- 会員限定
- 2021/12/13 掲載
機械学習で「超重要な」特徴量とは何か? 設計方法などについてわかりやすく解説する
連載:G検定対策講座
機械学習の理解と活用のために不可欠な概念の1つに「特徴量(feature)」があります。この記事ではこの特徴量とは何か、機械学習における特徴量の重要性、予測精度を高める特徴量エンジニアリング(特徴量設計)について解説していきます。
1987年生、北京生まれ、米国東海岸出身(米国籍)、小学高学年より茨城県育ち、東京大学理学部卒、東京大学大学院理学系研究科博士課程修了(理学博士)、高エネルギー加速器研究機構にて博士研究員(素粒子物理学)を経て、2017年7月より現職。
主要実績:
2010-17 国際学会の発表15件、日本物理学会など国内学会の発表5件 Physics Review D, Physical Review Letters等の科学誌への投稿多数
2018〜 データサイエンスの講座を開設、企業向け研修サービスを開始
2019〜 Tableau Desktop Certified Associate 認定資格習得
研修内容:G検定、機械学習、深層学習、Pythonプログラミング、データ加工、可視化分析(Tableau) 他
得意技:驚異的な行動力と素粒子をも通さない隙のない話術

※本記事は『ディープラーニングG検定(ジェネラリスト)最強の合格テキスト[明瞭解説+良質問題]』をもとに再構成したものです。
機械学習の活用で重要な概念「特徴量」
機械学習とは人工知能(AI)の手法の1つであり、大量な学習データをもとに法則やパターンを見出すことです。学習が完了した機械学習プログラムは学習済みモデルと呼びます。では、学習済みモデルの理想的な姿とはどんなものでしょうか?
その答えは、「汎用的なパターンを習得できて、新しいデータに対して、満足できる精度で予測を行える」ことです。
上記でいう「汎用的なパターン」を大量のデータから見つけ出す際に、データのどのような特徴に着目すべきか、を表す変数が「特徴量」です。機械学習モデルを構築するために、特徴量を人が指定しなければいけません。
特徴量は機械学習の活用にとって大変重要な概念です。以下でまずは、「特徴量」を徹底的に理解してもらいたいと思います。
特徴量とは何か?
特徴量とは、一言で表すと、分析対象データの中の、予測の手掛かりとなる変数のことです。皆さんが普段よく扱うExcelファイルやCSVのような表形式のデータを考えましょう。特徴量の大雑把なイメージとして、データの1つの「列」が1つの特徴量に対応すると思ってください。
たとえば、図1にあるようなプロフィールデータから、ある人が特定のサービスに契約するかどうかを予測するケースを想像してください。直感的に、データにある「年齢」「年収」「勤務年数」などが特徴量として使えそうな変数ですね。
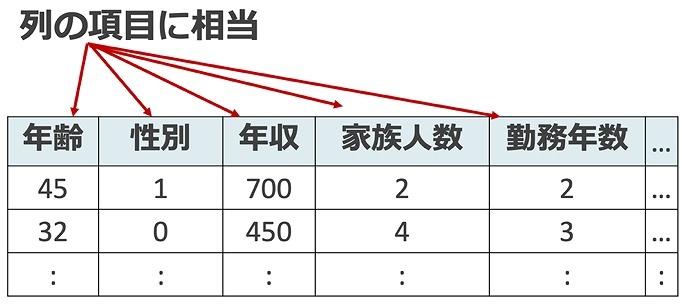
さまざまな具体例を通じて、もっともっと明瞭に、特徴量のイメージを伝えていきましょう。
構造化データの場合の特徴量
構造化データとは、明確に「列」「行」の構造と概念を持っている表型データです。よく使われる Excelや CSVのデータファイルはまさにそうです。「A 行:B 列」を指定することで、1つのデータ要素を確実に指定することが可能です。目視で「どこに何があるか」が列構造で決まっているため、集計、演算、 比較などのデータ操作が比較的行いやすいです。
構造化データの中で、データ分析によく利用されるのは、売上履歴データです。よく聞く「売上予測」の場合、分析担当者が特徴量として指定しうる項目としては、曜日、祝日か平日か、気温、湿度、割引の有無、クーポンの枚数などが挙げられます。
これらを特徴量としてモデルを学習させ、来月に関する同じ変数を学習済みモデルに入力することで、来月の売上を予測することが原理的に可能です。
非構造化データの場合の特徴量
非構造化データは、構造が統一的な「列」と「行」で整理されていません。画像、音声、文章が例として挙げられます(図2)。
画像を機械学習で解析する場合の特徴量は、画素(ピクセル)の集合体です。例えば、腫瘍細胞の症例画像から腫瘍が良性なのか悪性なのかをAIを用いて判定したい場合、患部の画像をRGB情報として読み込み、色合いが近い部分に着目します。

画像をクリックすると購入ページに移動します
音声認識の場合の特徴量は、音波の波形を処理した結果です。自然言語処理の場合、テキストデータにおける特徴量とは、一般的に注目文言の出現頻度や重要度の指標、そして独特な手法で単語を数値化したベクトルなどが使われます。
構造化データに比べて、非構造化データは取得・解釈・利用が難しい場合があります。また、人間による特徴量の指定が難しいです。たとえば、人間が画像を見たときに、明るさや形状の違いが分かっても、ピクセルレベルでどこに着目すればよいのかを判断できません。
しかし、近年はインターネットやソーシャル・メディアなどの普及により、文章、音声、画像が大量に発信されており、非構造化データをうまく利用する技術が重要性を増しています。
そこで、非構造化データには、ニューラルネットワークを適用することが多いです。ニューラルネットワークは、「データのどこを特徴量として学習すべきか」を人間が指定することなく、自らそれを選択できることを特徴とする機械学習の手法です。
【次ページ】過学習と特徴量設計を考える
AI・生成AIのおすすめコンテンツ
関連タグ
タグをフォローすると最新情報が表示されます
AI・生成AIの関連コンテンツ
あなたの投稿
PR
PR
PR
