- 会員限定
- 2020/11/26 掲載
教師なし学習とは何か? クラスタリングやアルゴリズムをわかりやすく解説する
AI関連技術の中でも、近年、著しい進化を見せているのが機械学習(マシンラーニング、Machine Learning)だ。機械学習とは「プログラム自体が自動で行う学習」の総称で、人間がプログラムした以上のことをコンピュータにさせることが目的となる。大きく「教師あり学習」と「教師なし学習」に分かれるが、今のマシンラーニングの進化は「教師なし学習」によるところが大きい。自動生成系のツールとして注目されるGAN(敵対的生成ネットワーク)もその1つだ。ここでは「教師なし学習」にフォーカスし、どのような技術があるのか、その特性と活用事例を解説する。
大内孝子
主に技術系の書籍を中心に企画・編集に携わる。2013年よりフリーランスで活動をはじめる。IT関連の技術・トピックから、デバイス、ツールキット、デジタルファブまで幅広く執筆活動を行う。makezine.jpにてハードウェアスタートアップ関連のインタビューを、livedoorニュースにてニュースコラムを好評連載中。CodeIQ MAGAZINEにも寄稿。著書に『ハッカソンの作り方』(BNN新社)、共編著に『オウンドメディアのつくりかた』(BNN新社)および『エンジニアのためのデザイン思考入門』(翔泳社)がある。

(Photo/Getty Images)
ブームが終わり、普及期に入ったAI
ひと頃の“AIブーム”が落ち着いて、AIはいよいよ社会実装の段階に入ったといわれる。クラウド経由で利用できるさまざまなAIサービスがあり、自社のサービス/プロダクトの付加価値として、あるいはデジタル・トランスフォーメーション(DX)のコア技術として、選択肢の1つになりつつあるといえる。