- 会員限定
- 2023/09/28 掲載
GPT-4とは何か? 仕組み・GPT-3.5との違い・技術的に優れた点をわかりやすく解説
2022年11月に登場し、世界に大きな衝撃を与えたChatGPTでしたが、GPT-3.5が登場した当初は、人間に比べて精度に劣る点も多々見られ「こんなものか」と思われてしまう部分もあったかもしれません。特に日本語の精度は低く、全体的に実用的な水準ではありませんでした。しかし、そのような評価はGPT-4の登場により大きく覆ることになります。GPT-4は人間ですら難しいとされる国家試験の数々を上位通過する性能を見せ、多くのタスクにおいて人間と同等以上の結果を残せるほどに成長したのです。本記事では、そんなGPT-4について解説していきます。
合同会社Noteip代表。ライター。米国の大学でコンピューターサイエンスを専攻し、卒業後は国内の一部上場企業でIT関連製品の企画・マーケティングなどに従事。退職後はライターとして書籍や記事の執筆、WEBコンテンツの制作に関わっている。人工知能の他に科学・IT・軍事・医療関連のトピックを扱っており、研究機関・大学における研究支援活動も行っている。著書『近未来のコア・テクノロジー(翔泳社)』『図解これだけは知っておきたいAIビジネス入門(成美堂)』、執筆協力『マンガでわかる人工知能(池田書店)』など。

GPT-4とは? GPTシリーズ最高峰の性能
GPT-4はOpenAIが開発した効率的な言語処理を実現したTransformerを利用した大規模言語モデル(LLM)であるGPT(Generative Pre-training Transformer)シリーズの最新バージョン(2023年5月時点)です。GPTシリーズは登場当初から自然言語処理において高い性能を発揮し、業界内では大きな注目を集めていましたが、GPT-4はさまざまな研究で「言語処理において人間以上の知能を持つ」ことが明確に示されました。
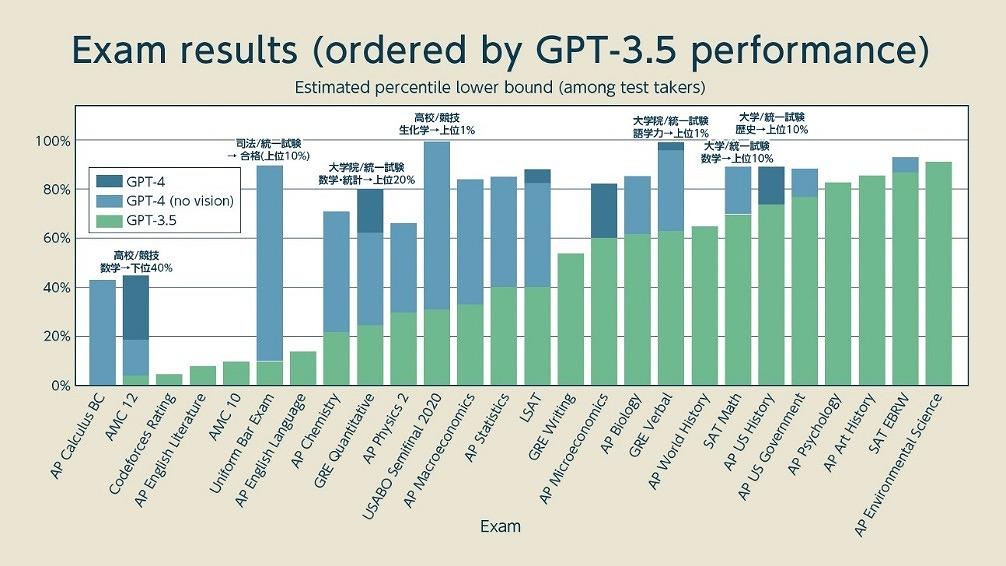
(出典:OpneAI公表資料より筆者作成)
