- 会員限定
- 2026/06/19 18:45 掲載
ChatGPTが医療相談で大進化、週「2.3億人」が頼るAI受診前相談の衝撃とリスクとは
夜中の子どもの腹痛、健康診断で赤字になった検査値、診察後に湧いてくる疑問。そうした場面でChatGPTに相談する行動が広がっている。OpenAIは6月18日、健康分野の応答品質を改善したと発表し、毎週2億3000万人超が健康やウェルネスについて質問していることも明らかにした。GPT-5.5 Instantは、緊急受診が必要な兆候の認識や追加情報の確認、複雑な説明のかみ砕きで改善し、無料ユーザーにも提供される。これがもたらす意味はどこにあるのか。AI時代の医療の大変革を見ていこう。
(出典:OpenAI)
週2.3億人が頼るChatGPT健康相談の衝撃
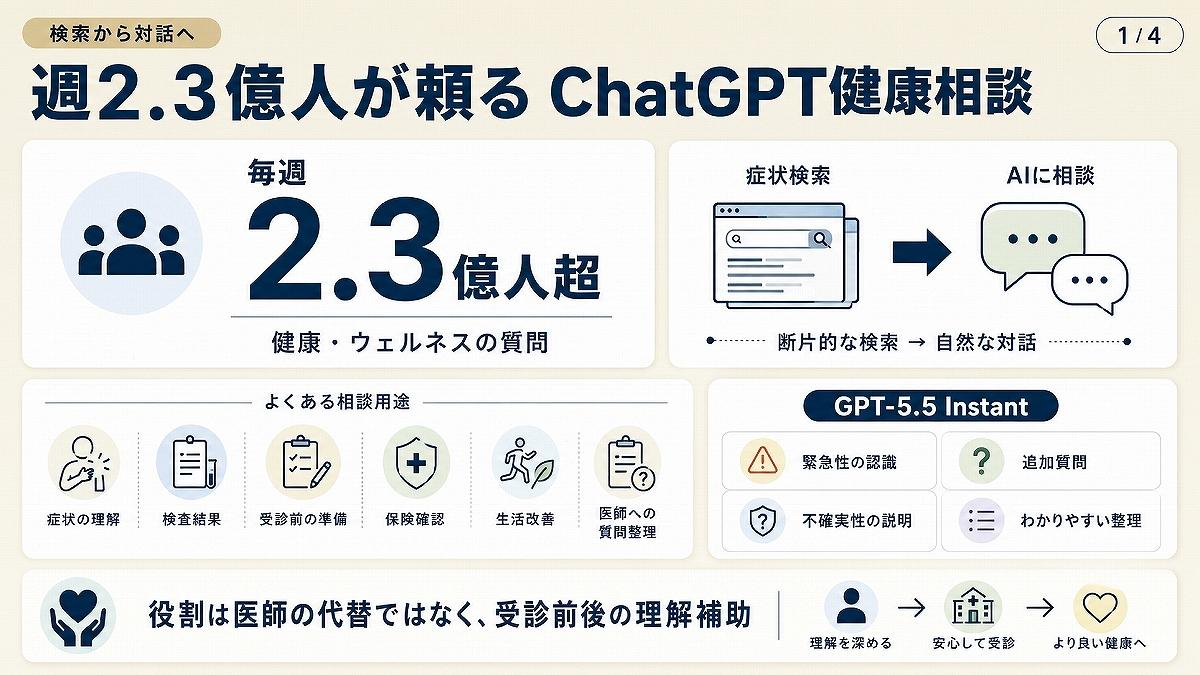
夜中に子どもが急に腹痛を訴えた。病院に行くべきか、朝まで様子を見ていいのか。あるいは会社の健康診断で見慣れない数値が赤字になっていた。医師から説明は受けたが、帰宅してから疑問が次々に湧いてきた──こうした場面で、検索窓ではなくChatGPTに症状や検査値を打ち込む人はすでに珍しくない。米OpenAIは6月18日、ChatGPTの健康分野における応答品質を改善したと発表した。注目すべきは、その利用規模だ。同社によると、毎週2億3000万人超がChatGPTに健康やウェルネスに関する質問をしている。内容は、健康情報の理解、検査結果の読み解き、診察前の準備、保険の確認、生活習慣の改善、次に医師へ何を聞くべきかの整理などに及ぶ。
(画像:本文をもとに生成AIを使用して生成)
これは単なる「医療AIの性能向上」という技術ニュースではない。検索エンジンで症状名を調べ、断片的な医療サイトを読み比べる行動が、対話型AIとのやり取りに置き換わり始めたことを示している。利用者は「この数値は何を意味するのか」「医師に聞くべきことは何か」「急いで受診すべき兆候はどこか」を、自然な言葉で問いかける。ChatGPTは、医学用語をかみ砕き、不確実性を示しながら、次の行動を整理する役割を担おうとしている。
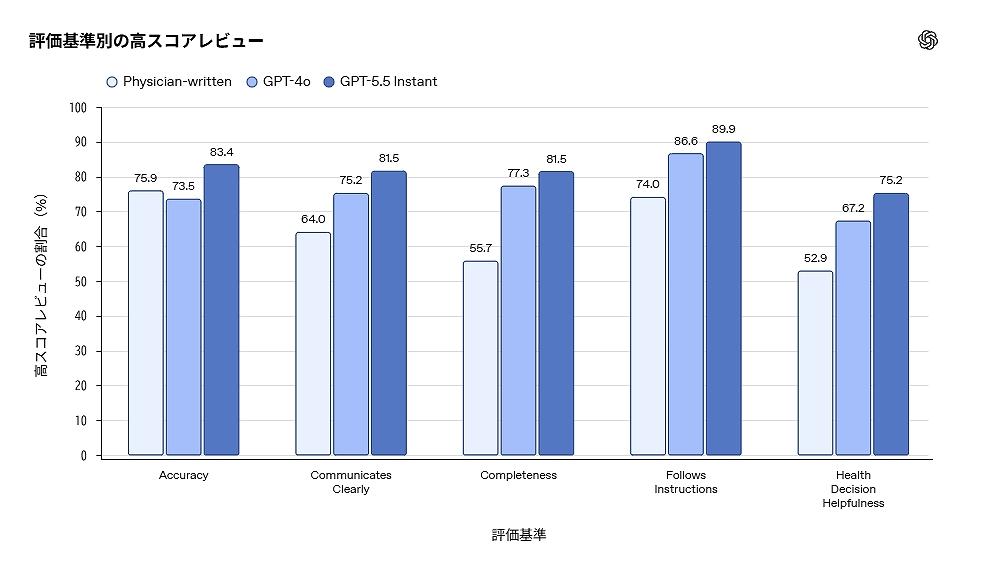
今回の発表で中核となるのは、GPT-5.5 Instantである。同社は、この無料提供されるモデルが緊急受診が必要な可能性の認識、必要な追加情報の質問、不確実性の説明、複雑な情報の分かりやすい提示で改善したと説明している。高度な医療情報理解が、一部の有料ユーザーや専門家だけでなく、一般利用者の日常に入り込む意味は大きい。
