- 会員限定
- 2024/08/09 07:10 掲載
合成データとは何か? 生成AIとの関係は? アマゾン・花王・東京大学ら活用事例10選
連載:デジタル産業構造論
法政大学 デザイン工学部システムデザイン学科 准教授 / d-strategy,inc / Third Ecosystem,inc / Inclusive AI,inc 代表取締役CEO
日立製作所、デロイトトーマツコンサルティング、野村総合研究所、産業革新投資機構 JIC-ベンチャーグロースインベストメンツを経て現職。2024年4月より東京国際大学データサイエンス研究所の特任准教授としてサプライチェーン×データサイエンスの教育・研究に従事。加えて、株式会社d-strategy,inc代表取締役CEOとして下記の企業支援を実施(https://dstrategyinc.com/)。
(1)企業のDX・ソリューション戦略・新規事業支援
(2)スタートアップの経営・事業戦略・事業開発支援
(3)大企業・CVCのオープンイノベーション・スタートアップ連携支援
(4)コンサルティングファーム・ソリューション会社向け後方支援
専門は生成AIを用いた経営変革(Generative DX戦略)、デジタル技術を活用したビジネスモデル変革(プラットフォーム・リカーリング・ソリューションビジネスなど)、デザイン思考を用いた事業創出(社会課題起点)、インダストリー4.0・製造業IoT/DX、産業DX(建設・物流・農業など)、次世代モビリティ(空飛ぶクルマ、自動運転など)、スマートシティ・スーパーシティ、サステナビリティ(インダストリー5.0)、データ共有ネットワーク(IDSA、GAIA-X、Catena-Xなど)、ロボティクス・ロボットSIer、デジタルツイン・産業メタバース、エコシステムマネジメント、イノベーション創出・スタートアップ連携、ルール形成・標準化、デジタル地方事業創生など。
近著に『メタ産業革命~メタバース×デジタルツインでビジネスが変わる~』(日経BP)、『製造業プラットフォーム戦略』(日経BP)、『日本型プラットフォームビジネス』(日本経済新聞出版社/共著)。経済産業省『サプライチェーン強靭化・高度化を通じた、我が国とASEAN一体となった成長の実現研究会』委員(2022)、経済産業省『デジタル時代のグローバルサプライチェーン高度化研究会/グローバルサプライチェーンデータ共有・連携WG』委員(2022)、Webメディア ビジネス+ITでの連載『デジタル産業構造論』(月1回)、日経産業新聞連載『戦略フォーサイト ものづくりDX』(2022年2月-3月)など。
【問い合わせ:masahito.komiya@dstrategyinc.com】
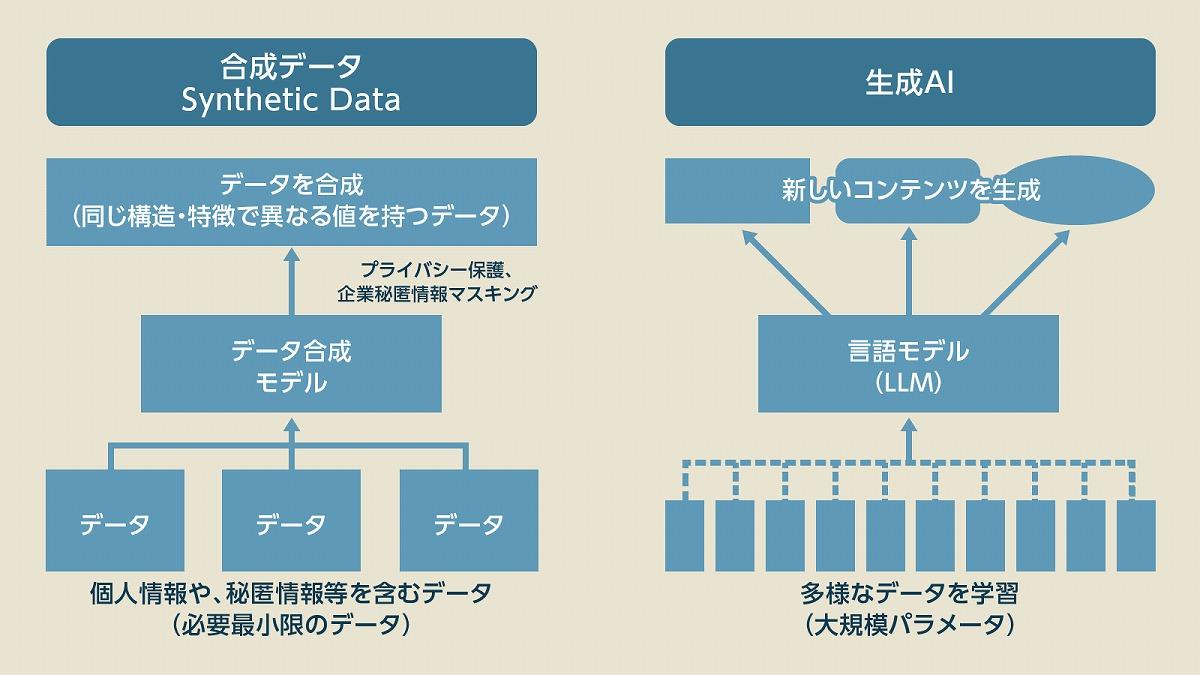
生成AI時代の超重要コンセプト「合成データ」とは?
