- 会員限定
- 2021/10/14 06:10 掲載
機械翻訳とは何かをわかりやすく解説、AIによる進化とその仕組み
連載:G検定対策講座
そもそも、自然言語処理とは何でしょうか? 私たち人間が日常的に読み書きや会話に使うのが「自然言語」です。「自然言語処理」とは一般的に、自然言語を統計的に解析できる形に変換し、AI(機械)で処理させる一連の技術を指しています。従来からの言語学と統計分析の手法を、機械学習技術と融合させることで実用化されています。この記事では、自然言語処理の応用として注目されている「機械翻訳」の仕組みを解説します。
1987年生、北京生まれ、米国東海岸出身(米国籍)、小学高学年より茨城県育ち、東京大学理学部卒、東京大学大学院理学系研究科博士課程修了(理学博士)、高エネルギー加速器研究機構にて博士研究員(素粒子物理学)を経て、2017年7月より現職。
主要実績:
2010-17 国際学会の発表15件、日本物理学会など国内学会の発表5件 Physics Review D, Physical Review Letters等の科学誌への投稿多数
2018〜 データサイエンスの講座を開設、企業向け研修サービスを開始
2019〜 Tableau Desktop Certified Associate 認定資格習得
研修内容:G検定、機械学習、深層学習、Pythonプログラミング、データ加工、可視化分析(Tableau) 他
得意技:驚異的な行動力と素粒子をも通さない隙のない話術

自然言語処理はなぜ難しいのか
画像認識や音声認識と違って、自然言語処理にディープラーニングを応用する上で、どういうところが難しいと思いますか?コンピューターは数値しか直接的に扱えません。画像認識で解析される画像のピクセル値は数値です。音声認識で解析される音声の振幅も数値化されています。これらに対して、自由形式でつづられている文章は、何を手掛かりに解析すれば良いのかイメージしづらいですね。
自然言語は、画像のピクセル値や音声の振幅とは違って、言語が最初から「物理的な実数値」 として表現できるわけではないです。さらにいうと、高い表現力を持つ反面、文化的なばらつきや曖昧さが、コンピューターで処理する際の「ルール化」を難しくしています。したがって、テキストデータをそのままの形ではなく、機械学習に使えるためには、適切な「前処理」を施す必要があります(注1)。
注1:ここで「物理的な実数値」とは、「物理的に区別可能な状態を数値で表現したもの」の意味です。たとえば、画像は、赤緑青の3色(RGB)のそれぞれのピクセル情報に対応する整数値で表現することができます。
前処理の冒頭で行うことは、単語を「記号」から、ベクトルや行列で計算できる「数値」の世界に変換することです。ただしどんな数値でもよい、というわけではありません。有意義な解析結果を得られるためには、数値ベクトルが以下の条件を持たす必要があります。
- 変換後の数値ベクトルが、単語や文章の特徴を有効に表現できること
- 変換後の数値ベクトルが、単語の意味や単語間の関係性を計算できること
長年の研究の成果として、上記の条件、「単語の意味」や「単語間の関係性」を表現できるモデルが実現されました。これは、ニューラルネットワークを取り入れたWord2Vecです。
【初学者の方に向けたピンポイント解説】
Word2Vecとは、2013 年にトマス・ミコロフ(Tomas Mikolov)により提案された単語の数値化の手法です。Word2Vec は当時の自然言語処理のさまざまな課題を解決し、大規模なテキストデータを用いた学習を初めて実現させるなどしました。
自然言語処理にとって、単語を数値化することは重要な最初のステップてす。ひと昔前はOne-Hot ベクトル表現という「原始的な」な手法が検討され、次第に単語の意味を考慮できるようなより高度な手法が考案されました。One-Hotベクトルとは文章内の単語の1つひとつに、(0,0......,0,1,0,......0,0)のような、全要素のうち1つだけが数値 1、残りはすべて数値 0 であるような長いベクトルを割り当てます。
One-Hotベクトル変換によって、「形式的」に単語を機械で処理可能になったが、実際は機械学習に向きません。なぜならば、同一単語かどうかの判定はできても、単語の意味や関係を表現できないからです。
この問題を解決すべく、各単語をベクトル空間上の点として捉え、意味が近い単語同士をベクトル空間上で距離の近い座標点に対応させる考え方が採用されました。これによって、単語の意味や類似性をベクトルの演算を通じて表現できるようになりました。
