- 2026/07/01 掲載
万能だったはずのデータレイクはなぜ“沼”に?採用率65%の本命「レイクハウス」の次(2/2)
境界線を担う「データレイクハウス」の役割
このように得意領域が分かれる一方で、実は両者の役割には重なり合う部分もある。これを理解するために、データが本番環境で使われるまでの流れを見てみよう。まず生データを取り込む。次にそれを加工し、最後に分析向けに最適化する。この3段階のデータは、それぞれ未加工(ブロンズ)、改良済み(シルバー)、最適化済み(ゴールド)とも呼ばれる。データの利用者も、この段階に沿って移り変わっていく。
この流れを先ほどの役割に当てはめると、生データはデータレイク側、最適化されたデータはデータウェアハウス側に位置する。そして両者が重なり合うのが、中間にある「改良済みデータ(シルバー)」の領域だ。この重なり部分を引き受けて1つにまとめるのが、レイクハウスだ(図2)。
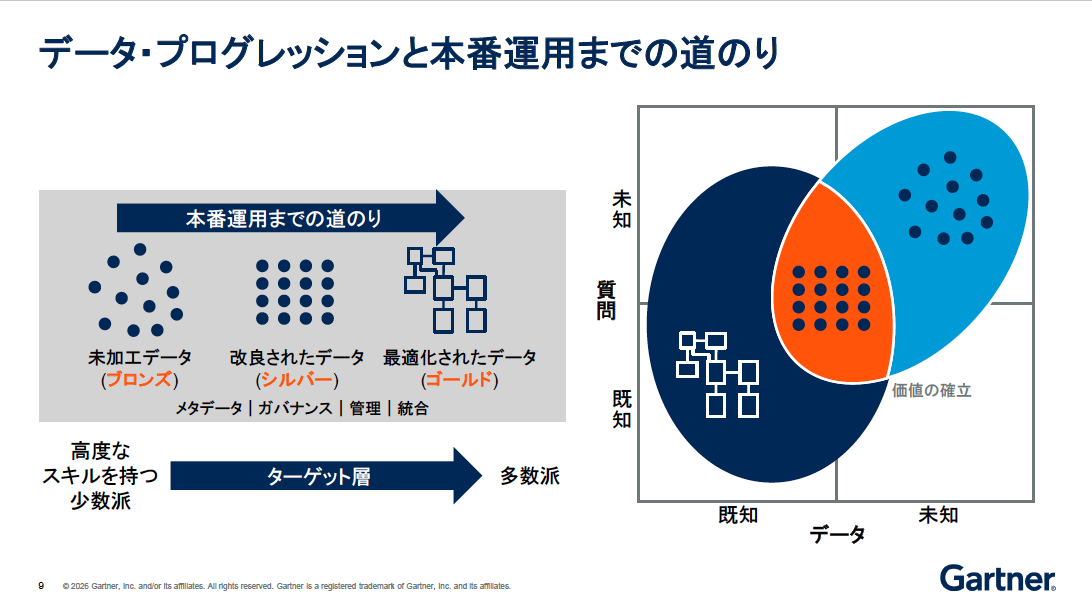
(出典:Gartner(2026年5月))
「データレイクハウス」はどこが優れているのか?
データレイクとデータウェアハウスを別々に運用すると、無駄が生じる。たとえば、レイクでデータを加工する。その後、ウェアハウスへ転送し、再び独自の形式に合わせて変換する。このように、別々のシステムで似たような作業が二重に発生するためだ。この重なりを1つの基盤に統合したのがデータレイクハウスである。ポア氏はこれを「データレイクのような柔軟さと、データウェアハウスのようにビジネス現場で信頼して使える最適化を組み合わせた融合環境」だと説明する。
重複の大きさは、3つの基盤を別々に抱える大企業を思い浮かべると分かりやすい。運用データストア(ODS)、データレイク、データウェアハウスの3つだ。プラットフォーム、インフラ、開発、メタデータ管理、セキュリティ、コスト、人材まで、あらゆる要素が三重に必要になる。データレイクハウスは、これらを1つにまとめる。
データレイクハウスは複数の層で成り立つ。土台となるのはクラウドのオブジェクトストレージだ。その上に、Apache ParquetやApache Avroといった形式のファイルやフォルダ群からなる層が重なる。
鍵となるのが、ここに加わるオープンテーブルフォーマット(OTF)という層である。大量のファイル群を直接操作してデータの整合性を保つ管理作業は、本来多大な手間と複雑さを伴う。しかしこのOTF層を挟むことで、ユーザーは裏側のファイル構造を意識せず、すべてのデータを通常のデータベースのように扱える。
これらの層に加えて、周辺ツール群も組み合わさる。具体的には、データを呼び出すクエリエンジン、処理の流れを制御するオーケストレーションツール、メタデータを管理するデータカタログなどだ。データカタログは、行や列ごとの細かなアクセス制御も担う。

(出典:Gartner(2026年5月))
採用率65%のデータレイクハウス、その先の2つとは?
データレイクハウスは、今や分析の土台となるデータストアになりつつある。ポア氏はこれを「論理データウェアハウス」の後継と位置づける。論理データウェアハウスとは、複数のデータ基盤を1つの論理的な窓口からまとめて扱う考え方で、かつてガートナーが提唱したものだ。ガートナーが2025年に実施した調査では、顧客企業のデータレイクハウス採用率は65%に達した。AIへの備えが進んだ企業ほど、データレイクハウスを導入している傾向が強いという。
今後の動きとして、市場では大きな統合が進みつつある。たとえばデータウェアハウスのベンダーだったSnowflakeは、OTFへの対応を通じてデータレイクハウスへと対応領域を広げた。これまで別々だった製品が、1つにまとまりつつある。
その先にあるとされるのが、「データファブリック」と「データエコシステム」だ。データファブリックは、メタデータとAIを生かして散在するデータ基盤を高度につなぎ合わせ、統合や運用の手間を減らす考え方を指す。データエコシステムはさらに進んで、あらゆるアプリケーションがデータを中心に組み上がる将来像である。いずれも有望だが、実際に作り上げるのは容易ではない。
統合には副作用もある。一部の機能はまだ成熟しておらず、ベンダーロックインの懸念もつきまとう。ポア氏は、その先に望ましい将来像があると説く。「特定のベンダーに縛られず、必要に応じて部品を入れ替えられる。それが目指すべきデータ環境の姿です」。
データレイクハウスを検討するときは、こうした先々の流れも合わせて見ておきたい。自社にとってデータレイクハウスが役立つのか、それともデータレイクとデータウェアハウスを別々に運用し続けるべきか。判断の助けになるはずだ。
※ 本記事は2026年5月19~21日に開催された「ガートナー データ&アナリティクス サミット」の講演内容をもとに再構成したものです。
Googleで見つけやすく
共有する
-
1
-
2
-
0
-
0
-
0
BI・データレイク・DWH・マイニングのおすすめコンテンツ
関連タグ
タグをフォローすると最新情報が表示されます
あなたの投稿
PR
PR
PR
