- 2023/10/31 07:10 掲載
データレイクとは何かをわかりやすく解説、DWHとの違い、メリット、製品比較7選など
連載:デジタル・マーケット・アイ
データが日々増大していく現代、多様なデータを活用した自由度の高い分析が求められている。こうした中で、注目を集めているのがデータレイクだ。データレイクとは、さまざまなソースから得た、構造化/非構造化データやバイナリなどのファイルを含めた多様なデータを一元的に格納できるシステムを言う。本稿ではデータレイクの基本をわかりやすく解説するとともに、成功事例や失敗事例、7つの製品などについて紹介し、自社に導入して活用するためのヒントを提示する。
藤森 みすず
バブル最終入社で20年以上メーカー系SIerに勤務。その後ライターへ。7年ぶりにITの現場に戻り、Eclipseなどのツールを使用。業務で利用するAWSやGitLabなどの知識を基に、教材開発やDX関連など幅広く執筆。

(Photo/Shutterstock.com)
データレイクとは何か
データレイクとは、さまざまなソースから得た、構造化/非構造化データやバイナリなどのファイルを含めた多様なデータを一元的に格納できるシステムのこと。格納されたデータは、必要に応じて多岐にわたる方法で分析される。データレイクのメリットは、データの形式に関係なくデータを原型のまま格納できること。この特性によって、データレイクは構造化データだけでなく、非構造化データも格納できる。
ここで、構造化データと非構造化データの違いに触れておきたい。以下は、構造化データと非構造化データの特徴をまとめた図だ(図1)。

(編集部作成)
まず、構造化データは2次元の表形式などで、値が数値や記号で表されており、1つのテーブルに整理されているのが特徴だ。一方、非構造化データは、テキストや音声、画像、動画といったデータに規則性がなく表形式に変換できないものを指す。また、表形式ではないもののデータに規則性があるケースを半構造化データと呼ぶ。
構造化データと非構造化データにおける定義の違いや例、メリット・デメリットを表にすると以下の通りだ(図2)。

(編集部作成)
構造化データはテーブルなどあらかじめ定義されたモデルに従って整理されているため、検索や分析が容易であることが利点として挙げられる。これに対し、非構造化データはテキストや画像といったあらかじめ定義されたモデルに従わない形式のデータを指しており、多様なデータソースから取得できるという特徴を持つ。
またデータレイクのもう1つの重要なメリットは、必要に応じて構造化・非構造化データを柔軟に分析できる点だ。データレイクに格納されたデータは、そのままの形式で保存されているため、分析の目的に応じて最適な形式に変換して分析できる。
特に企業が保有するデータは非構造化データが圧倒的に多く、構造化データとの割合は2:8ともされている。データレイクが持つ特性により、多様なデータを自由度高く分析することができるようになり、より深い洞察を得ることが可能だ。
データレイクvsデータウェアハウス
データレイクに似たキーワードとして、データウェアハウスがある。どちらも大量のデータを格納し、分析するためのシステムだが、その目的と使用方法には大きな違いがある。データウェアハウスは、目的が明確な主に構造化されたデータを格納している。使用されないデータを保持する可能性が低い。また、データは表形式などで使用されほとんどの社員が扱うことができ、事前に定義されたクエリを実行して分析することが容易になる。
一方、データレイクは、目的が明確ではない多様なデータを格納しているため、多大なストレージ容量を必要とする場合がある。処理されていないデータも扱うこととなるため、専門的な知識を有するデータサイエンティストなどの専門職が主に利用することになる。構造化データだけでなく非構造化データも格納しているため、分析の自由度は高い。
「どちらを使用すべきか?」という疑問が浮かぶが、答えとしては両方とも使ったほうが良い。それぞれの特性を理解することでデータをフル活用できることになる。
良いとこどりの「データレイクハウス」とは
このデータレイクとデータウェアハウスの特性を兼ね備えた新しいデータストレージシステムの概念がある。それがデータレイクハウスだ。データレイクハウスとは、データレイクのようにさまざまな種類のデータを原型のまま格納することができ、データウェアハウスのように高速なクエリ実行と高度な分析機能を取り入れた新たなデータプラットフォームとされる。
データレイクとデータウェアハウスを1つのシステムに一元化することで、データを扱う担当者が異なるシステムにアクセスする必要がなくなり、データを迅速に処理することができるようになるといったメリットがある。
