- 2026/05/04 05:14 掲載
米スタンフォード大報告書、AI学習データが枯渇しつつある「ピークデータ」を警告
人間のテキストデータが、早ければ2026年にも枯渇する懸念
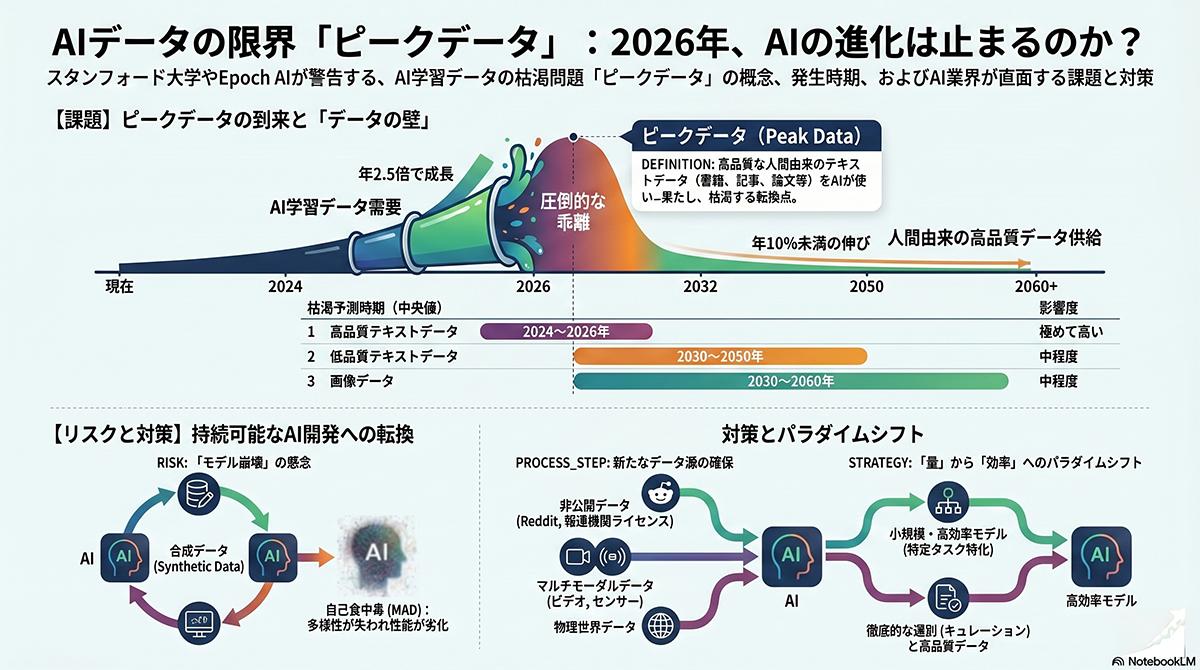
人工知能(AI)の開発基盤となるインターネット上の高品質な人間のテキストデータが、早ければ2026年にも枯渇する懸念が高まっている。米スタンフォード大学のAI指標報告書や研究機関Epoch AIの調査により、現在の消費ペースが続けば数年以内に「ピークデータ」に達することが判明した。AIの性能向上を支えてきた従来の手法が限界を迎える状況が浮上している。

(画像:ビジネス+IT)
この「ピークデータ」と呼ばれる資源の枯渇は、データ量と計算量の拡大によってAIをスケールアップしてきた従来の開発手法に根本的な見直しを迫るものだ。これまでテクノロジー企業はウェブ上の膨大な文章をかき集めることでモデルの精度を向上させてきたが、その無償の供給源が限界に達しつつある。
米スタンフォード大学報告書、AI学習データが枯渇しつつある「ピークデータ」を警告
(図版:ビジネス+IT)
代替策として、AI自身が生成した「合成データ」を次世代モデルの学習に用いる試みが業界内で進められている。しかし、この手法には技術的なリスクが伴うことが複数の研究で確認されている。合成データに過度に依存して学習を繰り返すと、「モデル崩壊」や「自己貪食障害」と呼ばれる出力の劣化を引き起こす。モデルが生成する情報の多様性が失われ、元のデータ分布におけるマイノリティな知識や外れ値が忘却されてしまうためだ。医療などの高リスクな専門領域では、誤診などの深刻なエラーにつながる問題も指摘されている。
スタンフォード大学の報告書は、導入現場におけるAIの生産性向上効果にもばらつきがあると分析している。プログラミングなどの構造化されたタスクでは大幅な改善が見られる一方、複雑なビジネス判断を要する領域では効果が薄いかマイナスに作用する事例も報告された。高精度なAIへの過信が、人間の検証作業を怠らせる逆説的な現象も生じている。
データ不足が表面化するなか、AI開発企業は報道機関との有償提携による独自データの確保や、人間の専門家による検証を組み込んだ学習プロセスの構築へと戦略の転換を急いでいる。無尽蔵のデータに依存した成長モデルが終焉を迎え、今後は限られた質の高いリソースをいかに効率的に活用するかがAI開発の成否を分ける段階に入った。
AI・生成AIのおすすめコンテンツ
Googleで見つけやすく
共有する
-
0
-
3
-
0
-
0
-
0
関連タグ
タグをフォローすると最新情報が表示されます
AI・生成AIの関連コンテンツ
あなたの投稿
PR
PR
PR