Amazon Web Service(AWS)、Google Cloud Platform(GCP)、Microsoft Azure、IBM Cloudなどのクラウドサービスでは、さまざまなマシンラーニングのアルゴリズムや学習済みモデルが用意されていたり、開発支援、運用担当者向けの機能が用意されている。
こうしたクラウドプラットフォーム上のAI技術を活用するメリットは、クラウドにデータを集約するといったビジネスモデル(既存のクラウドデータの利用も含め)との親和性だけではなく、プロトタイピングあるいは小さなスケールから試せる利便性も大きい。
各プラットフォームにより異なるが、そこで提供されるのは、
・ログなどのデータ分析
・テキスト分析
・画像、動画、音声分析
などの技術をベースにした機能で、たとえば会話エンジン、自動翻訳エンジン、テキスト読み上げ機能、レコメンド機能、不正防止(監視)、エラーの自動検出などに活用できる。
大まかにいうと、マシンラーニングとは大量のデータを学習させてデータの特徴をつかんで、それを元に分類や予測、生成ができるモデルを作ることだ。自然言語処理や音声合成など、そのほかのさまざまな技術を組み合わせた形で、チャットボットAIやリアルタイム翻訳、動画の字幕生成など、具体的なサービスのレベルにまで実装が進んでいる。
ただ、人の代わりになるような精巧なモデルを作ることは容易ではない。これはRPAの導入と似た話になるが、何をAIで自動化し、その上で人間が何をするかの切り分けが重要で、AI導入の難しさはまずそこにある。
とはいえ、著しい速度で進むAI分野、その中でもマシンラーニングは今の第3次AIブームを牽引してきた主流の研究分野であり、さまざまなアルゴリズムや手法が生み出されている。
