- 2026/03/15 15:11 掲載
東大と理研、142億パラメータの日本語特化型医療用視覚言語モデルを開発・公開
医療画像と日本語テキストを理解、病院内の閉鎖環境で稼働可能
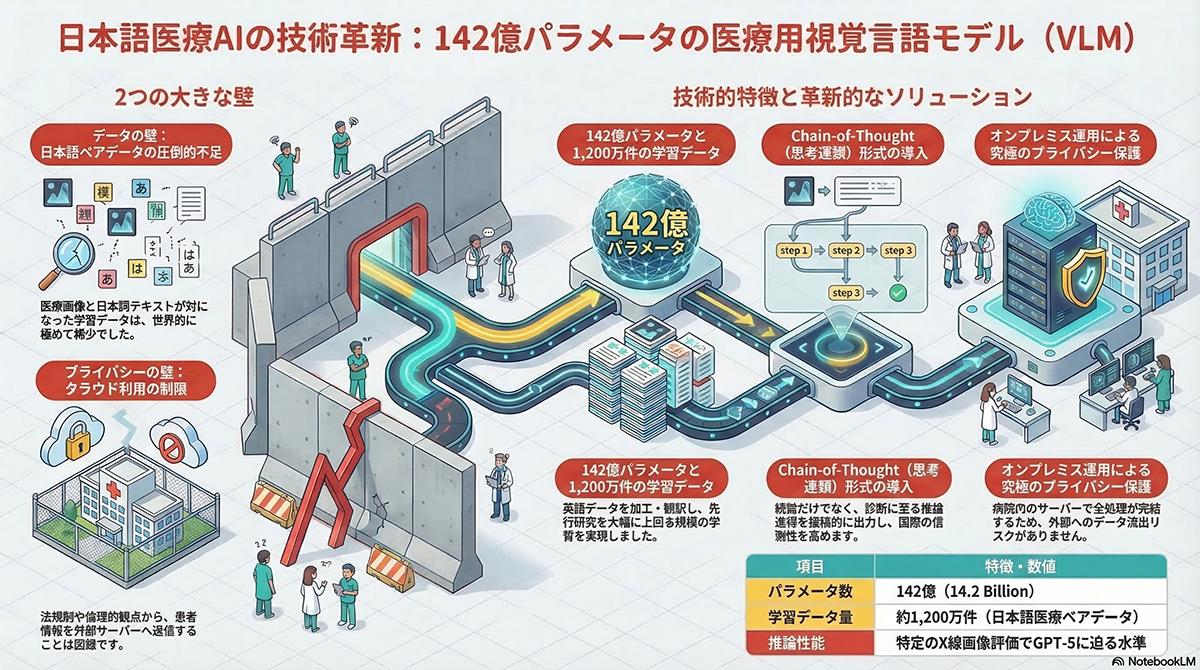
東京大学先端科学技術研究センターと理化学研究所の共同研究グループは2026年3月、142億パラメータを持つ日本語特化型の医療用マルチモーダル基盤モデルを開発したと発表した。本モデルは医療画像と日本語テキストを統合的に理解し、病院内の閉鎖環境で稼働可能な設計となっている。これにより、データのプライバシー保護と診断支援の両立を実現し、国内の医療AI分野におけるオープンな基盤として活用される。

(画像:ビジネス+IT)
東京大学と理化学研究所「医療特化型視覚言語AIモデル」発表
(図版:ビジネス+IT)
従来の医療AIは画像分類など単一の用途に特化したものが主流であったが、本モデルは医師の思考プロセスに近い多角的な情報処理を可能にした。開発における最大の課題は、高品質な医療画像と日本語テキストのペアデータが不足していることであった。研究グループはこれを克服するため、MIMIC-CXRなどの英語圏で公開されている医療画像データセットを活用し、高度な機械翻訳と専門家による修正を加えることで、約1,200万件に及ぶ日本語医療学習データを構築した。
さらに、学習プロセスにおいて利用制限のある既存の大規模言語モデルを使用せず、独自のデータ生成手法を採用したことで、商用利用やオープンな研究を妨げない基盤モデルとしての要件を満たしている。技術的な特徴として、推論の過程を段階的に出力する思考連鎖形式を導入している点が挙げられる。これにより、モデルは画像内の解剖学的な異常所見を特定し、医学的知識と照合した上で最終的な鑑別診断を提示する一連の論理ステップを明示する。
この機能は、診断根拠の透明性を高めるとともに、若手医師の教育ツールとしても機能する。また、142億パラメータというモデル規模は、高度な推論能力を維持しつつ、計算コストを抑える戦略的な設計に基づいている。これにより、外部ネットワークから切り離された病院内のオンプレミス環境にあるサーバーで動作させることが可能となった。患者の機密性の高い医療データを院外へ持ち出すことなく診断支援を行えるため、厳格なプライバシー保護が求められる日本の医療現場の実情に適合している。
本モデルの開発には理化学研究所のスーパーコンピュータ「富岳」が活用され、膨大な計算資源の最適化が行われた。今後は、放射線科や病理診断科における読影レポートの自動生成による医師の負担軽減や、地域間での医療格差の是正に貢献する設計となっている。研究グループはさらに、各診療科に特化した専門モデルへの分化や、パラメータ数を拡大した超大規模モデルの開発を計画しており、日本の医療AIインフラとしての持続的な発展を目指している。
AI・生成AIのおすすめコンテンツ
Googleで見つけやすく
共有する
-
2
-
3
-
0
-
2
-
0
関連タグ
タグをフォローすると最新情報が表示されます
AI・生成AIの関連コンテンツ
あなたの投稿
PR
PR
PR
