- 会員限定
- 2025/06/20 06:10 掲載
Llama 4とは何かをやさしく解説 画期的なオープンウェイトへの期待と厳しい評価のワケ
メタが2025年4月5日、最新の大規模言語モデル「Llama 4(ラマ・フォー)」を発表した。マルチモーダル機能を搭載し、画像・動画認識を標準装備するなど、「Llama 3」から大きな進化を遂げた。Scout、Maverick、Behemothの3モデルをラインナップし、それぞれの用途に応じた選択が可能だ。一方で、同社のベンチマークは公開モデルと異なることが明らかになり、透明性や公平性に対する批判が出ている。さらには最上位モデルBehemothのリリースが延期され、開発チームから多くのエンジニアが離脱していることが原因との報道もある。本稿では、Llama 4の技術的な特徴を解説しつつ、実際のビジネスシーンでどのような力を発揮するのか、その可能性と課題を探る。
英大学院修了後、RPA企業に勤務。大手通信社シンガポール支局で経済・テクノロジーの取材・執筆を担当。その後、Livit Singaporeでクライアント企業のメディア戦略とコンテンツ制作を支援(主にドローン/AI領域)。2026年2月、シンガポールで「SimplyPNG」を設立し、AI画像編集のモデル運用とGPUコスト最適化を手がける。主にEC向け画像処理ワークフローの設計・運用自動化に注力。

(出典:メタ)
Llama 4とは? その概要を解説
メタは2025年4月5日、同社の大規模言語モデル(LLM)ファミリーの最新版となる「Llama 4」をリリースした。Llama 4は、3つのモデル(Scout、Maverick、Behemoth)で構成されており、異なる規模とニーズに対応する設計となっている。このうちScoutとMaverickは即座に開発者向けにダウンロード提供を開始。一方、最大規模のBehemothは当初トレーニング中とされていたが、その後、リリース時期を2025年秋以降に延期したと報じられている
Llama 4の最大の特徴は、ネイティブなマルチモーダル機能を備えている点だろう。テキストだけでなく、画像や動画の入力にも対応するための設計が組み込まれている。全3モデルは「大量のラベルなしテキスト、画像、動画データ」で学習を行い、言語スキルに加えて広範な視覚理解能力を獲得した。これにより、1つのモデルでテキストの分析、画像内容の説明、短い動画クリップに関する推論など、多様なデータタイプの処理が可能となった。
もう1つの重要な特徴は、オープンウェイトモデルとしての位置づけだ。
これは、事前学習済みのモデルファイル(重み)がメタのライセンスの下で誰でも自由にダウンロード可能という意味である。OpenAIのGPTモデルのような有料APIでしかアクセスできないクローズドモデルとは異なり、企業は自社のサーバーやクラウドインスタンスでLlama 4を実行し、プライベートデータでファインチューニングを行い、外部APIに依存することなくアプリケーションに統合できる。
