- 会員限定
- 2021/02/25 掲載
DataOps(データオプス)事例、「あるある失敗談」と「成功マニュアル」とは
「データ活用が売上や成果につながらない」、「そもそも社内のデータ活用のフローがぐちゃぐちゃ」など、データ活用のハードルは高い。そこで、多くの企業はデータ活用の在り方を改善すべく「DataOps(データオプス)」を実践しようとするが、失敗に終わってしまうケースは少なくない。本記事では、DataOpsに取り組む企業が陥りがちな「あるある失敗事例」を紹介しつつ、DataOpsを成功に導くための実践的なポイントをまるっと解説したい。

(Photo/Getty Images)
DataOpsの「あるある失敗談」とは
DataOpsとは、社内のデータ活用をスムーズにするために、組織内のデータ管理者と利用者の協力関係を深め、データ活用のプロセスを自動化・効率化することを目指すアプローチです。そんなDataOpsの実践しようと考える際、検討すべきポイントとして、社内の人、組織、カルチャー、テクノロジーなどいくつかの切り口があります。今回は、DataOpsを構成する要素のうち、テクノロジーの部分にフォーカスし、DataOpsを実現するための重要な「データ基盤」について考えてみましょう。実際にデータを扱われている方であれば、経験したことがあるかと思いますが、データを取り扱う上で、よくある課題を3つほど取り上げてみました。
(1)データの所在や形式がすぐに分からない
データを活用したい場合に、欲しいデータの所在、形式、意味が分からないケースです。データがサイロ化されている場合、データを管理している部署に依頼してもデータに関する文書記述が十分でないなどデータ管理がきちんと行われていない場合は調べるのに思いのほか時間とコストがかかるものです。また、同じような名前のデータ項目があり、どれが本当に欲しいデータに該当するのかが分からないというケースもよくあります。
データを活用したい場合に、欲しいデータの所在、形式、意味が分からないケースです。データがサイロ化されている場合、データを管理している部署に依頼してもデータに関する文書記述が十分でないなどデータ管理がきちんと行われていない場合は調べるのに思いのほか時間とコストがかかるものです。また、同じような名前のデータ項目があり、どれが本当に欲しいデータに該当するのかが分からないというケースもよくあります。
(2)必要なデータをすぐに得られない
欲しいデータの所在や形式が明確になったとしても、これらのデータ取り出してデータ分析を行う形式にするためには思いのほか、時間がかかるものです。これこそが、データ分析業務の80パーセントがその準備に割かれると言われている理由です。
また、データ分析ができる形にデータを準備できたとしても、その品質が低ければ、正しい結果を得ることができません。そのような場合にはデータを取得しなおす必要も出てきます。実は米国のある調査会社のレポートでは、データサイエンティストの55%がトレーニングデータの品質/量を最大の課題として挙げています。
欲しいデータの所在や形式が明確になったとしても、これらのデータ取り出してデータ分析を行う形式にするためには思いのほか、時間がかかるものです。これこそが、データ分析業務の80パーセントがその準備に割かれると言われている理由です。
また、データ分析ができる形にデータを準備できたとしても、その品質が低ければ、正しい結果を得ることができません。そのような場合にはデータを取得しなおす必要も出てきます。実は米国のある調査会社のレポートでは、データサイエンティストの55%がトレーニングデータの品質/量を最大の課題として挙げています。
(3)さまざまな種類や規模のデータが扱えない
さまざまな種類や規模のデータが扱えないという問題もあります。多くの機械学習では生データを必要とします。そしてこれらのデータは半構造化、非構造のものが多いです。また、バイナリー形式であるかも知れません。SNSなどのテキストデータやイメージデータが必要な場合もあります。
そしてIoT機器などのデータの量は莫大です。また、機械学習では一般的にトレーニングデータが多いほど、精度が向上するので膨大な量のデータが必要です。たとえば、センサーデータは月あたり数億件から数100億件からなることも稀ではありません。
さまざまな種類や規模のデータが扱えないという問題もあります。多くの機械学習では生データを必要とします。そしてこれらのデータは半構造化、非構造のものが多いです。また、バイナリー形式であるかも知れません。SNSなどのテキストデータやイメージデータが必要な場合もあります。
そしてIoT機器などのデータの量は莫大です。また、機械学習では一般的にトレーニングデータが多いほど、精度が向上するので膨大な量のデータが必要です。たとえば、センサーデータは月あたり数億件から数100億件からなることも稀ではありません。
DataOpsを支える「データ基盤構築」の3ステップ
このような課題を解決するためのデータ基盤構築のステップを解説します。
(出典:オージス総研)
ステップ(1):データストアの整備
まずは、組織や用途ごとに分散したデータを、一元的に管理する基盤に統合するためにデータレイクやデータウェアハウスを構築します。ここにデータレイクとデータウェアハウス違いを簡単にまとめていますので、導入の際の参考にしてください。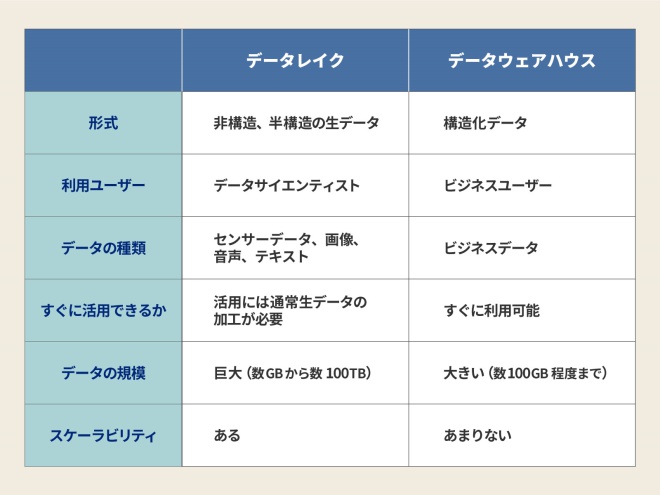
(出典:オージス総研)
このようにデータレイクとデータウェアハウスの用途は異なりますが、部門や用途によってばらばらに管理されていたデータを統合することで、利用者はデータのロケーションを意識することなく、統一的なアクセスを行うことができます。
【次ページ】「データ基盤構築ステップ2~3」、「理想的なデータ基盤」、「DataOps成功の条件(=データ戦略の作り方)」まとめて解説
システム開発総論のおすすめコンテンツ
関連タグ
タグをフォローすると最新情報が表示されます
あなたの投稿
PR
PR
PR
