- 2026/06/28 掲載
富士通、Transformerと比べ475倍効率な新LLMアーキテクチャ「PHOTON」を発表
GPUリソース当たりの出力トークンを最大475倍に
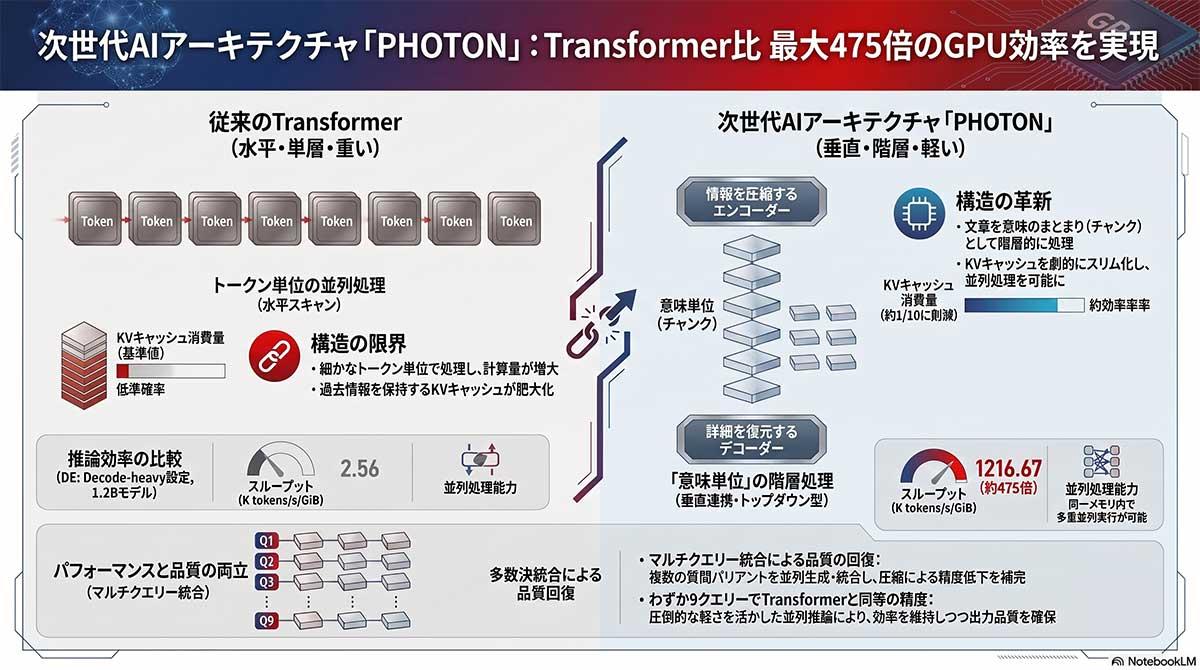
富士通は24日、大規模言語モデル(LLM)の推論にかかる計算効率を向上させる新アーキテクチャ「PHOTON」を発表した。理化学研究所などとの共同開発によるもので、従来のTransformerアーキテクチャと比較してGPUリソース当たりの出力トークン数を最大475倍に引き上げる。AI運用における最大の課題であるインフラコストの削減に直結する技術である。

(画像:ビジネス+IT)
Transformerアーキテクチャは、入力テキストが長くなる場合や多数のクエリを同時に処理する際、過去の情報を保持する「KVキャッシュ」の容量がシーケンス長に比例して増大する。その結果、GPUの処理能力が演算器の限界ではなくメモリ帯域幅の限界によって著しく制約される問題があった。PHOTONはこのメモリ律速によるハードウェアボトルネックを解消する。
【図版付き記事はこちら】富士通、Transformerに比べ475倍効率な新LLMアーキテクチャ「PHOTON」を発表(図版:ビジネス+IT)
同アーキテクチャには「マルチクエリー統合技術(Multi-Query Integration)」が採用されている。入力された一つの問題に対して少しずつ表現を変えた複数のクエリーを自動的に分解・生成し、それぞれに対する回答を並行して出力させる手法である。
得られた複数の回答候補から、多数決(Majority Voting)や最適選択(Best-of-N選択)を用いて最終的な一つの答えを導き出す。1回の推論プロセスで安定した回答を得ることで、処理の効率化に伴うモデル単体の精度低下を補い、生成品質を維持している。
本技術の論文は、2025年12月にプレプリントサーバーのarXivへ公開された。2026年7月に開催される計算言語学分野の国際会議「ACL 2026」にてオーラル発表される。
現在、生成AIの運用ではGPUメモリの逼迫によるインフラコストの高騰が産業全体の課題となっている。PHOTONの計算効率化により、オンプレミス環境や限られたハードウェア資源でも高度なAIの稼働が可能になる。インフラ投資の高さから生成AIの導入を見送っていた企業への波及を推し進める。富士通は現在、法人向けAIプラットフォーム「Kozuchi」や日本語特化のLLM「Takane」、省電力CPU「FUJITSU-MONAKA」の開発も並行して推進している。
AI・生成AIのおすすめコンテンツ
Googleで見つけやすく
共有する
-
0
-
0
-
0
-
0
-
0
関連タグ
タグをフォローすると最新情報が表示されます
AI・生成AIの関連コンテンツ
あなたの投稿
PR
PR
PR