上記のグラフはOpenAIが公開した米国の各種試験におけるGPT-4の成績を表すものです。少し分かりにくいですが「下限値を示すグラフ」で実質的に「上記の割合の人間の成績を超えた」ということを示しています。
緑のグラフがGPT-3.5で、青色がGPT-4、濃紺が「GPT-4の画像認識」を入力に使ったケースです。これを見ると、司法試験で上位10%に入っており、大学院の試験でも語学では上位1%で、数学でも上位20%に入っています。
また、米国の大学入試であるSATや大学院入試であるGREでは、数学を含めてかなりの好成績を出しています。大学レベルの問題を高校生に課す学力テストであるAP(Advanced Placement)では、科目別に細かく分野が分かれていますが、全般的に好成績を出しています。特に知識や語学力を問うような試験に非常に強く、この分野では人間がGPT-4に敵いません。
一方、高校生の数学コンテストであるAMCでは成績が伸びていません。SATやGREは日本で言う共通テスト(センター試験)にあたる統一試験であることから、数学分野であるあるものの問題自体はそこまで難しくありません。それに対して、AMCの数学コンテストでは難関大学の二次試験のような難問が出るので対応しきれなかったのかもしれません。
もうひとつ注目すべきは「Literature」や「English Language」の成績が伸びなかったことです。このあたりは「出題形式との相性」や「データ不足」が顕著に出ている可能性がありますが、感情や文化的背景の理解力が不足している可能性もあります。
ちなみに、このようなLLMが「なぜ特定の問題を解けないのか」という点については、GPTなどのLLMが「説明可能」な設計にはなっていないことから、具体的な説明がなされていません。基本的にはLLMの特性から推測するか、学習データやチューニングをしながら「学習プロセスの問題点」を見つけ出すことによって絞り込みます。このような正確な原因が分からないという点は、ディープラーニングを使ったLLMベースのAIの大きな欠点とされています。
GPT-4の日本語における性能
OpenAIのレポートでは、米国の試験が中心になっているので基本的には英語における精度を示していますが、言語別の精度についても報告されています。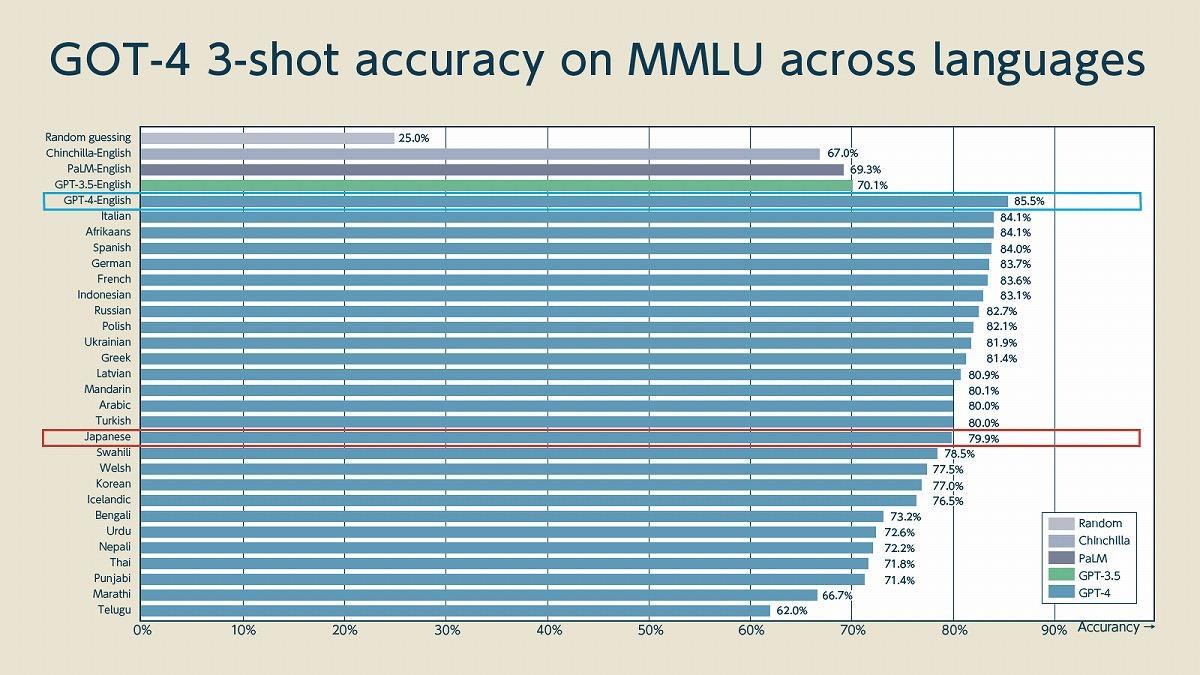