ただし、ライセンスには一定の制限も存在する。月間アクティブユーザーが7億人を超える企業は、メタから特別なライセンスを取得する必要がある。また、規制コンプライアンスの観点から、現時点ではEUでの使用が制限されている。しかし、大多数の組織や開発者にとって、Llama 4は実質的に無料で使用・改変が可能であり、テック大手企業による初のオープンマルチモーダルモデルとして画期的な意味を持つ。
Llama 4の特徴とその技術詳細
ここではLlama 4の技術面の特徴を解説したい。最大の特徴は、Mixture-of-Experts(MoE)アーキテクチャを採用したことだ。従来のAIモデルでは、数十億のパラメータすべてがクエリごとに作動する「密なネットワーク(dense network)」方式を採用していた。一方、MoEモデルは特定のタスクやドメインに特化した小規模な専門家サブネットワークで構成され、入力に応じて必要な専門家のみが作動する仕組み。
たとえばLlama 4 Maverickの場合、128の専門家ネットワークと1つの共有専門家を備え、クエリごとに関連する専門家のみを呼び出す。合計4000億のパラメータを持つが、トークン生成あたりの実際の使用は170億パラメータに抑えられる。同様に、小規模のScoutモデルも16の専門家(総計1090億パラメータ、実動170億パラメータ)を各クエリに使用。これにより、すべてのパラメータはメモリに保存されるものの、各トークンに対してはその一部のみが作動し、計算コストと遅延を大幅に削減している。
もう1つの注目すべき特徴は、巨大なコンテキストウィンドウだ。
特にScoutモデルは1000万トークン(英語約750万ワード、1万5000ページ相当)という膨大なコンテキストをサポート。これは、グーグルのGemini 2.5の100~200万トークンを大きく上回る規模となる。この広大なコンテキストウィンドウにより、理論上、書籍全体や企業の知識ベース全体を一度に入力し、それらの情報を総合的に参照しながら応答できる。ただし1000万トークンすべてが効果的に処理されるのかどうかについての議論が持ち上がっており、利用においては留意する必要がある。
また、メタは高度な学習手法も導入している。Scoutは事前学習で40兆トークン、Maverickは22兆トークンのテキストを処理。これはLlama 3の約2倍の規模となる。さらに、未公開の2兆パラメータを持つBehemothモデルからの「共同蒸留」を活用し、Maverickの能力を強化。その結果、オープンモデルながら、多くのベンチマークテストでOpenAIのGPT-4oやグーグルのGemini 2.0と互角以上の性能を発揮したと報告されている。
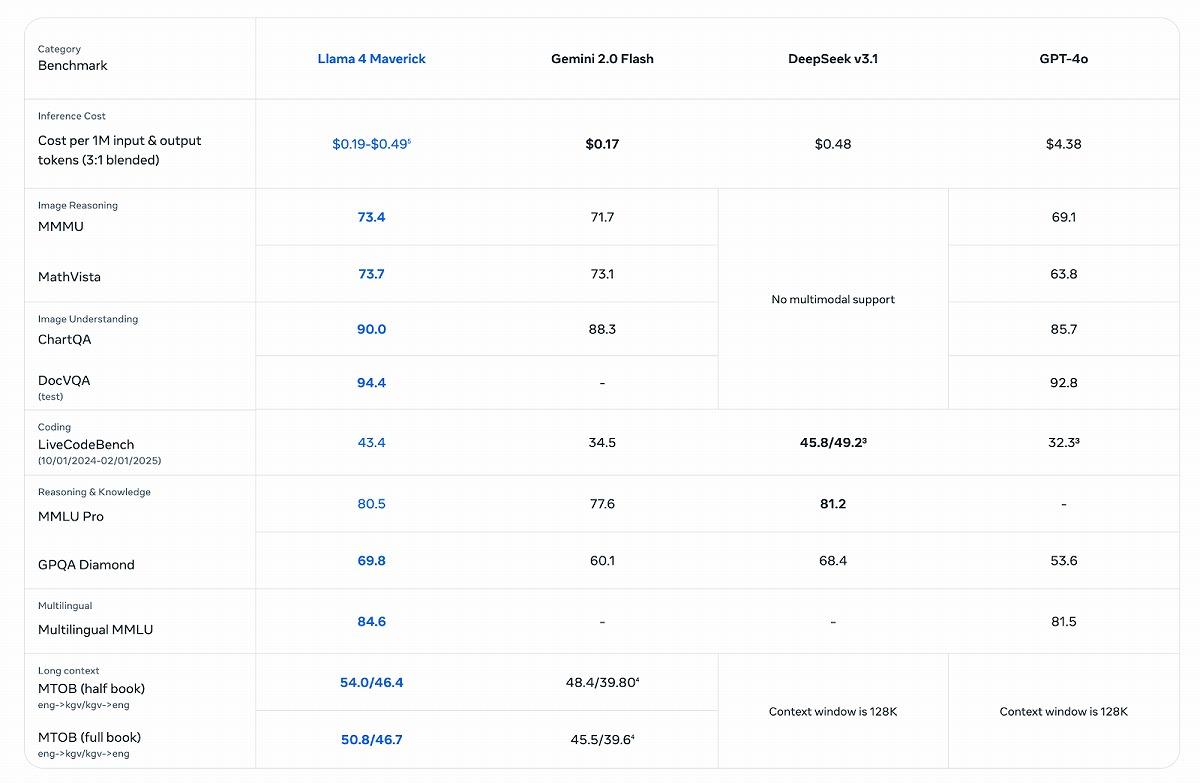
(出典:メタ)
また、BehemothはScoutやMaverickモデルの「教師モデル」として位置づけられており、メタ内部では共同蒸留を通じて各モデルの性能を強化している。特にSTEM領域のベンチマークでは、BehemothがGPT-4.5やClaude 3.5、Gemini 2.0 Proを上回るパフォーマンスを示したとされている。 【次ページ】Llama 4のエンタープライズユースケース
AI・生成AIのおすすめコンテンツ
関連タグ
タグをフォローすると最新情報が表示されます
AI・生成AIの関連コンテンツ
あなたの投稿
PR
PR
PR
