- 会員限定
- 2024/05/25 掲載
GPT-4oの動画・画像、音声の能力は? これから使える機能、今わかっていることまとめ
OpenAIの新型AIモデル「GPT-4o」で特に注目すべきは、動画理解や音声処理能力です。たとえば45分の専門家向け講義動画をGPT-4oに入力し、数分で正確に要約する能力を示しました。さらに、高品質な画像生成や3Dオブジェクトの生成までこなします。まだ一般開放されていないこれらの技術はどのようなものなのか、いったい何をもたらすのか。『生成AIで世界はこう変わる』の著者で、東大 松尾研究室の今井翔太氏がわかりやすく解説します。
1994年、石川県金沢市生まれ。東京大学 大学院工学系研究科技術経営戦略学専攻 松尾研究室 に所属後、現在はAI研究者。博士(工学、東京大学)。人工知能分野における強化学習の研究、特にマルチエージェント強化学習の研究に従事。ChatGPT登場以降は、大規模言語モデル等の生成AIにおける強化学習の活用に興味。著書に『深層学習教科書 ディープラーニング G検定(ジェネラリスト)公式テキスト 第2版』(翔泳社)、『AI白書2022』(角川アスキー総合研究所)、訳書にR. Sutton著『強化学習(第2版)』(森北出版)など。

(出典:OpenAI)
前回記事はこちら
GPT-4oをわかりやすく解説、専門家が「時代の転換点」と評価するヤバすぎる能力(https://www.sbbit.jp/article/cont1/140613)
Geminiは炎上、ライブで示したGPT-4oの能力
動画・映像の理解については、現時点でOpenAI公式から細かい評価の説明はほとんどないようです。もっとも、この性能の高さについては、OpenAIのライブや、その後に公開されたGPT-4oの動画からも明らかでしょう。実際に示した性能があまりにも高すぎて、逆に具体的で定量的な性能が問題にされていない感すらあります。
余談ですが、グーグルの開発したマルチモーダルモデル「Gemini」もGPT-4oと同じく言語、画像、動画、音声の処理能力を持っており、去年の12月に発表された直後には、人間とGeminiがリアルタイムでやり取りをしながらさまざまなタスクをこなすデモ動画が公開されました。
しかし、このデモ動画は実はリアルタイムでのやり取りではなく、複数の独立したやり取りを編集して、あたかもリアルタイムのように見せかけているということが明らかになり、炎上しました。
OpenAIはGeminiが炎上したやり取りを、言い訳のしようがなく編集も不可能な生放送でやってのけ、動画・映像理解の能力を示したとも言えます。
45分の専門家向け動画をたった数分で要約
GPT-4oの動画・音声処理能力について具体的に示した例はOpenAIの公式解説ページに載っています。この例では、OpenAIの職員が「Maximizing LLM Performance」という内容の45分の講義動画(過去のイベントの講演動画)を、そのままGPT-4oに入力し、その内容を要約させています。
理解の正確さはもちろんですが、GPT-4oは(書かれていないので正確な処理時間は不明ですが)このような動画理解を、遅く見積もっても数分以外に完了できるようです。
人間は普通、映像理解には、映像の長さと同じ時間を要しますが、GPT-4oは極めて短時間で動画を深く理解できます。まして、今回の例の講義動画は研究者であっても理解にかなり時間を要するもので、ここに人間を超える知能の一端が現れています。
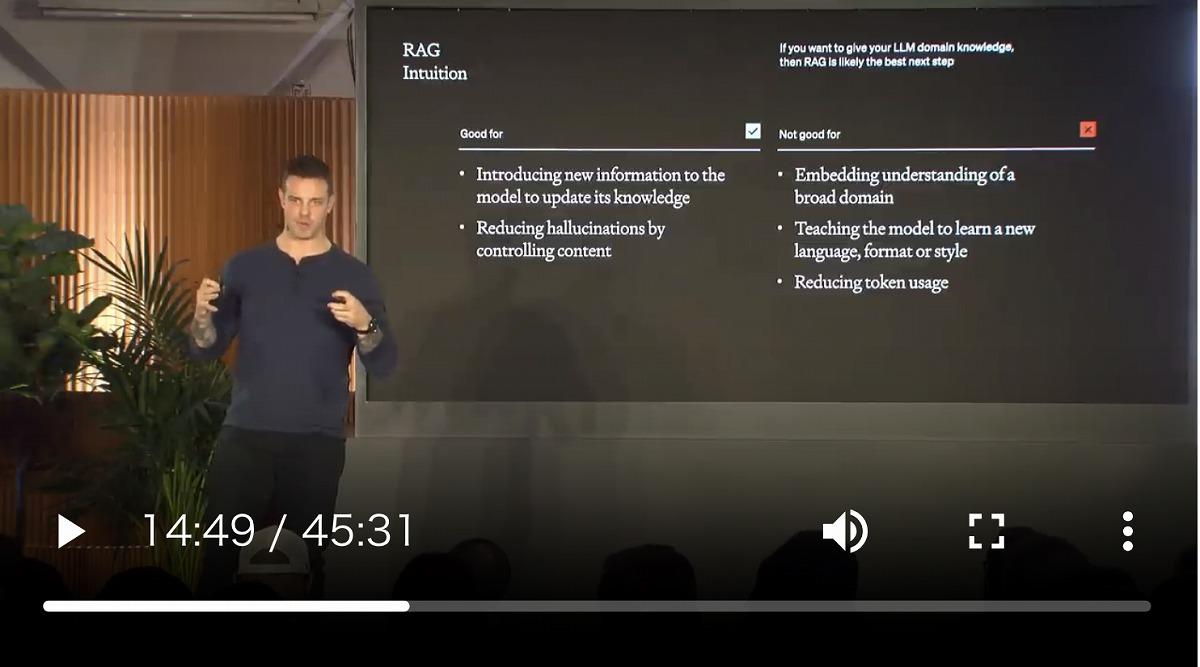
(出典:OpenAI)
(出典:OpenAI)
AI・生成AIのおすすめコンテンツ
関連タグ
タグをフォローすると最新情報が表示されます
AI・生成AIの関連コンテンツ
あなたの投稿
PR
PR
PR