(出典:OpenAI公表資料より筆者作成)
英語の成績が85.5%であるのに対して日本語が79.9%という精度になっており、英語と日本語で5%の差しかありません。GPT-3.5における詳細な比較データが見つからなかったものの、GPT-3.5における日本語の精度は概ね10%前後は低いことが示されている(後述の国家試験含む)ので、GPT-4で両者の差は大きく縮まっているのではないでしょうか。
実際に、日本語で実施される日本の医師国家試験をGPT-4がパスしたという研究報告が日本の研究チームから上がっています。以下は6年分の試験を受けたGPTシリーズの成績と医学生の平均点(Student Majority)、問題数(Total)、合格点(Passing Score)を表したものです。
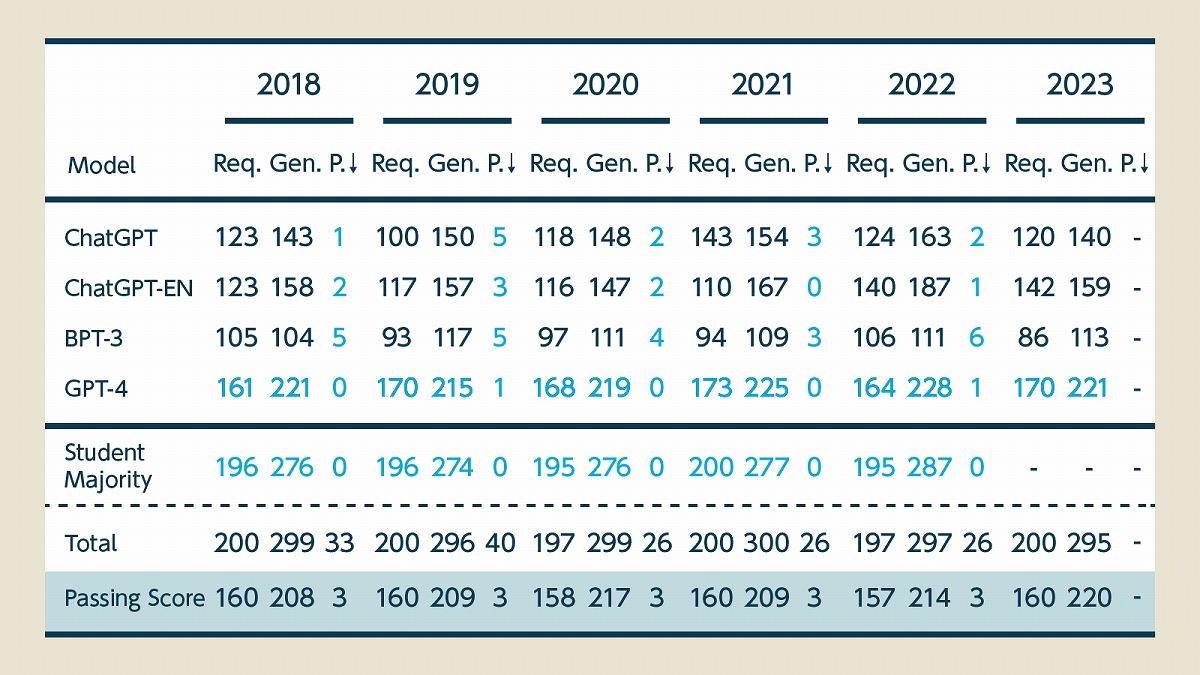
(出典:日本の研究チーム論文より筆者作成)
必須回答(Req)と全体(Gen)の双方において、ほかのGPTシリーズがすべて不合格となっているのに対し、すべての年度でGPT-4が合格点を出していることが分かります。また、禁忌肢(P)と呼ばれる「3つ選ぶと正答数に限らず不合格」となる「命を預かる医師として、絶対に間違えてはならない選択」についても、6年間で2問だけ不正解という成績でなんとかパスしています。
一方、医学生の平均スコア(ほぼ満点)は下回っているため人間の医師には及びませんが、それでも医師として申し分ない成績であることはたしかです。また、医学生の平均点については医師国家試験の合格率が90%である点を考慮する必要があります。医師国家試験を受験するためには医大を卒業しなければならず、受験時点である程度の学力が担保されていることから平均点が高くなる傾向にあります。
試験に合格してからしばらく経った現役医師と比較すると、また別の数値が見えてくるかもしれません。何れにせよ、GPT-4では日本語においては極めて優秀な能力を示せることがわかります。
結局、「GPT-3.5→GPT-4」で何が変わったのか?