「教師なし学習」とは何か?「教師あり学習」との違い
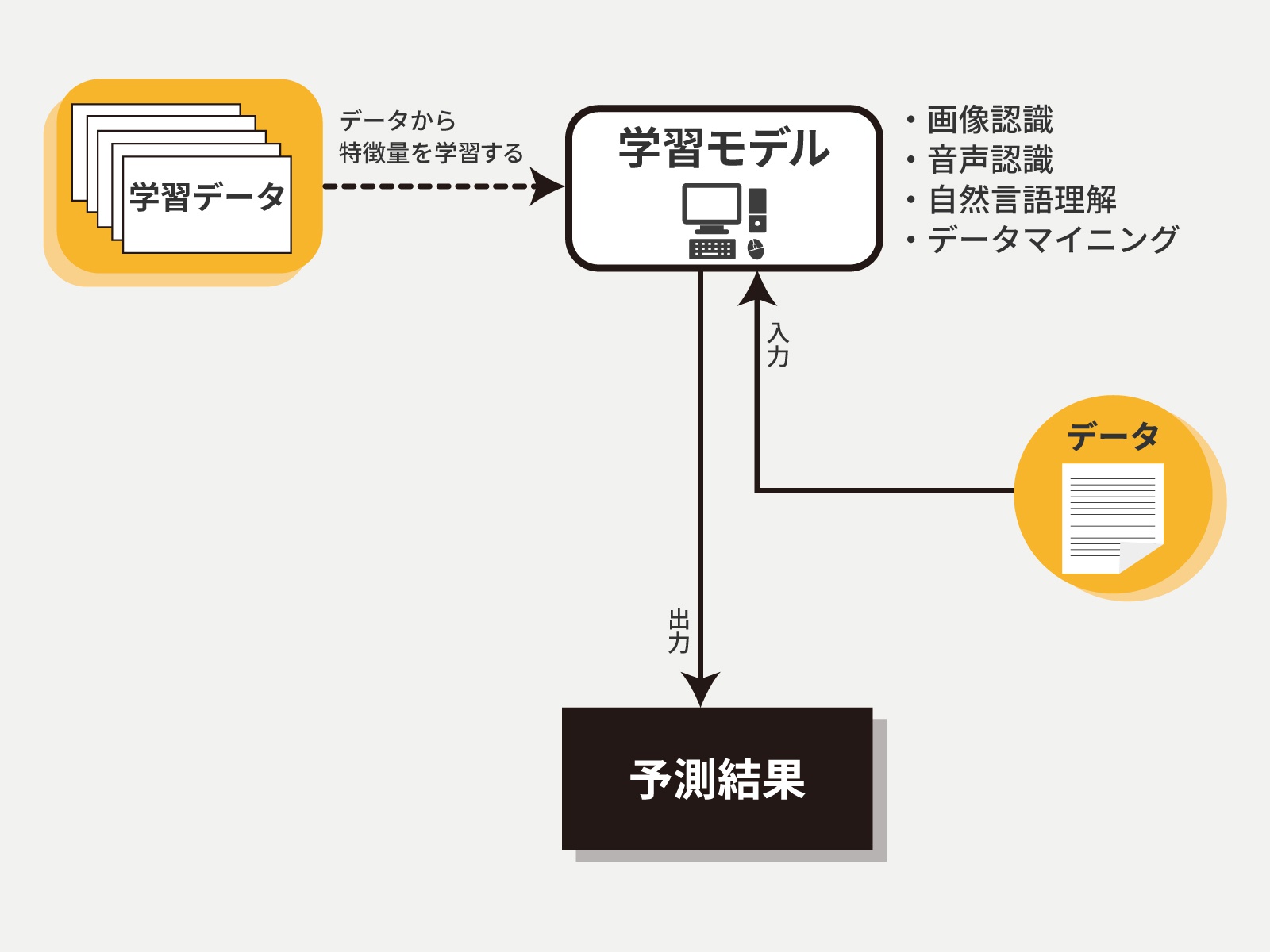
マシンラーニングは、その学習スタイルで大きく「教師あり学習」と「教師なし学習」に分けられる。いずれもデータを元に学習するわけだが、「教師あり学習」は「特徴を示すデータ」と「答えとなるデータ」の組み合わせで学習させてモデルを作る。このとき、特徴を示すデータを「特徴量」(あるいは「説明変数」)、答えとなるデータを「目的変数」(あるいは「ラベル」)と呼ぶ。この2つをデータセットとして学習し、特徴量から推定するモデルを作るのだ。
たとえば、「体重」と「筋肉量」を特徴量として与え、「成人男性」「成人女性」「未成年(男児)」「未成年(女児)」を目的変数とする。学習用のデータセットで、目的変数それぞれにおける体重と筋肉量のデータ群からその特徴をつかみ、新たに入力されたデータから、成人男性/成人女性/未成年(男児)/未成年(女児)である確率を出す。
この例での学習モデルの機能は与えられた数値を元にラベリングする「分類」だが、目的変数に連続値を取ることもできる(回帰分析)。先ほどの例を組み替えて考えると、体重と成人女性などのラベルを特徴量として学習し、目的変数に設定した筋肉量を推定するというケースだ。
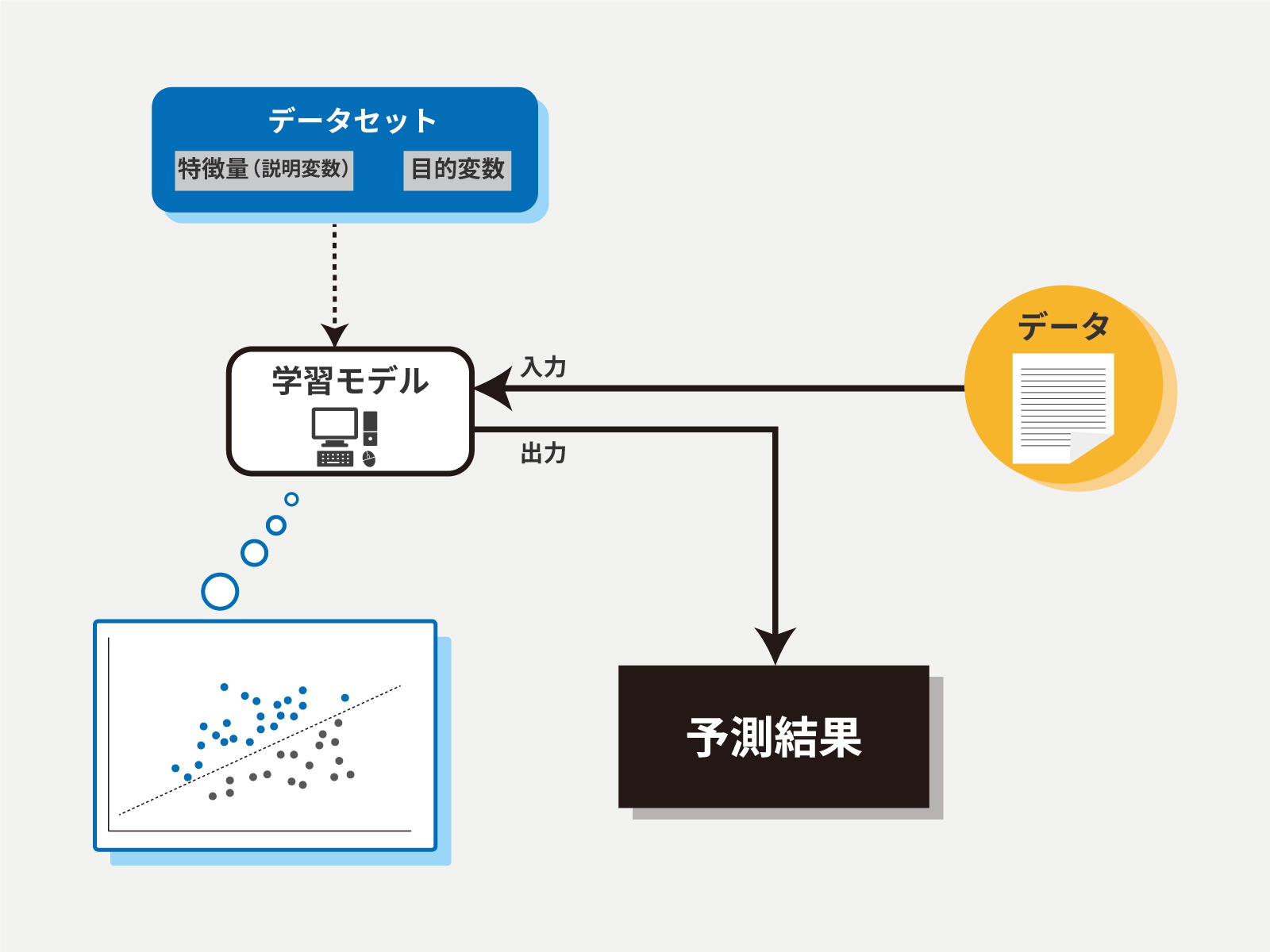
一方、「教師なし学習」は学習データに目的変数を含まない。これをもって「教師なし学習は“答え”を与えない」という表現になるのだが、そこが“学習の違い”の分かりにくさにつながっている。
そもそも「教師あり学習」と「教師なし学習」では実現しようとすること(できること)が異なる。「教師あり学習」ではデータの特徴から与えられた「答えである確率」を出すのに対し、「教師なし学習で」は、相関する複数のデータを簡潔に表現することが目的になる。
