- 会員限定
- 2026/01/27 07:00 掲載
Google、NVIDIAが完成を目指す、フィジカルAIの究極完全体とは?
ロボットが実世界で自律的に行動するために必要な「2つの脳」の融合
2026年、生成AIの次の主戦場として「フィジカルAI」が急速に注目を集めている。デジタル空間に閉じていたAIが、物理的な身体(ロボット)を持ち、現実世界で活動を始めたからだ。しかしながらロボットがこの複雑な実世界で自律的に行動するためには、我々人間と同じく、この世界の理を「予測する脳」と「行動する脳」が必要になる。GoogleやNVIDIAは、この「2つの脳」の開発にしのぎを削り、AIロボの究極完全体を目指し、熾烈な開発競争を行っている。

(画像:ビジネス+IT)
ロボットが実世界で行動するために必要な「2つの脳」とは?
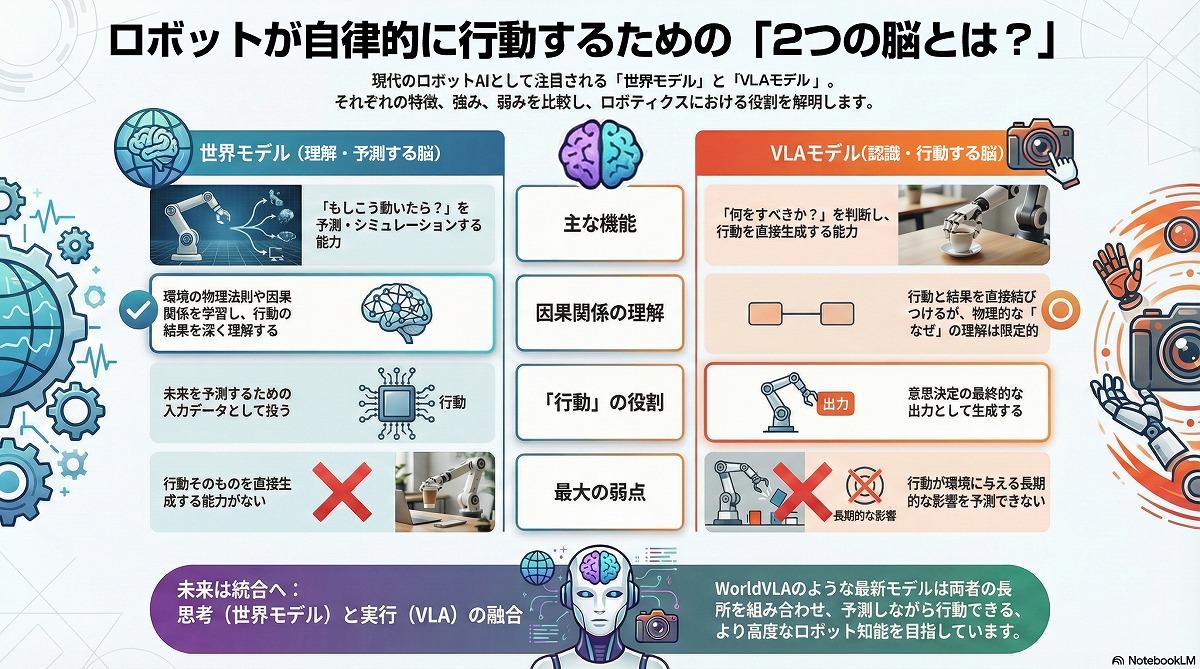
これまでロボット制御には、特定のタスクごとにプログラムを組む必要があった。工場で作業するロボットは、このプログラム下で制御され、動いている。しかしフィジカルAIの進化により、この常識が覆りつつある。ロボットを自律的に行動させる「2つの脳」、それが「VLAモデル」と「世界モデル」だ。VLAモデルは、主に「行動する脳」の役割を担う。VLAモデルとは、画像(Vision)と言語(Language)の理解に加え、ロボットの具体的な動作(Action)を直接生成するAIモデルだ。Google DeepMindが開発した「RT-2」や「Gemini Robotics」がその代表格である。
ロボットが自律的に行動するための「2つの脳」とは?