合成データ(Synthetic Data)とは、現実世界に実在するデータに似せて、人工的に作り出されたデータを指す。合成データの特徴は、生成AIと比べてみると分かりやすいかもしれない。たとえば、生成AIは、あらゆるデータを学習させた「言語モデル(LLM)」を基に、実在しない新たなデータを生成するアプローチである。一方、合成データは、実在するデータを基に、実在するデータにそっくりなデータ(同じ構造・特徴だが、値は異なる)を生成するアプローチだ。
それでは、何のために合成データが必要なのか。たとえば、下記のケースなどにおいて、合成データは役立つ。
■合成データが活躍する場面
- (1)大量の学習データが必要になる場合、または学習データが不足・欠損している場合に、その分を補うデータを用意できる
- (2)個人情報や秘匿情報など、そのまま活用できないデータを学習させたい場合に、その代わりとなるそっくりな学習データを用意できる
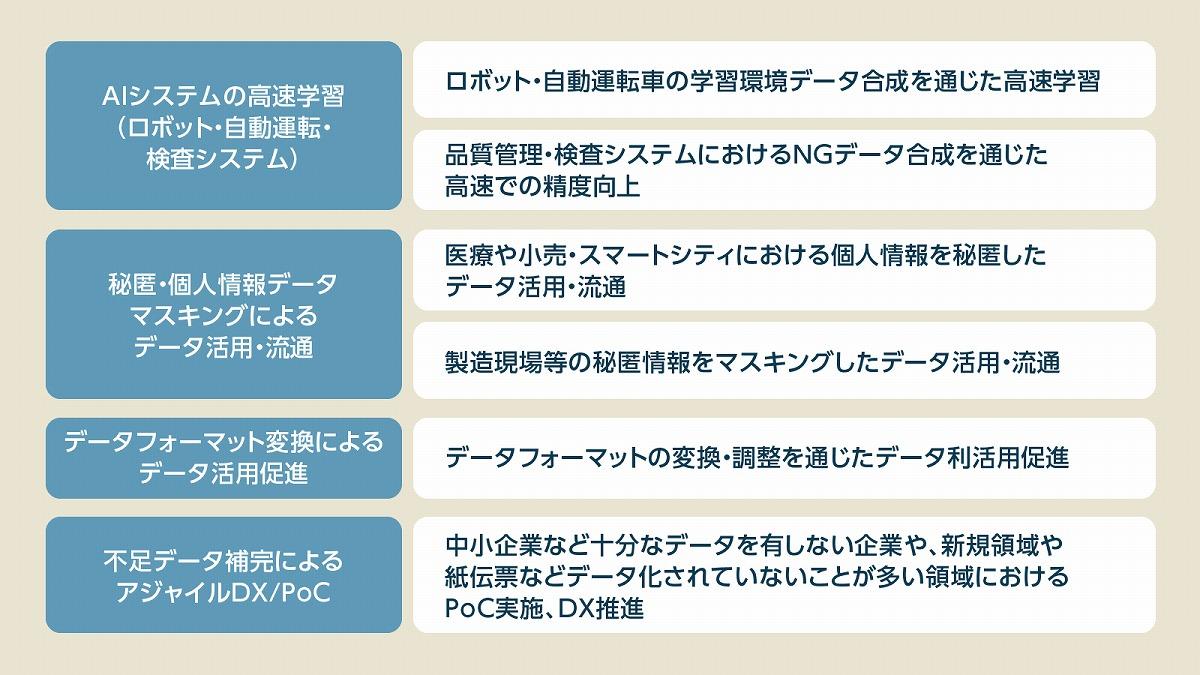
合成データは何に使える? 4つの方向性を解説
合成データの活用方法としては、大きく分けて下記の4つの方向性が存在する。たとえば、AIシステムの学習を高速化させるための学習データとして活用されているほか、個人情報などを扱う領域における学習データとして使われる事例も増えてきている。 また、そのままでは学習データとして活用できないデータに関して、活用しやすいデータフォーマットに変換・調整された合成データを生成し、学習データとして活用するケースもある。さらに、十分な学習データを用意できない領域などにおいて合成データがその不足したデータを埋める形で活用される事例もある。
ここからは、実際に合成データがどのように使われているのか、企業の事例を交えながら解説していきたい。
【一覧表付き】合成データの活用事例10選