たとえば、リンゴの種類、産地、出荷日、甘みというように特徴量だけを与え、それらの間にどういう関係があるのか(あるいは、ないのか)を解析する。種類と甘みは当然関連するし、別軸に産地と甘みの関係も知りたい。それらと出荷日との間に相関があれば、最適な出荷日を知ることができるはずだ。
この例は、変数の種類が多いときに複数の変数の特徴を損なうことなく新たな変数で表すことで全体の見通しを整理する「主成分分析」の問題だ。主成分分析とはデータの次元を削減する、複雑な構造のデータをその特徴量を維持したままシンプルな形に表すための統計分析手法で、「次元圧縮」と呼ばれるカテゴリーになる。
そして、「教師なし学習」が得意とするのは「クラスタリング」だ。これは、多変数のデータをシンプルなクラスターで表現することで分かりやすく提示するというものだ。
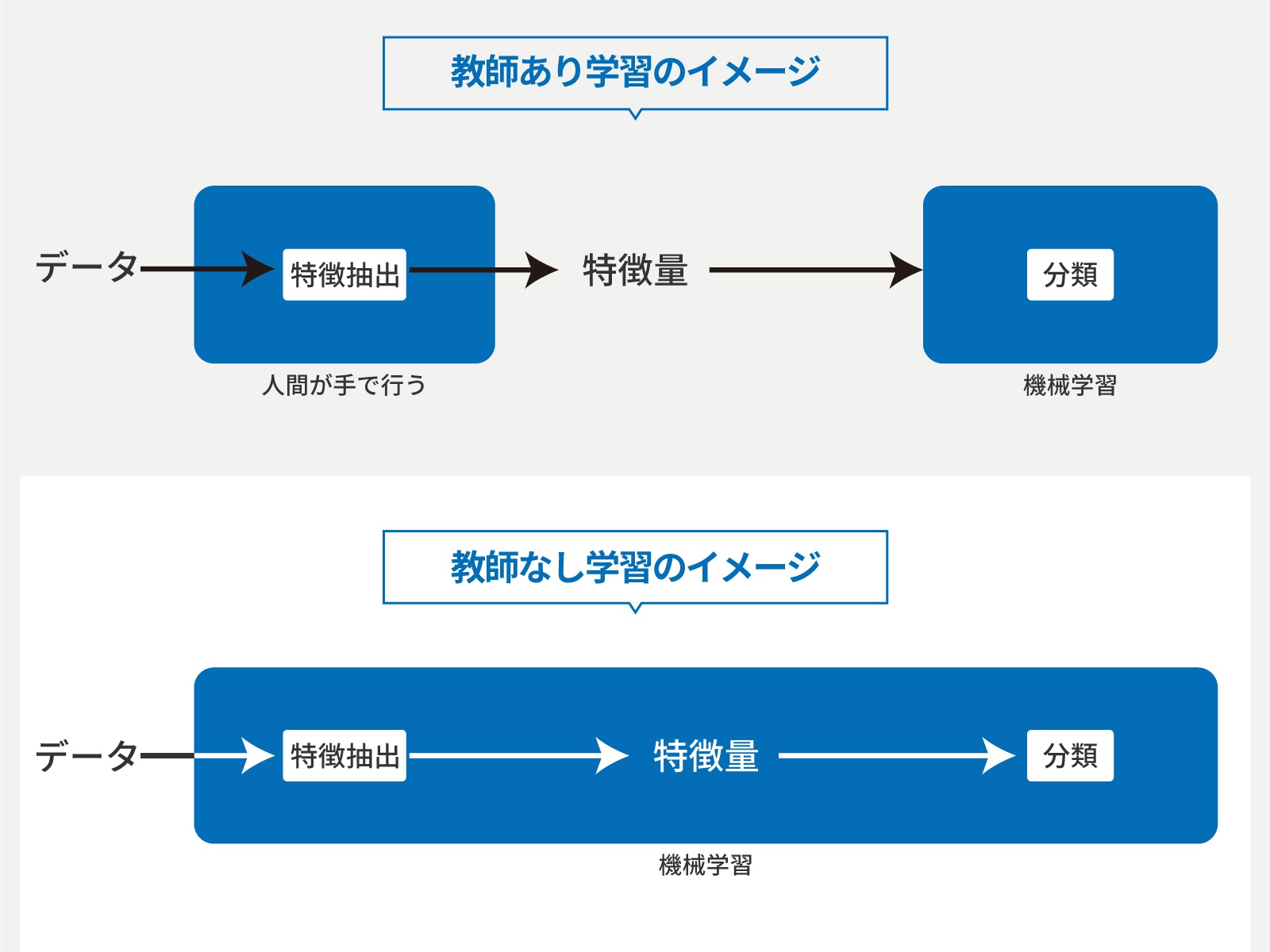
(出典:岡谷貴之著, 「ディープラーニング」(映像情報メディア学会誌Vol.68)をもとに改変)
このように、今、教師なし学習が注目されているのは、その統計分析のアルゴリズムが発展し、“使えるように”なってきているからなのだ。
ざっくりとした言い方になるが、「教師あり学習」があらかじめ表現されている事象を扱うのに対し、「教師なし学習」は明確に表現されていない事象を扱う。つまり、暗黙知の活用、言語化されていない部分を表すことができる。「表現できる」ことで、それらのデータの関係性を用いて新たな生成物を作ることができる。ここが「教師なし学習」の成果が大きく期待されているところだといえる。
「教師なし学習」のアルゴリズム、得意とするクラスタリングとは?