それでは、GPT-3.5からGPT-4になり、具体的に何が変わったのでしょうか。詳細は明かされていないものの、1つはその規模にあると考えられています。GPT-4に使われているTransformerというディープラーニングアーキテクチャはグーグルが開発して公開したもので、自然言語処理の学習効率に優れており、GPT以外にもグーグルのLLMである「BERT」「LaMDA」「PaLM」にも使われているほか、さまざまなLLMに広く利用され、LLMにおける事実上のデファクトスタンダード的なアーキテクチャになっています。
Transformer型の言語モデルでは、言語情報をベクトル情報で処理した上で、それぞれの関係性をハイパーパラメータと呼ばれる数値で表現します。この数値を調整することで言語モデルは学習を進めていきますが、一般的にはこの「パラメータ数」が多ければ多いほど、複雑で難解な情報を処理できるとされています。
Transformer型LLMでは、このパラメータ数を増やしても計算処理の負担がそれほど大きくならないことから、従来の言語モデルに比べて大規模なモデルを構築できるようになりました。結果として、LLMのパラメータ数は飛躍的に増大を続け、GPTの最初のモデルでは1.2億だったものが、GPT-3では1750億まで膨れ上がりました。
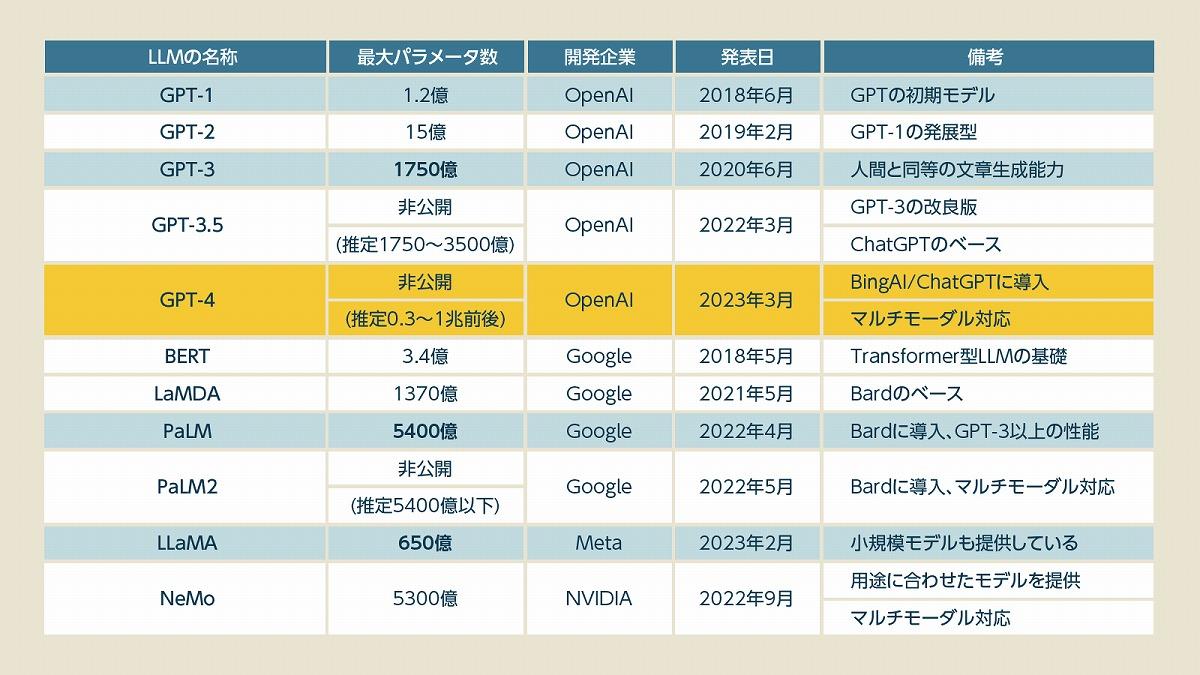
(出典:各種公表資料より筆者作成)
GPT-4のパラメータ数に関する詳細は非公開ではあるもののGPT-3.5よりも規模が大きく、グーグルのPaLMやエヌビディアの「NeMo」が5000億パラメータを超えていることから、同等以上の性能を持つGPT-4も同程度のパラメータ数であると推定されています。一部の推定では100兆を超えるとされていますが、パラメータ数のスケールがあまりに増大すると計算リソースが不足し、十分な学習ができないことで却って性能が落ちるという指摘もあるため、現実的ではないとされています。
一方で、最近の研究ではパラメータ数の上昇が必ずしも性能の向上にはつながらないことが分かっており、GPT-4のパラメータ数が3000億程度になるのではないかという推定もあるため、たしかな数値は分かりません。実際にGPT-3の半分以下の600億程度のパラメータ数で同等の性能を発揮するMetaのLLaMAが登場しているほか、グーグルの新しいLLMである「PaLM2」は従来よりも効率的に動作すると発表されています。
PaLM2のパラメータ数に関して公式な見解は出ていませんが、パラメータ数の違う4つのモデルが出ており、最も小さなモデルはスマホに搭載できる規模です。パラメータ数が少なくとも、一定水準の性能が発揮できることが推察されます。