データレイクを構築するための「4つのポイント」
データレイクの導入から利用までの具体的な手順を見ていこう。データの格納から活用、そして運用方法までを解説する。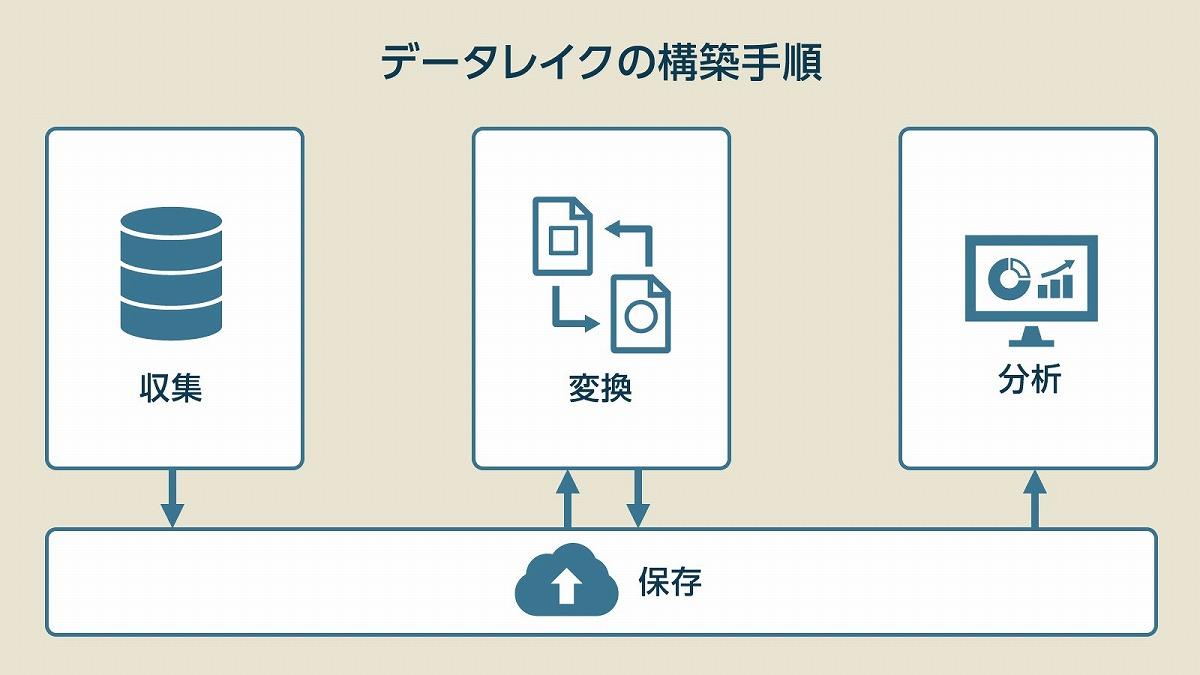
(AWSの資料を基に編集部作成)
データレイクを導入するための基本的な手順は「ストレージのセッティング」、「収集・保存」、「変換」、「分析」となる。
まずデータレイクを格納するためのストレージをセッティングするステップから始まる。ストレージとは、大量の構造化・非構造化データを取り込み、保存するための場所だ。データレイクのストレージには、オープンソースの分散ストレージシステムであるHadoopや、クラウドサービスのAmazon S3、Azure Data Lake Storageなどが挙げられる。
次に、データを収集してデータレイクに格納するステップだ。このステップでは、データソースからデータを抽出・収集し、それをデータレイクに取り込み、格納するためのプロセスだ。データの取り込みは、バッジ処理(一定期間ごとに大量のデータを一度に処理する)やストリーム処理(データが生成されるたびにリアルタイムで処理する)など、データの種類やビジネスの要件に応じて選択する。
データレイクに格納されたデータを分析に活用するためには、データの保存、構造化、そして分析の進め方を理解しなければならない。まずデータを保存する際は、原型のまま保存するため、データの原始性が保たれる。そして、後から必要に応じてさまざまな形式に変換することで、データを利用することが可能となる。
データの構造化は非構造化データを分析可能な形式に変換するプロセスであり、データを分析するための前処理として非常に重要である。このプロセスでは、テキストデータを単語やフレーズに分割したり、画像データを特徴量に変換したりする作業を含む。
データの分析は、構造化されたデータを用いて、ビジネスに有益な洞察を得るためのプロセスだ。このプロセスには、統計的な分析や機械学習モデルの訓練などが含まれる。データの分析結果は、ビジネスの意思決定を支援したり、新たなビジネスチャンスを発見したりするために利用される。
自社で活用するには? 注意すべきポイントとは
データレイクを自社のビジネスに適用するためには、まず自社のビジネス目標とデータ戦略を明確にすることが重要だ。どんな目的で、どのようなデータを分析するのか、データをどのように活用するのかを明確に定義し、それに基づいてデータレイクの設計と構築を行う。そして、データの品質管理やセキュリティ対策、データガバナンスの体制も整備することで、データレイクを効果的に活用することが可能となる。またデータレイクを運用する上で注意すべきポイントとなるのが、データの管理やセキュリティ対策を適切に行う必要がある、ということだ。データの品質を維持するためには、データのクリーニングやバリデーション(妥当性の検証)を定期的に行うことが重要。また、データのセキュリティを確保するためには、アクセス制御やデータ暗号化などの対策を講じなければならない。
そのほかにも、データレイク運用のベストプラクティスとして、「無駄なデータを入れない」「データの変更管理」「管理プロセスを作り、データレイクゾーンを設定する」といったことも必要だろう。これらの運用を適切に行うことで、データレイクはビジネスにとって有益なデータの宝庫となる。
データレイクの「成功事例」と「失敗事例」
次に、データレイクの具体的な成功事例と失敗事例を見てみよう。事例から得られる要点を活用し、自社でデータレイクをどう利用すべきか考えていきたい。■リコーの成功事例
データレイクの成功事例として、リコーの事例を紹介する。リコーは、複合機を中心としたモノを売る企業から、サービス業への転換を目指す過程で、顧客との関係をより深めるためのデータの取得と分析が必要となっていた。
そこで、データレイクのストレージにAmazon S3を採用。データレイクを活用して、コンテナとIoTの基盤を接続するデータ収集基盤を構築した。これにより、誰でも簡単にデータを蓄積できるとともに、迅速な可視化が可能となり、意思決定までのスピードが向上した。
また、AWSを活用したコンテナ基盤を導入することで、開発者がすぐにクラウド環境を払い出し、素早く開発に着手できるようになった。さらにIoTのシステムでは、開発者が自分でメッセージ送受信システムを作らなくても、サービスを始められるようにした。これらの取り組みにより、データ活用の意識が社内で高まり、ビジネス変革が加速したという。
■「データの沼」による失敗事例
