- 会員限定
- 2017/03/15 掲載
ニューラルネットワークの基礎解説:仕組みや機械学習・ディープラーニングとの関係は
「ニューラルネットワーク(Neural Network:NN)」とは、人間の脳内にある神経細胞(ニューロン)とそのつながり、つまり神経回路網を人工ニューロンという数式的なモデルで表現したものだ。近年、人工知能(AI)領域がブームになっているが、ニューラルネットワークは機械学習や深層学習(ディープラーニング)などを学ぶ際に知っておくべき基本的な仕組みである。NVIDIA(エヌビディア)CUDA & Deep Learning Solution Architect 村上真奈 氏が、ニューラルネットワークを学ぶ入門編として、仕組みや構造、機械学習、ディープラーニングとの関係性、さまざまなアプローチの具体例やディープラーニングの流れなどを解説する。

「ニューラルネットワーク」とは何か?
近年注目されている機械学習や深層学習(ディープラーニング)を学習する際に、おさえておきたいのが「ニューラルネットワーク」という概念だ。機械学習と呼ばれるものには多くの手法があるが、そのひとつがニューラルネットワークを使った手法である。
ニューラルネットワークとは、人間の脳内にある神経細胞(ニューロン)とそのつながり、つまり神経回路網を人工ニューロンという数式的なモデルで表現したものである。
ニューラルネットワークは、入力層、出力層、隠れ層から構成され、層と層の間には、ニューロン同士のつながりの強さを示す重み「W」がある。
