- 2026/07/01 掲載
万能だったはずのデータレイクはなぜ“沼”に?採用率65%の本命「レイクハウス」の次
データウェアハウス、データレイク、データレイクハウス──。企業のデータ分析基盤は、用途やデータの性質に応じて選択肢が広がってきた。一方で、データレイクを単独で使うモデルは、品質管理やガバナンスの難しさから限界を迎えつつある。本記事では、各基盤の役割を整理し、今データレイクハウスへの統合が進んでいる理由を解説する。
(出典:Gartner(2026年5月))
20年以上王道だった「データウェアハウス」、なぜ限界?
企業のデータ分析を長く支えてきたのは、データウェアハウスだった。ガートナー シニア ディレクター, アナリスト、プラサード・ポア氏は「データウェアハウスは、20年以上にわたってデータ分析の中心でした」と語る。
ガートナー
シニア ディレクター, アナリスト
プラサード・ポア氏
シニア ディレクター, アナリスト
プラサード・ポア氏
一方、データレイクは単体としてはまもなく陳腐化すると見込まれており、データレイクハウスやオープンテーブルフォーマット(OTF)が台頭してきた。データレイクハウスの位置づけを理解するうえで、データウェアハウスとデータレイクそれぞれの特徴を先に押さえておこう。
データウェアハウスとは、分析やレポート作成のために整えたデータを集める仕組みだ。CRMやERPといった業務システムから生データを抜き出し、それを加工し、分析しやすい形に整えてデータベースに格納する。売上や収益のレポートなど、目的が明確な用途で力を発揮してきた。
ただし限界もある。従来のデータウェアハウスは構造化データ、つまり表形式に整理されたデータを前提に作られており、画像やテキスト、ソーシャルメディアの投稿といった非構造化データや機械学習の用途には向いていないのだ。
そこで登場したのがデータレイクだが、データレイクも別の問題を抱えている。
万能に見えた「データレイク」が直面した“沼”
データレイクは、構造化か非構造化かを問わず、大量のデータを安価なハードウェア上に取り込めるようにした仕組みである。当初はHadoopベースで構築され、後にクラウドのオブジェクトストレージ上にも作られるようになった。しかしデータレイクは、データの品質やガバナンス、リネージの管理が難しかった。整理されないままデータが放り込まれ、誰も中身を信頼できない「データスワンプ(データの沼)」に陥る例も相次いだ。
ポア氏は「単体で運用するデータレイクは、もはや過去のものになりつつあります」と語る。実際、多くの企業はデータウェアハウスと併用するか、データレイクハウスへと移行しつつある。
データウェアハウス、データレイクは「2軸」で役割分けする
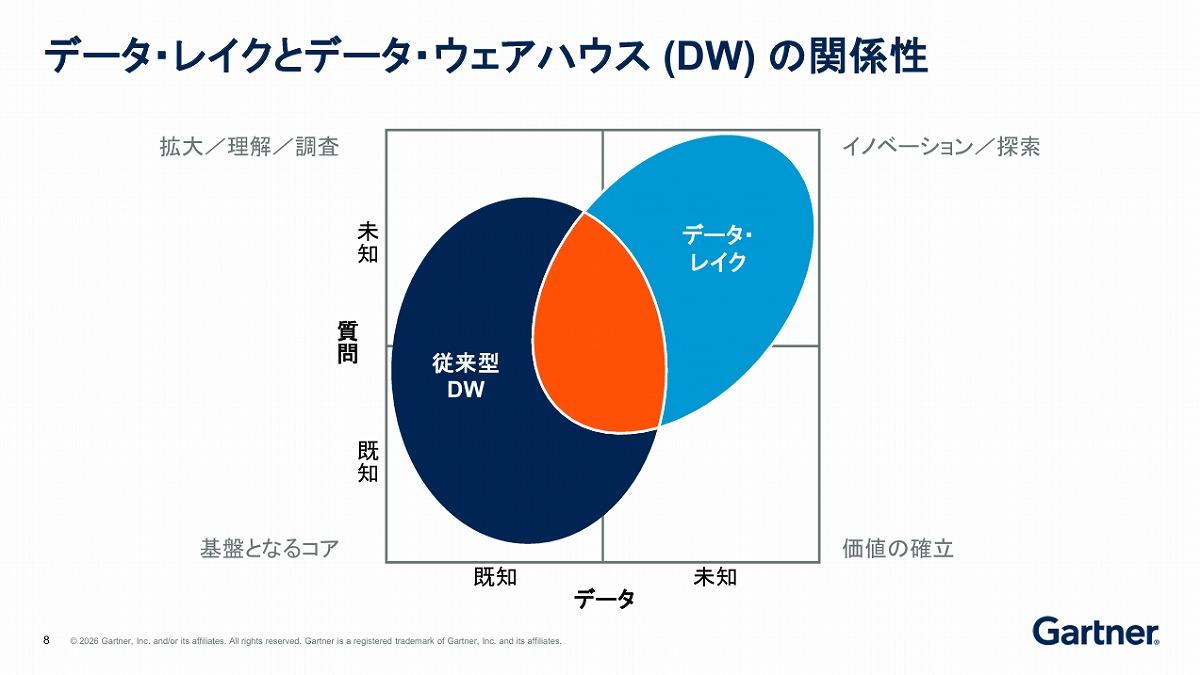
データウェアハウスとデータレイク、それぞれの役割の違いは、「データ」と「質問」の2軸で整理できる(冒頭の図1)。「データ」には、すでに手元にある「既知のデータ」と、まだ取得していない、あるいは手元にあっても全く活用していない「未知のデータ」がある。未知のデータには、ソーシャルメディアのような社外のデータや、社内にありながら活用できていないデータが含まれる。「質問」にも、何を知りたいかが明確な「既知の質問」と、探索的な「未知の質問」がある。
「既知のデータ」と「既知の質問」の組み合わせは、売上レポートのような典型的な用途だ。ここはデータウェアハウスが得意とする領域である。
「既知のデータ」に「未知の質問」を投げかける用途、たとえば顧客の行動パターンを調べるような場合も、データウェアハウスがまかなえる。
また、「未知のデータ」に対して「既知の質問」を投げかける用途もある。たとえば「既存の顧客が自社製品を他人に勧める可能性はどれくらいか」といった分析だ。
一方、「未知のデータ」と「未知の質問」の組み合わせは、機械学習やAIを用いてデータから新たな洞察を見つけ出す、あるいは将来を予測するイノベーションの領域にあたる。たとえば「顧客が次に新製品を買う可能性はどれくらいか」といった予測だ。ここを担うのがデータレイクである。 【次ページ】境界線を担う「データレイクハウス」の役割
BI・データレイク・DWH・マイニングのおすすめコンテンツ
関連タグ
タグをフォローすると最新情報が表示されます
あなたの投稿
PR
PR
PR
