- 2026/07/03 掲載
Googleが追加学習不要の予測モデル「TabFM」を発表
グーグルの「BigQuery」を通じてTabFMを提供
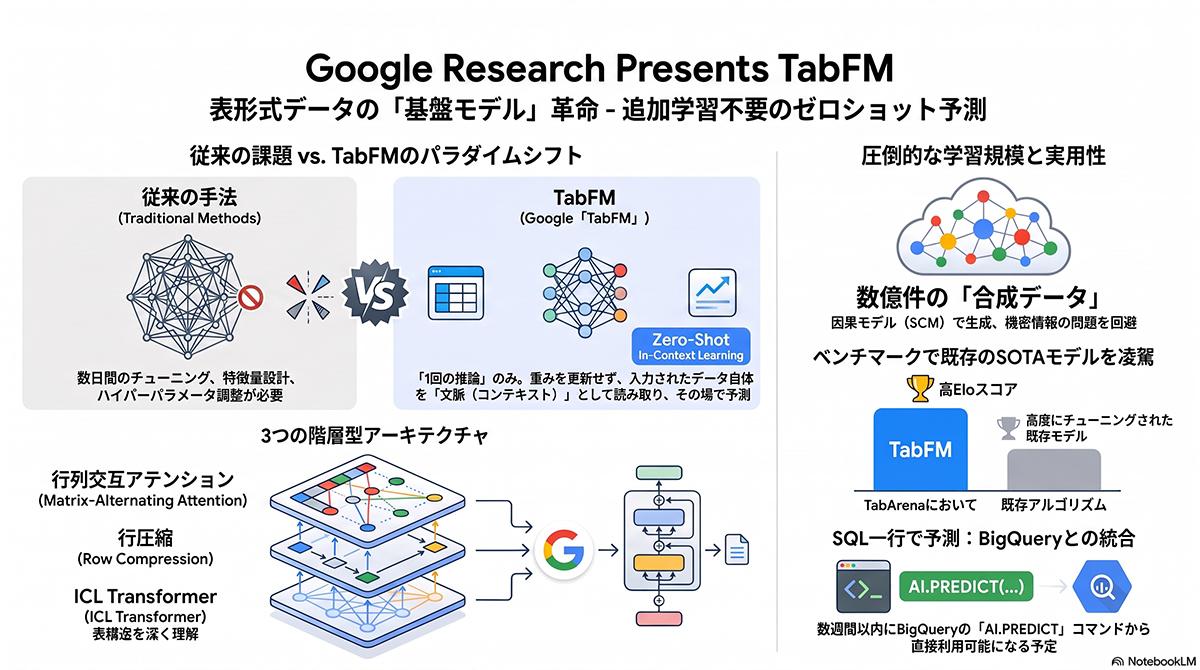
米グーグル(Google Research)は2026年6月30日、表形式データに特化したゼロショットAI基盤モデル「TabFM」を発表した。売上や顧客情報などの表データに対し、事前の追加学習(ファインチューニング)なしで高精度な分類および回帰予測を実行する。数週間以内に同社のデータウェアハウス「BigQuery」のAI.PREDICT機能へ統合される予定だ。

(画像:ビジネス+IT)
【図版付き記事はこちら】Google Research追加学習不要な「GoogleTabFM」発表(図版:ビジネス+IT)
グーグル・リサーチの発表によれば、同モデルは構造的因果モデルから生成された数億件の合成データセットのみで訓練されており、実世界の企業データに対しても高い汎用性を発揮する。評価ベンチマーク「TabArena」の分類および回帰タスクを使用した検証では、事前の調整プロセスなしで既存の業界標準アルゴリズムを上回る精度を記録した。
学習用オープンソースデータの枯渇問題を回避し、合成データのみで学習を完結させた点も技術的な特徴である。これにより機密性の高い実データを学習に用いるプライバシーリスクを抑えつつ、高度な予測能力を獲得している。
モデルの重みデータとソースコードは、すでにHuggingFaceおよびGitHub上で公開されている。さらにグーグルは数週間以内に、自社のデータウェアハウス「BigQuery」を通じてTabFMを提供する方針を固めている。SQLコマンド「AI.PREDICT」から直接モデルを呼び出せる仕組みを整備し、データアナリストが複雑な機械学習の専門知識を持たずとも、日常的なデータ集計作業と同様の手順で高度な予測モデルを実業務に組み込む環境を実現する。
AI・生成AIのおすすめコンテンツ
Googleで見つけやすく
共有する
-
0
-
0
-
0
-
0
-
0
関連タグ
タグをフォローすると最新情報が表示されます
AI・生成AIの関連コンテンツ
あなたの投稿
PR
PR
PR
