- 会員限定
- 2025/05/12 掲載
GPT-4.1、Claude 3.7 Sonnet、Gemini 2.5 Pro、Grok 3、用途別で見るベストLLMとは?
英大学院修了後、RPA企業に勤務。大手通信社シンガポール支局で経済・テクノロジーの取材・執筆を担当。その後、Livit Singaporeでクライアント企業のメディア戦略とコンテンツ制作を支援(主にドローン/AI領域)。2026年2月、シンガポールで「SimplyPNG」を設立し、AI画像編集のモデル運用とGPUコスト最適化を手がける。主にEC向け画像処理ワークフローの設計・運用自動化に注力。
チャットボット性能の頂点へ、4大LLMの実力を徹底比較
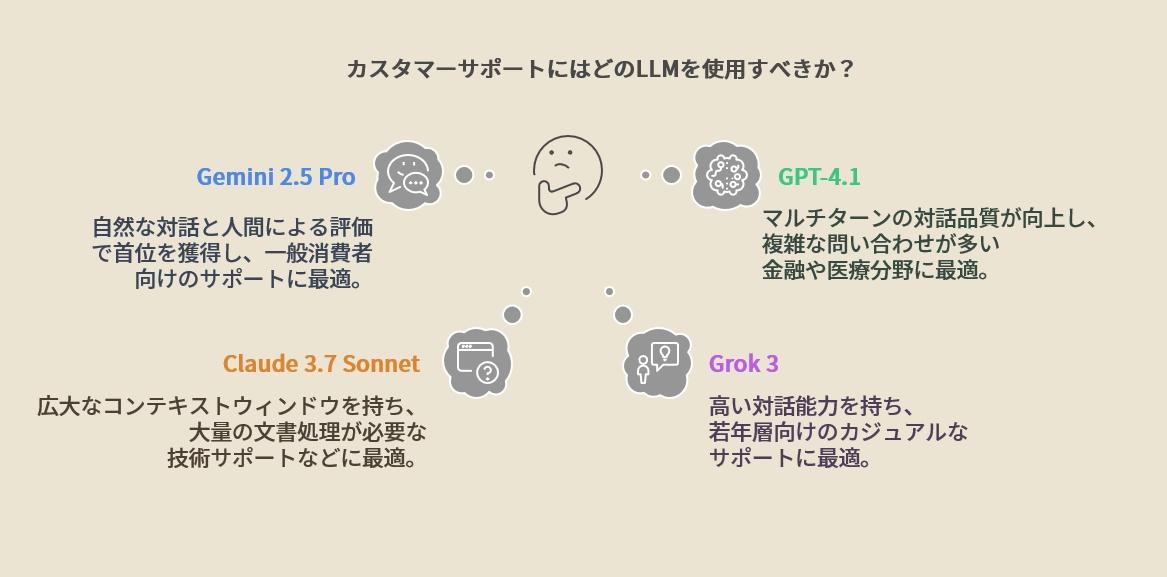
まずカスタマーサポート分野では、各モデルはどのような強みを発揮するのか、それぞれの特徴を解説したい。この分野で、特に注目されるのがグーグルのGemini 2.5 Proだ。
同モデルは、チャットボットの総合評価を行うChatbot Arenaのリーダーボードで首位を獲得。人間による評価で、他のモデルを大きく引き離す実力を示している。この結果は、より自然な対話が可能になったことを示唆するもので、特に一般消費者向けのカスタマーサポートでの活用が期待される。
OpenAIのGPT-4.1も、その実力は群を抜くとの評価だ。同モデルは、マルチターンの対話品質を向上させるチューニングを重ね、前モデルと比較して10.5%性能が向上した。会話の文脈を正確に把握し、過去の発言内容を適切に参照できる能力が大幅に改善されたという。この特性は、複雑な問い合わせが多い金融や医療分野のサポートで特に威力を発揮する可能性が高い。
一方、アンソロピックのClaude 3.7 Sonnetは、20万トークン(英語約15万ワード)という広大なコンテキストウィンドウを特徴とする。これにより、長時間の対話履歴や大量の知識ベース記事を一度に処理することが可能となり、カスタマーサポートなどの実用シーンで優位性を発揮すると評価されている。特に、製品マニュアルや社内規定など、大量の参照文書が必要となる技術サポート分野での活用が見込まれる。
xAIのGrok 3も、その会話能力の高さに定評を得ている。Geminiのリリース以前には、ベータ版(コードネーム:chocolate)がChatbot Arenaで首位を獲得。チャットボット同士の対戦では1402のEloレーティングを記録し、対話品質において他モデルを圧倒する結果を残した。この高い対話能力により、特に若年層向けのカジュアルなサポート場面で力を発揮することが想定される。
各モデルの特徴は、そのスタイルと安全性にも表れている。Claude 3.7は、アンソロピックの「Constitutional AI」によって調整され、不当な要求の拒否率が前モデルから45%減少。カスタマーサービスの円滑な運用に寄与できると考えられる。GPT-4.1は創造性やユーモア、ニュアンスの理解に優れ、ユーザーの感情に寄り添った応答が可能だ。Grok 3は事実に基づく正確な情報提供を重視し、状況に応じて柔軟にトーンを調整できる特徴を持つ。これらの特性は、金融や医療など、高い正確性と安全性が求められる分野で重宝される。
これらのLLMは、サポートチケットの選別や感情分析においても高い性能を発揮する。セールスフォースの調査によると、AIサポートエージェントの効果的な運用には、人間への引き継ぎのタイミングを見極める能力が重要となる。4つのモデルはいずれも、会話の複雑さやカスタマーの感情を正確に読み取り、適切なタイミングでの人間への引き継ぎを可能としている。この機能は、大規模なコールセンター運営において、効率的な人的リソース配分を実現する上で特に有用となるはずだ。
今すぐビジネス+IT会員に
ご登録ください。
すべて無料!今日から使える、
仕事に役立つ情報満載!
-
ここでしか見られない
2万本超のオリジナル記事・動画・資料が見放題!
-
完全無料
登録料・月額料なし、完全無料で使い放題!
-
トレンドを聞いて学ぶ
年間1000本超の厳選セミナーに参加し放題!
-
興味関心のみ厳選
トピック(タグ)をフォローして自動収集!
AI・生成AIのおすすめコンテンツ
関連タグ
タグをフォローすると最新情報が表示されます
AI・生成AIの関連コンテンツ
あなたの投稿
PR
PR
PR