「人間の脳の中にあるニューロンは電気信号として情報伝達を行います。その際にシナプスの結合強度(つながりの強さ)によって、情報の伝わりやすさが変わってきます。この結合強度を、人工ニューロンでは重みWで表現します」(村上氏)
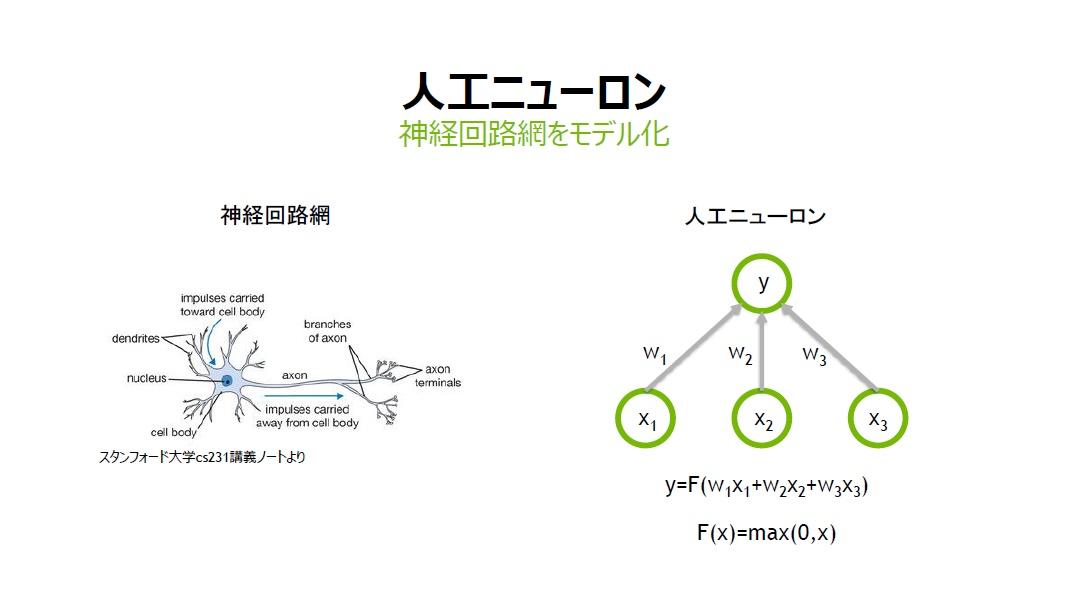
ニューラルネットワークの仕組みと構造
一つひとつの人工ニューロンは単純な仕組みだが、それを多数組み合わせる事で複雑な関数近似を行う事ができるのが、ニューラルネットワークの大きな特徴である。「複雑な関数近似をしなければ分類や回帰ができない場合に、従来型の機械学習手法ではうまくいかないケースも多く、そういった問題に対して、ディープラーニング手法を使用するケースが増えています。
ディープラーニングの手法を用いた事で、従来に比べて飛躍的に認識精度が向上するケースもあり、現在世の中でディープラーニングはたいへん注目されています。最近ではレコメンデーションや自動運転の分野など、幅広い分野で利用されています」(村上氏)
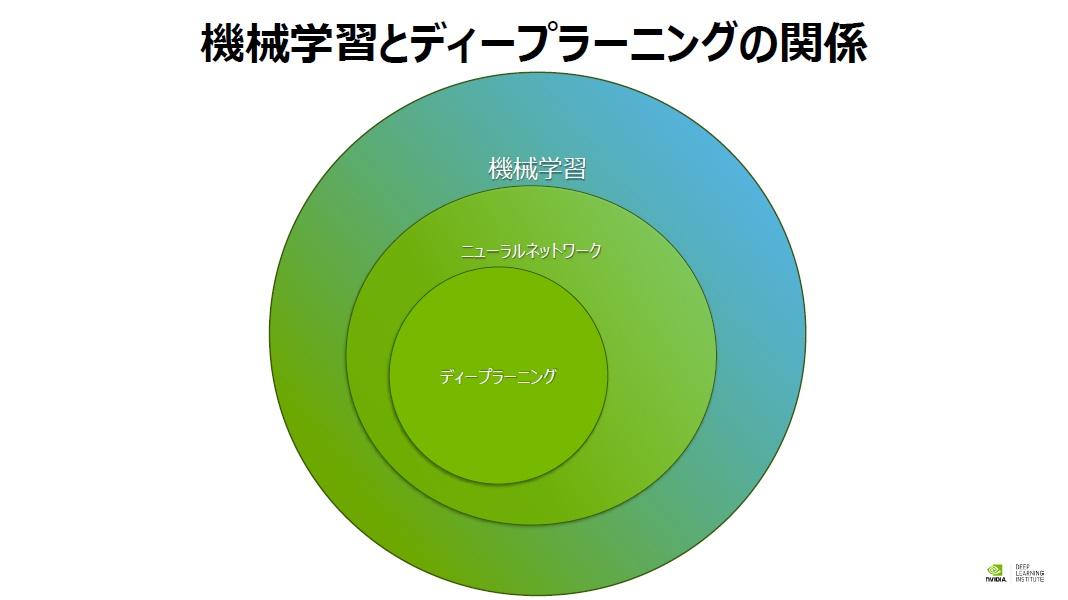
ニューラルネットワークの隠れ層は多層にする事が可能だ。ディープラーニングとは、「隠れ層が多数存在する多層構造のニューラルネットワーク」のことを指す。
村上氏は「入力層」「隠れ層」「出力層」で構成される3層のパーセプトロンを例に説明した。
「今回は、話をシンプルにする為に3層のものを例に説明しますが、たとえば、ディープラーニングで画像分類を行う際は、層の数も多層にし、入力層のサイズは画素数に対応させるケースが多いです。たとえば、28x28ピクセルのグレースケール画像では、28x28x1(RGBカラーの場合は3)の入力になります」(村上氏)
