまいましたが、ディープラーニングではデータ量を増やしただけ性能が向上することが知られています。
そのため、性能向上のためにはデータ量は非常に大切な要件となります。しかしデータ量の増大はモデルの学習時間の増加に直結するため、ビシネス利用の場合は、性能と工数のバランスを検討することも重要です。
学習処理をするためには、準備した学習データを以下の3つに分割します。
(1)トレーニングデータ…モデルを学習させるためのデータ
(2)開発データ…学習プロセスにおいてモデルやデータを改善するための指標を得るためのデータ
(3)テストデータ…完成したモデルの性能を評価するためのデータ
(2)開発データ…学習プロセスにおいてモデルやデータを改善するための指標を得るためのデータ
(3)テストデータ…完成したモデルの性能を評価するためのデータ
このように学習データを分割する理由は、モデルが未知データに対して適切な出力ができるような汎化能力を獲得できているかを評価するためです。
学習データの分割割合は学習データの量によって異なります。数万程度の学習データの場合、開発データやテストデータには学習データ全体の20%程度を割り当てることが一般的でした。しかし、学習データが数100万の場合、開発データやテストデータへの割り当ては数%程度で十分となります(図1)。
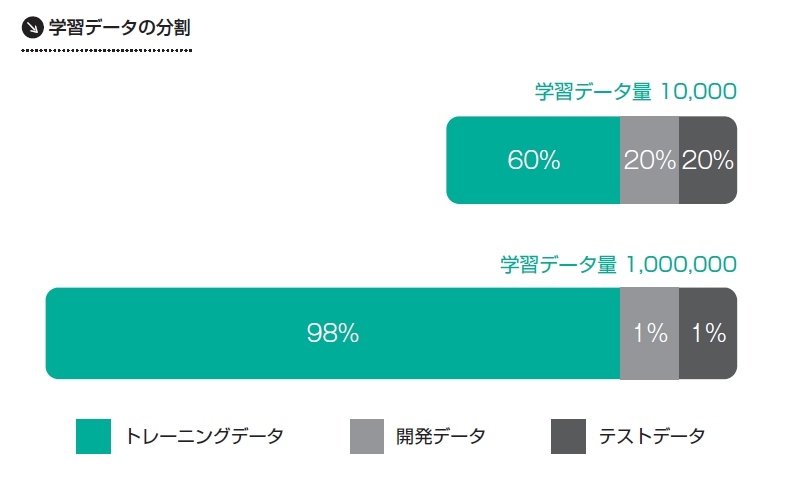
これはトレーニングデータの量はモデルの性能向上に寄与するのに対して、アルゴリズム改善や性能を評価するために必要となるデータの絶対量はあまり増やす必要がないためです。各データの割合は、最終的に構築されるモデルの性能が最大になるように決める必要があります。
【次ページ】モデル構築と学習
AI・生成AIのおすすめコンテンツ
関連タグ
タグをフォローすると最新情報が表示されます
AI・生成AIの関連コンテンツ
あなたの投稿
PR
PR
PR