(画像:ビジネス+IT)
従来のAIが「これはペットボトルです」と認識するだけだったのに対し、VLAモデルは「ペットボトルを掴んで捨てる」という指示に対し、掴む手の角度や握る強さといった命令を直接出力する。
インターネット上の膨大な画像・テキストデータと、ロボットの動作データを同時に学習することで、プログラミングの制御なしに、未知の物体や指示に対応できる汎用性を獲得している。
一方、世界モデル(World Model)は「予測する脳」の役割を担う。いわばAIが「物理世界のシミュレーター」を脳内に持つ技術だ。Google DeepMindの「Genie」やOpenAIの「Sora」に代表されるように、動画や観測データから物理法則や因果関係を学習する。
例えば「グラスを落とせば割れる」「ハンドルを右に切れば車は右へ進む」といった、行動の結果として起こる未来の状態を予測できる。VLAモデルが認識し・行動する役割を担い、世界モデルは行動の結果を理解し・予測する役割を果たす。両者が相互機能することによりロボットは自律的な判断ができるようになる。
ビッグテック「2つの脳」をめぐる熾烈な開発競争
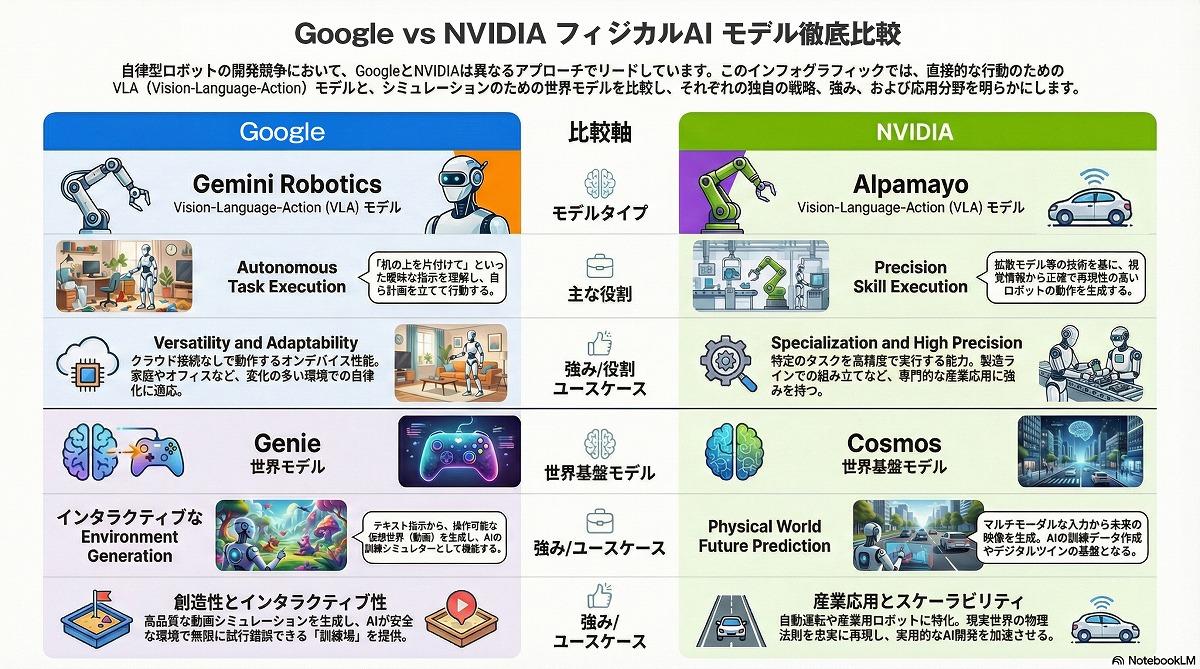
現在、世界のビッグテックは「フィジカルAI」の覇権を巡り、これら「2つの脳」の開発競争を繰り広げている。Google DeepMindは、VLAモデル「RT-2」に加え、マルチモーダルモデル「Gemini」をロボット制御に統合する「Gemini Robotics」を展開。ロボットが周囲の環境を認識し、3D空間内での推論やナビゲーションを行う能力を強化している。
また、1枚の画像から操作可能な3D仮想空間を生成する世界モデル「Genie 2」を発表し、ロボットの学習環境としての活用も視野に入れている。Google DeepMindは、Boston Dynamicsのヒューマノイド・ロボット「ATLAS」に「Gemini Robotics」を搭載し、モデルの実戦投入を図っている。
OpenAIは、動画生成AI「Sora」で培った世界モデルの知見を、ロボット企業Figure AIとの提携を通じて実機に投入。人型ロボット「Figure 01」では、人間との自然な会話とスムーズな動作連携を実演した。
両者の提携はほどなく解消となったが、「VLAモデル」の開発をリードする「Physical Intelligence」やロボティクス企業「1X」などに出資するなど、この分野への野心を隠していない。
NVIDIAは、ロボット開発のための基盤モデル「Project GR00T」を発表。デジタルツイン環境「Omniverse」内で世界モデルを活用したシミュレーションを行い、その学習結果を現実のロボットに適用するエコシステムを構築している。
同社はロボティクスや自動運転のために学習可能な世界モデル基盤「NVIDIA Cosmos」を開発、また自動運転やロボティクス制御のための独自VLA「alpamayo」を発表し、この分野への進出を宣言した。
(図版:ビジネス+IT)
さらに、Alibabaグループの研究チームは、VLAと世界モデルを単一のフレームワークに統合した新たなアーキテクチャを提案している。これは、Googleを含む各社が目指す「行動と予測の統合」を具現化する研究の一つとして注目されている。
Alibabaグループも中国のロボティクス企業「Unitree」や自動運転の「Hallo」などと組み、この統合モデルの実証実験を行っている。 【次ページ】「2つの脳」を融合する、フィジカルAIの究極モデルとは?
AI・生成AIのおすすめコンテンツ
関連タグ
タグをフォローすると最新情報が表示されます
AI・生成AIの関連コンテンツ
あなたの投稿
PR
PR
PR