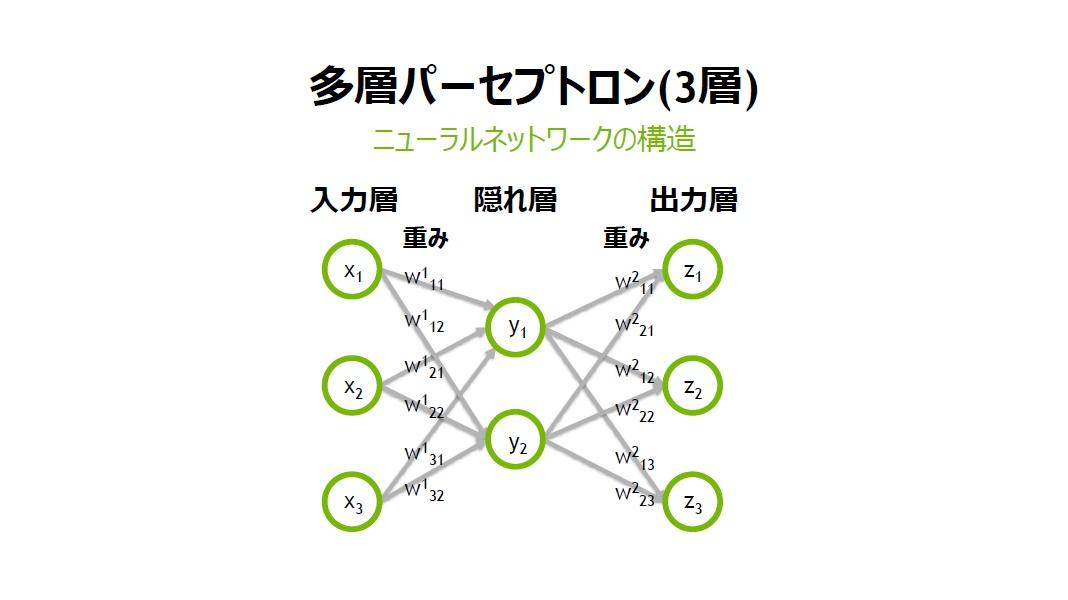
データが入力層のXに入ってくると、その値に重みW1をかけ、Yに結果を出力する。そして今度は、先ほど計算したYの値を入力として重みW2をかけ出力層のZに書き出す。重みW1およびW2の値によって出力結果は異なってくる。
「たとえば、z1が0.8という出力になったとします。しかし本当はz1の出力を0.5にしたい場合、一体どうすればよいでしょうか? その結果に近づけるために、重みのW1とW2を調整していけばよいのです」(村上氏)
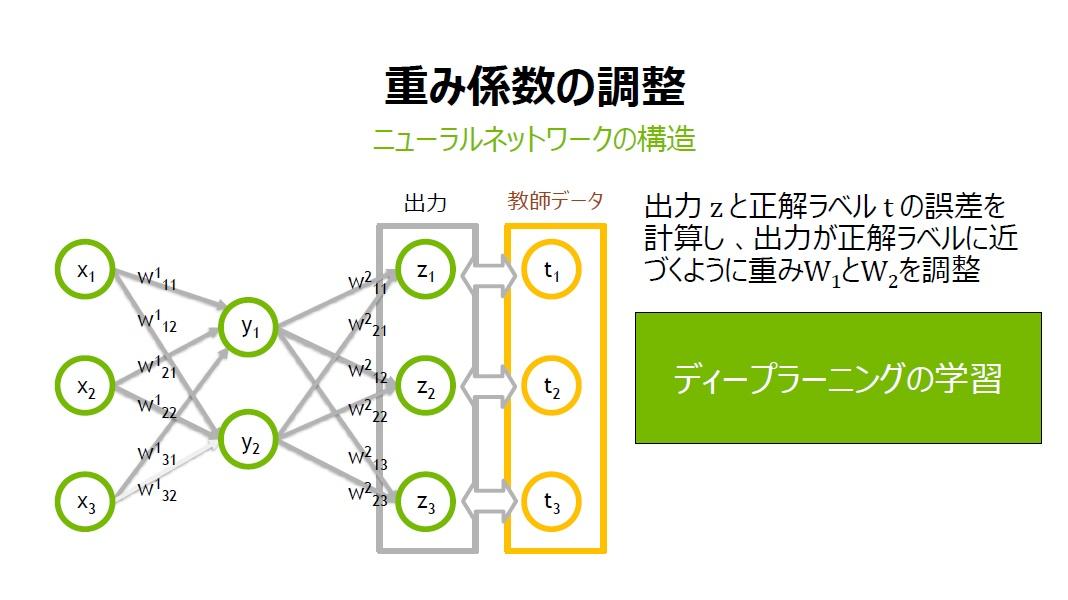
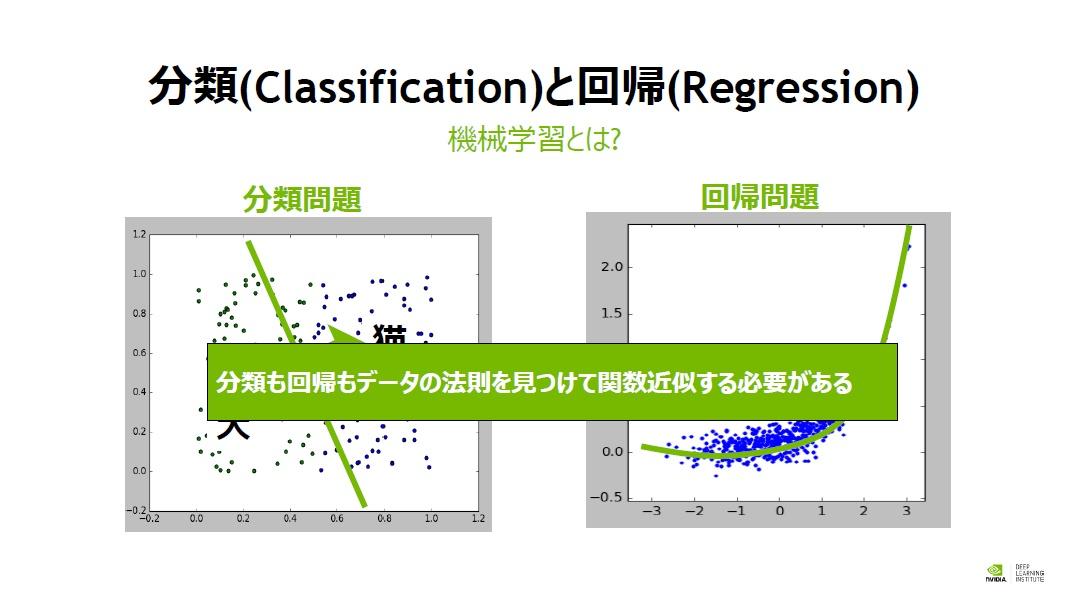
分類と回帰の違いとは
もう一つ、ディープラーニングを理解するために知っておきたいのが「分類(Classification)」と「回帰(Regression)」である。分類問題と回帰問題、どちらもデータに法則性を見つけ、関数近似を行う必要があるという点は共通だ。ディープラーニング手法は分類問題でも回帰問題でもよく使われる。
分類問題の事例には、たとえば犬と猫の画像を推論することなどがある。これに対して回帰問題の事例には、某社の1か月後の株価予測などがある。
分類問題では、分布データをどこかで線引きする問題であり、たとえば異常データと正常データを見分ける事に使用する事ができる。データの分布が一次関数で境界を近似できるような簡単なものであればよいが、多くのケースではデータがバラバラに分布して法則性を見つけるのが難しい。