下図では、合成データの活用事例の一部をまとめた。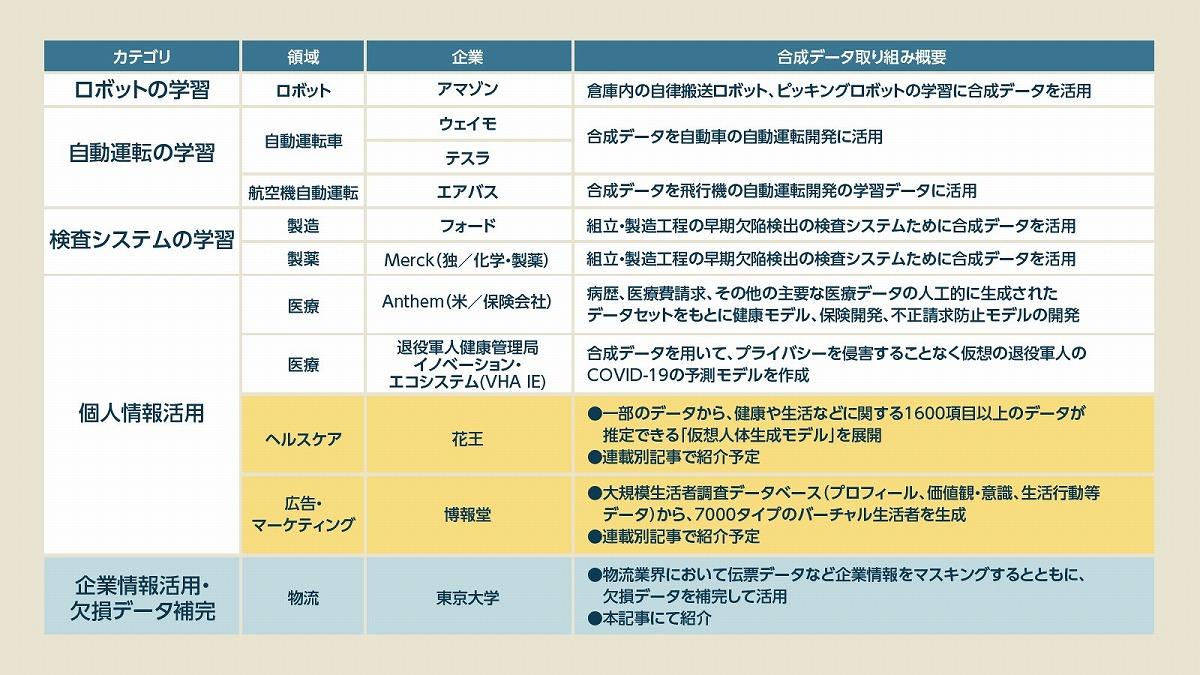
ここで紹介している事例以外にも、現在、合成データはさまざまな業界で活用が進んでいる。その1つの事例として、自律搬送ロボットやピッキングロボット、自動運転車などの学習の効率化が挙げられる。
これまで、ロボットの学習は、事前にさまざまな行動パターンを想定して学習をさせる必要があり、このティーチング作業に時間がかかっていた。しかし、こうした課題を合成データは解決してくれる。
たとえば、アマゾンは倉庫内のロボットの学習データを用意するにあたり、エヌビディアの「合成データ活用のプラットフォーム」を活用しており、これが学習の高速化につながっている。

そのほか、製造業における検査システムの学習データとして、検査時にNGの出るデータを合成データで用意する事例が出てきている。また、物流業界では、サプライチェーン効率化を図るべく、関連企業の秘匿情報に似せた合成データを用意し、これを学習データとして活用している。
こうした特定の業界における活用に留まらず、合成データは、欧州を中心に活発化するデータ共有の取り組みを加速させる役割も担っている。たとえば、Catena-XやManufacturing-X、日本のウラノス・エコシステムなどの枠組みにおいて、企業を超えたデータ連携の議論が活発化しているが、それらの取り組みにおいても、企業秘匿情報に似せた合成データを活用していくことが検討されている。
ここからは、上記の事例の中から、東京大学における合成データ活用の取り組みについて、東京大学 空間情報科学研究センター 特任准教授の小塩篤史氏に解説してもらった。 【次ページ】【第一人者が解説】「生成AI」と「合成データ」の使い分けは?
AI・生成AIのおすすめコンテンツ
AI・生成AIの関連コンテンツ
PR
PR
PR