このように、新しいLLMでは、パラメータ数を増やすこともよりも、推論や学習の効率を上げることに重点が置かれているため、LLMのパラメータ数が性能指標になるとは必ずしも言えません。しかし、GPT-4がその規模においてGPT-3を超えており、性能の上でも凌駕していることから高いポテンシャルがあることはたしかです。
GPT-4の優れた点、「マルチモーダル」とは何か?
GPT-4が優れている点は、単に「LLMの規模が大きく賢いから」というだけに留まりません。注目すべきは言語処理だけではなく、画像認識と組み合わせた上で「画像」と「言語」を組み合わせた情報処理ができるという点にあります。画像とテキストなど、複数の異なる形式の情報処理が可能な特性のことを「マルチモーダル(multimodal)」と呼びます。画像生成AIなどでは、すでに「テキスト」形式のプロンプトから「画像」を生成するといったタスクが実行可能になっていました。こうしたAIもマルチモーダル対応と言えますが、画像生成AIはあくまで「画像」を主体とするAIであるため言語理解能力に乏しく、文章を理解して画像を生成するというよりは、単語に関連する画像を生成するような段階に過ぎませんでした。
GPT-4では、そこから一歩進んだ画像認識と言語処理を行います。GPT-4のマルチモーダル機能はまだ一般開放されていないため、ChatGPT Plusでも利用できません。しかし、OpenAIには具体的な事例が示されています。

(出典:OpenAIのレポートより筆者作成)
この例では、画像を示した上で「ユーモアの説明」を依頼しています。これはLightningケーブル用の「VGA型のケーブルフィギュア」で、ケーブルの上に被せて使うと「まるでテレビ用のケーブルをスマホに指しているように見える」という商品なのですが、それぞれの商品特性を正しく認識した上で「違和感のある画像」として説明しています。
このマルチモーダル機能を利用すれば、前述の大学入試問題における「画像や図面を伴う問題」についても回答も可能です。一部の数学の問題に利用され、正答率を大幅に向上(グラフの濃緑部分)させています。また、画像に関する解説やキャプションを自動で生成できるようになるほか、漫画やイラストに合わせたストーリー生成なども可能になるでしょう。 【次ページ】GTP-4に匹敵? 3社のマルチモーダルLLM(MLLM)を比較
AI・生成AIのおすすめコンテンツ
関連タグ
タグをフォローすると最新情報が表示されます
AI・生成AIの関連コンテンツ
あなたの投稿
PR
PR
PR