CUDA & Deep Learning Solution Architect
村上真奈 氏
「そういったデータに法則性が見つけづらく、複雑な関数近似をしなければ分類できない場合に、ディープラーニング手法を用います」(村上氏)
さまざまな種類のアプローチ
ニューラルネットワークの各層の重みを少しずつ調整し、正解ラベルとの誤差を小さくする事を、ディープラーニングでは「学習」と呼ぶ。村上氏は、「学習には『誤差逆伝播法』が使われており、重みの更新には最適化手法の一つである『勾配降下法』が使われている」と説明した。これは、すでに「TensorFlow」「Chainer」「Caffe」といったディープラーニング用のフレームワークを利用しているユーザーには耳慣れたものだろう。
勾配降下法には、確率的勾配降下法をはじめ、いくつかの種類が存在する。いわゆる「Solver」の設定では、この勾配降下法のアルゴリズムをどれにするのかの選択を行っている。
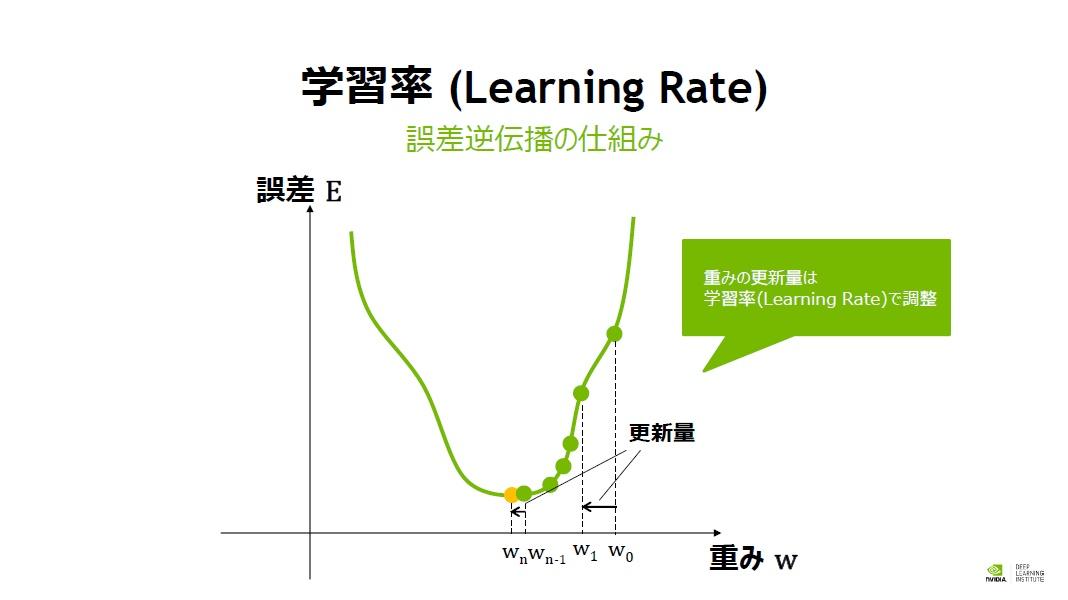
勾配降下法の原理は次の通りだ。現在の値と教師データが近い場合は、誤差が小さくなる。これをヒントに最適化していく。つまり最も誤差が小さい値が最適解になる。
「現在値から誤差が小さくなるように、重みを増加させるのか、あるいは減少させたほうがよいのか。それを知るために変化量を調べる必要があります。そこで微分して接線の傾きが正か負かを見て、誤差が減る方向に重みの値を更新していきます。その操作をゴールである最適解に近付くように何度も何度も繰り返します。このときの更新量の幅が重要で、学習率(Learning Rate)で決まります」(村上氏)