一方、データレイクの導入に失敗した事例も存在する。データレイクによく見られる失敗例として挙げられるのが、「データの沼」だ。
データの沼とは、データレイクに大量のデータを格納したものの、データの管理や分析方法について十分な計画を立てず、結果的に見通しの悪い「沼」を作り出してしまう現象を指す。
データの沼を放置すると、データが無秩序に格納されて、必要なデータを探し出すのが困難となり、結果的にデータレイクのメリットを生かせなくなる。言い換えると、適切にメンテナンスされていないデータレイクは使いづらい、ということだ。更新されていないデータは役に立たなくなり、誰にも利用されないまま放置されることとなる。
また、信頼性が担保されていないデータは、判断の根拠に使えない。このことから学ぶべき教訓は、データレイクを導入する際に、データの管理方法や分析方法について事前に計画を立て、適切な運用を継続的に行うことが重要である、ということだ。
データレイクの「7つの製品」を一覧
ここではデータレイクに関連する製品を一覧で簡単に紹介しよう。(順不同)データレイクと関連して多くの人が想起するソフトウェア。Apache Hadoopプロジェクトが開発したオープンソースソフトウェアであり、オープンソースであることから低コストでデータレイクを構築できる。
Amazon S3(Amazon Simple Storage Service)を使って、データレイクを構築することができる。AWSでは、Amazon S3、AWS Lake Formation、Amazon Athena、Amazon EMR、および AWS Glueなどを組み合わせてデータレイクを構築することを推奨している。
Cloud Storageは、Google Cloud Platform(GCP)が提供するサービスで、Google Cloudに含まれるストレージサービス。Google Cloudの画像認識機能を用いて画像検索できるなど、Googleの各種サービスと連携させることで、より効果的なデータ分析が可能となる。
Azure Data Lake Storageは、ビッグデータ分析用のデータレイクとして、マイクロソフトが提供しているサービス。マイクロソフトのアーキテクチャと親和性が高く、Microsoft Entra ID (旧 Azure Active Directory)やロールベースのアクセス制御 (RBAC)を使用してデータを認証できる。多様なアプリケーションから得た構造化データ・非構造化データを保管でき、特にサイバーセキュリティの研究と開発に年間10億ドル超を投資するなど、セキュリティ強化に注力している。
Cloudera社と協働し、データレイクの構築をサポートしている。またデータの収集や分析、AI活用を簡素化・自動化するIBM Cloud Pak for Dataなどのサービスも提供している。
Oracle Cloud Infrastructure Object Storage(OCI Object Storage)は、Oracleが提供する費用対効果に優れたストレージサービス。こちらもストレージサービスなので、この上でデータレイクを構築できる。OCI Data Integration、OCI GoldenGate、または OCI Streamingを利用してほかのデータを取り込んだり、Oracle Autonomous Data Warehouse、MySQL HeatWaveなどのデータベース、Oracle Analytics Cloudなどの分析および機械学習ツール、Apache Sparkなどによる分析ツールと統合された形での利用が可能とうたっている。
Snowflake社が提供するクラウド型データウェアハウスサービス。従来のデータウェアハウスとは異なり、構造化、半構造化、非構造化データをシームレスに利用することができ、Snowflakeを活用することでデータレイクを構築できる。
まとめ
データレイクは、データ駆動の時代において、企業が競争力を維持し、さらには新たな価値を創出するための重要なツールだ。その柔軟性とスケーラビリティにより、データレイクはビジネスデータの活用を一段と進化させる可能性を秘めている。本記事では、データレイクの基本的な概念から、その導入・利用方法、さらには具体的なビジネスへの応用例までを解説した。これらの知識を生かし、自社のビジネスデータ活用を一段と進化させるためにも、データレイクの導入を検討してみてはいかがだろうか。
データ戦略のおすすめコンテンツ
Googleで見つけやすく
共有する
-
1
-
3
-
0
-
0
-
0
関連タグ
タグをフォローすると最新情報が表示されます
あなたの投稿
PR
PR
PR