ただし、ここで誤ってはいけない。ChatGPTが医師に置き換わるという話ではない。むしろ、利用者が医療機関に行く前、あるいは診察後に自分の状況を整理する「受診前相談」「受診後の理解補助」として存在感を強めているということだ。AIが病名を決める時代ではなく、患者が医師と話す前に疑問を整える時代が始まった。そこに、医療とテクノロジーの新たな接点がある。
医師260人超が評価、何が改善したのか
今回の発表で、米OpenAIが強調したのはモデルの賢さだけではない。むしろ、医師がどのように評価に関与したかを前面に出した点が重要だ。同社は、60カ国、49言語、26診療科にまたがる260人超の医師ネットワークと連携していると説明した。医師らは、モデルの回答例を確認し、正確か、明確か、完全か、慎重さは十分か、実際の健康相談として有用かを評価する。
(画像:本文をもとに生成AIを使用して生成)
これまでAIの医療応答は、医師国家試験のような知識問題で語られることが多かった。しかし、現実の健康相談は正解を1つ選ぶ試験とはまったく違う。利用者は、症状を曖昧に表現する。検査値の背景も分からない。居住地や医療制度、既往歴、薬の服用状況によって適切な説明は変わる。求められるのは、知識量だけではなく、危険な兆候を見落とさず、必要な文脈を聞き返し、断定し過ぎない判断力だ。
そのために使われているのが、HealthBenchなどの健康分野向け評価である。HealthBenchは、262人の医師と協力して作られた評価基盤で、現実に近い5000件の健康会話と、医師が作成した評価基準で構成される。評価項目は4万8562件に及び、正確性、安全性、コミュニケーション、文脈理解、回答の完全性、適切な受診勧奨などを測る。
同社はさらに、HealthBench Professionalも使う。これは、臨床現場で医師がChatGPTに持ち込む実際のタスクに近い会話を対象にした評価だ。用途は、診療相談、文書作成、医学研究などに分かれる。各例は医師が書いた会話と、3人以上の医師が段階的に調整した評価基準を含む。
米OpenAIによれば、医師はこれまでに70万件超のモデル回答例を評価した。数分に1件のペースで医師による新たなレビューが行われているという。これは、AIを医療に使うための競争軸が「大規模モデルを作れるか」から、「医師の判断をどれだけ評価体系に組み込めるか」に移ったことを意味する。
同社の健康AI責任者であるKaran Singhal氏は、Business Insiderのインタビューで「評価の方法が分かれば、改善することはずっと容易になる」と述べている。AI医療の進化は、もはやモデル単体の性能競争ではない。医師の暗黙知を評価基準に落とし込み、日々の利用データから失敗の型を見つけ、改善し続ける運用競争になっている。

医療業界のおすすめコンテンツ
関連タグ
タグをフォローすると最新情報が表示されます
医療業界の関連コンテンツ
あなたの投稿
PR
PR
PR