重みを更新する際には、いくつかの注意点が存在する。最適化がうまくいかないと局所解に陥ってしまう事があるためだ。
局所解に陥らない為に、ディープラーニングの学習時にはさまざまな工夫を行う。たとえば、最初は学習率(Learning Rate)を大きくして重みの更新をどんどん行い、最後の方は学習率を小さくして重みの微調整を行うというように、学習率を変化させる手法を用いる事がある。
また、重みWをあらかじめ別途学習したプレ・トレーニングデータで初期化する手法を用いる事もある。
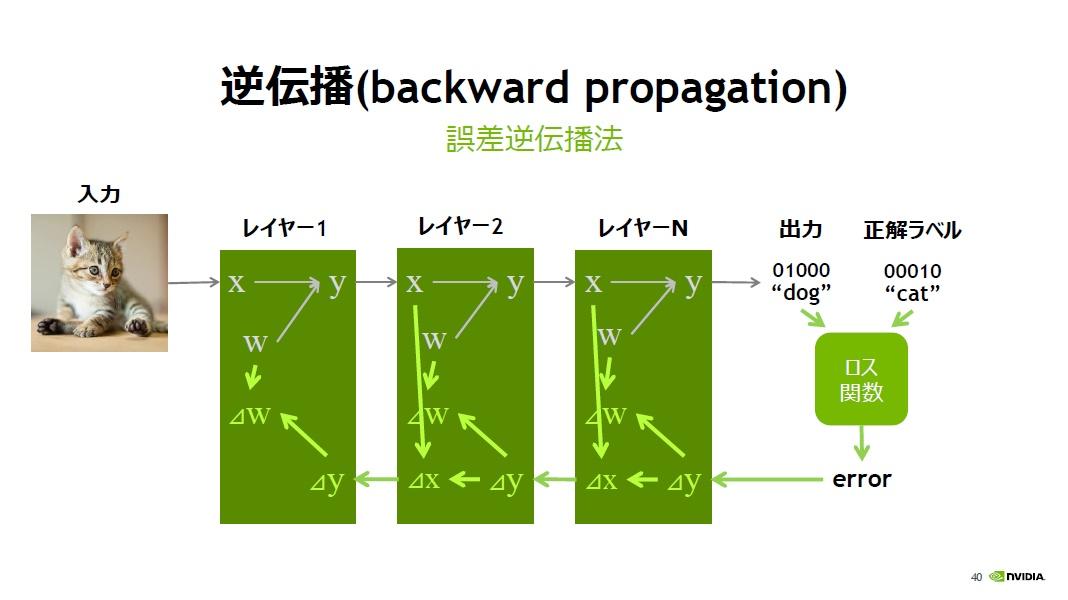
「ディープラーニングの学習では、ニューラルネットワークの入力層にデータを入力し重みをかけて出力するという操作を最終層までN回繰り返します。これをフォワード・プロパゲーションと呼びます」(村上氏)
初期段階では、すぐに期待した通りの答えは出力されないため、正解ラベルと出力値の誤差をとり、誤差を各層に伝播させて正解値に近付くように各層の重みを調整する。この誤差を逆伝播させる事を「Back Propagation(バックプロパゲーション)」と呼ぶ。これが誤差逆伝播法の仕組みだ。
さらに大量の画像データを入力し、精度を高めていくためには、計算能力も時間もかかる。この画像データの処理を1枚ずつやっていたのでは大変だ。そこで、複数枚を同時に処理する「ミニバッチ」という手法も使われる。
【次ページ】画像を分類するニューラルネットワークの具体例
AI・生成AIのおすすめコンテンツ
関連タグ
タグをフォローすると最新情報が表示されます
AI・生成AIの関連コンテンツ
あなたの投稿
PR
PR
PR