Word2Vecは上記の思想に、さらにニューラルネットワークの効率的な学習法を取り入れることにより、高い次元のベクトルからなる膨大なテキストデータでも、現実的な計算時間で計算可能になりました。Word2Vecのすごいところは、計算が速くて精度が良いこと、ベクトルの足し算・引き算を通じて「単語の意味の近さ」を定量的に表現できること、などが挙げられます。
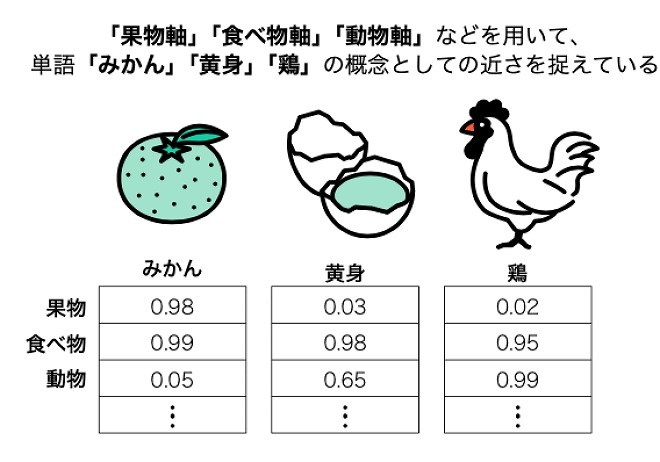
単語の意味をベクトルの距離で表現した例
Word2Vecとは、2013 年にトマス・ミコロフ(Tomas Mikolov)により提案された単語の数値化の手法です。Word2Vec は当時の自然言語処理のさまざまな課題を解決し、大規模なテキストデータを用いた学習を初めて実現させるなどしました。
自然言語処理にとって、単語を数値化することは重要な最初のステップてす。ひと昔前はOne-Hot ベクトル表現という「原始的な」な手法が検討され、次第に単語の意味を考慮できるようなより高度な手法が考案されました。One-Hotベクトルとは文章内の単語の1つひとつに、(0,0......,0,1,0,......0,0)のような、全要素のうち1つだけが数値 1、残りはすべて数値 0 であるような長いベクトルを割り当てます。
One-Hotベクトル変換によって、「形式的」に単語を機械で処理可能になったが、実際は機械学習に向きません。なぜならば、同一単語かどうかの判定はできても、単語の意味や関係を表現できないからです。
この問題を解決すべく、各単語をベクトル空間上の点として捉え、意味が近い単語同士をベクトル空間上で距離の近い座標点に対応させる考え方が採用されました。これによって、単語の意味や類似性をベクトルの演算を通じて表現できるようになりました。
Word2Vecは上記の思想に、さらにニューラルネットワークの効率的な学習法を取り入れることにより、高い次元のベクトルからなる膨大なテキストデータでも、現実的な計算時間で計算可能になりました。Word2Vecのすごいところは、計算が速くて精度が良いこと、ベクトルの足し算・引き算を通じて「単語の意味の近さ」を定量的に表現できること、などが挙げられます。
文章の基本要素である単語を適切に表現できて、初めて、さまざまな自然言語モデルが花咲きました。近年、言語モデルの性能が高速に進化しており、機械翻訳、レコメンド機能、文章生成など多様な場面で実用化されています。
(前提知識)2種類のAI:ルールベースと機械学習
これ以降の内容をよりよく理解していただくために、まず人工知能(AI)の種別について少しお話しします。AIは、ルールベース手法と機械学習手法に分けることができます。
ルールベース
人間が事前に動作ルールや判断基準を明確に指定します。AIはその指示に忠実に従って動作します。指示は「ある条件Aの下で、Bという入力データが入ってきたら、Cを出力しなさい」のようなイメージです。(例:「年収が500万超、年齢が35歳以上であれば、審査通過と見なしなさい」)
人間が事前に動作ルールや判断基準を明確に指定します。AIはその指示に忠実に従って動作します。指示は「ある条件Aの下で、Bという入力データが入ってきたら、Cを出力しなさい」のようなイメージです。(例:「年収が500万超、年齢が35歳以上であれば、審査通過と見なしなさい」)
機械学習
学習データをもとに、汎用的なルールや法則、判断基準の最適値を、「学習」というプロセスを介して自動的に見出します。学習を終えた機械学習モデルを「学習済みモデル」と呼びます。
学習データをもとに、汎用的なルールや法則、判断基準の最適値を、「学習」というプロセスを介して自動的に見出します。学習を終えた機械学習モデルを「学習済みモデル」と呼びます。
2000年以降、インターネットの普及によりデータの流通と収集が容易になりました。「ビッグデータ」を学習に活用できるようになったことが、機械学習の普及に貢献しました。
機械翻訳の歴史
機械翻訳は自然言語処理の分野全体の進化にモチベーションを与えた存在の1つです。以下では、これまでに開発された3種類の機械翻訳の手法をそれぞれ解説してから、3番目の「ニューラル機械翻訳」の仕組みについて詳細に記述します。1.ルールベース機械翻訳
機械学習が普及する2000年代より前のAIはルールベース型がほとんどでした。初期の機械翻訳にもルールベース型でした。人間が事前に両言語に関する辞書や文法集を用意します。この「辞書」(=「翻訳マニュアル」)と照合しながらコンピューターが訳文を出力します。
ルールベース機械翻訳のよいところは、翻訳の根拠を説明できることです。開発当時は限定的な用途に限っては役に立っていました。難しいところは以下です。
- 事前に複雑なルールを大量に登録する作業はコストが高い
- 単語の意味を単に対応させているので、文脈を考慮できず、不自然な翻訳文になりやすい
2.統計的機械翻訳
次に、コンピューターがある意味で、自ら辞書を学習する「統計的機械翻訳」の手法が提案され、1990年代になると主流になってきました。統計モデルの学習を通じて訳文を出す仕組みです。単純なルールベースに代わって、大量なデータを用いて学習を行えるようになったのが進歩です。
学習データは起点言語の文章(原文)と目標言語の文章(訳文)のペアを大量に集めた「対訳コーパス」です。この大量な文章データを結びつける巨大な確率テーブルを計算します。新しい文章が入力された際には計算された確率テーブルを見て最適な(もっともらしい)翻訳文を探します。
この統計的な手法は、インターネットの普及とデータ処理に使うハードウェアの進歩の恩恵を受けて発達できたわけです。実際、両言語に翻訳された政府の書類や国連の議事録など、ウェブ上から取得された対訳データセットが学習に活用されていました。
Google翻訳も、サービス開始の2006年から2016年までの10年間は、上記のような統計的な翻訳方式を採用していました。
ルールベース手法に比べて、手動で対訳マニュアルを準備するコストが削減できました。しかし、統計的な手法でも、システムを高性能にするには大量の対訳データが必要です。また、ルールベース手法に比べて精度がやや上達したものの、相変わらず不自然な訳が少なくなったのです。

画像をクリックすると購入ページに移動します
2016年に、グーグルがニューラル機械翻訳システムであるGoogleニューラル機械翻訳(Google Neural Machine Translation ; GNMT)を発表し、これが機械翻訳に飛躍的な進歩をもたらしました。
開発当初、GNMTに組み込まれているのは、RNNの対から構成されるエンコーダ・デコーダモデルでした(RNNについてはこの後に詳しく解説します)。エンコーダが翻訳前の文章を読み込んで埋め込み層を用いて分散表現に変換し、隠れ層で特徴表現に変換した活性化値をデコーダに渡します。デコーダを通じて訳文(新しいデータ)を出します。
GNMTが最初に発表されたのは、2016年9月でした。その後は絶えず改良を積み重ねてきました。たとえば、11月のGoogle Research Blogの投稿では、Google翻訳に新しいシステムが組み込まれたことが発表されていました。システムで過去に組み合わされた事例がない言語ペアでも、一方から他方への翻訳ができるようになったということです。
この仕組みを“Zero-Shot-Translation”と呼ばれています。たとえば、日本語と英語の双方、日本語と中国語の双方、この合計4パターンの組み合わせで翻訳するシステムでは、多言語間のパラメータを共有します。
これによって、中国語と日本語の間の翻訳についてはシステムに何も教えていない(=Zero-shot)にもかかわらず、そこそこの精度で日中翻訳ができる能力を獲得します。この新しい改良版のGoogle翻訳は、すでに導入され実用されています。
この10年間あまりで、Google翻訳は、わずか数個の言語から100個以上の言語を扱うまで発展しました。毎日1000億以上の単語を訳しています。数多くの言語のうちの任意の2つの言語の間の翻訳を実現するためには、効率よく橋渡しできるシステムを必要とします。そのため、発展版として以下の論文で発表された新しいグーグル翻訳システムが開発されました。
“Google’s Multilingual Neural Machine Translation System: Enabling Zero-Shot Translation”,
近年、グーグル以外の企業からも、ディープラーニングをベースとした機械翻訳システムも開発されています。
【次ページ】機械翻訳のベーシック構成要素であるSeq2seqモデル
AI・生成AIのおすすめコンテンツ
関連タグ
タグをフォローすると最新情報が表示されます
AI・生成AIの関連コンテンツ
あなたの投稿
PR
PR
PR