前項で述べたように、「教師なし学習」の機能はデータの特徴を抽出する次元圧縮(ざっくりいうと“多変量データの変数を減らす”こと)と、データを同じような集まりに分けるクラスタリングになる。| アルゴリズム | 次元圧縮 | クラスタリング |
| PCA | 〇 | × |
| LSA | 〇 | × |
| NMF | 〇 | × |
| LDA | 〇 | × |
| k-means法 | × | 〇 |
| 混合ガウスモデル | × | 〇 |
| LLE | 〇 | × |
| t-SNE | 〇 | × |
教師なし学習の主なアルゴリズム
(出典:秋庭伸也ほか著,『見て試してわかる 機械学習図鑑』(翔泳社)をもとに改変)
「教師なし学習」のアルゴリズムとしてよく知られているものをいくつか紹介しよう。
「主成分分析(Principal Component Analysis, PCA)」は、複数の変数を持つデータの相互関連を分析する多変量解析の1つだ。できるだけ少ない変数に置き換えて表すことで、計算コストを下げ、視覚化などその後の工程を容易にすることができる。代表的な次元圧縮の手法だ。
同様に「非負値行列因子分解(Non-negative Matrix Factorization, NMF)」も次元圧縮に使われる手法の1つである。PCAと異なるのは、扱うすべての値が常に0以上(0か正の値)であること。マイナスの値を取らないため、分析の結果をとらえやすいのが特徴だ。
そして「LLE(Locally Linear Embedding)」は、非線形データを対象とする次元圧縮の手法だ。たとえば、3次元空間にある構造を2次元で表現するということができる。これは、多様体学習と呼ばれるカテゴリーに含まれるものだ。
次の図は、機械学習とデータマイニングのためのPythonモジュール「AstroML」の公式サイトより転載したものだ。左上のパネルに示すS字型のデータセット(3次元空間内の2次元多様体)を例として、多様体学習であるLLEとIsoMap、それとPCAの出力例を示している。PCAでは色が混じってしまうが、多様体学習ではデータの投影時にもとの構造を保持し、色が混在しないことがわかる。
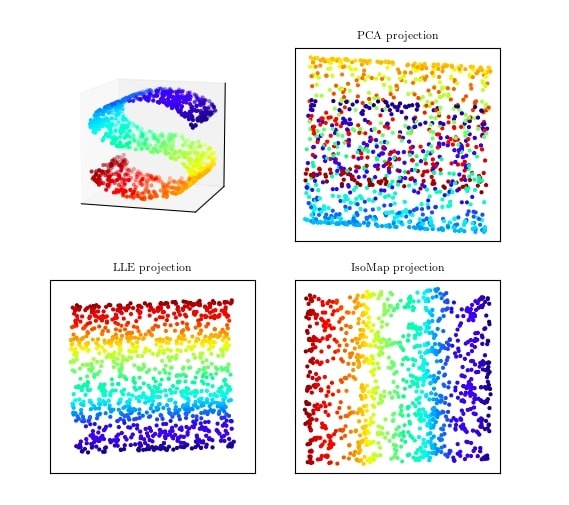
(出典:astroML)
「クラスタリング」は、言葉から何となくイメージが伝わるかと思うが、似たような集まり、近い値のデータをグループ分けすることだ。
「k-means法」は代表的な非階層型のクラスタリングの手法。「混合ガウスモデル(Gaussian Mixture Model, GMM)」は、ガウス分布を使ってクラスタリングする手法。データを複数のガウス分布の重ね合わせで表現することで、クラスターや確率分布を得ることができる。
たとえばk-means法では、まず暫定的にクラスター数とその重心を決め(1)、個々のデータ(点)は最も近い距離にあるクラスタに所属するものとする(2)。クラスターごとに、各重心との距離の平均値を出し、それを新しい重心とする(3)。(2)と(3)を重心の位置が変化しなくなるまでこの作業を繰り返す(あるいは、一定の回数で切る)ことで、分類の最適化を行う(4)というもの。
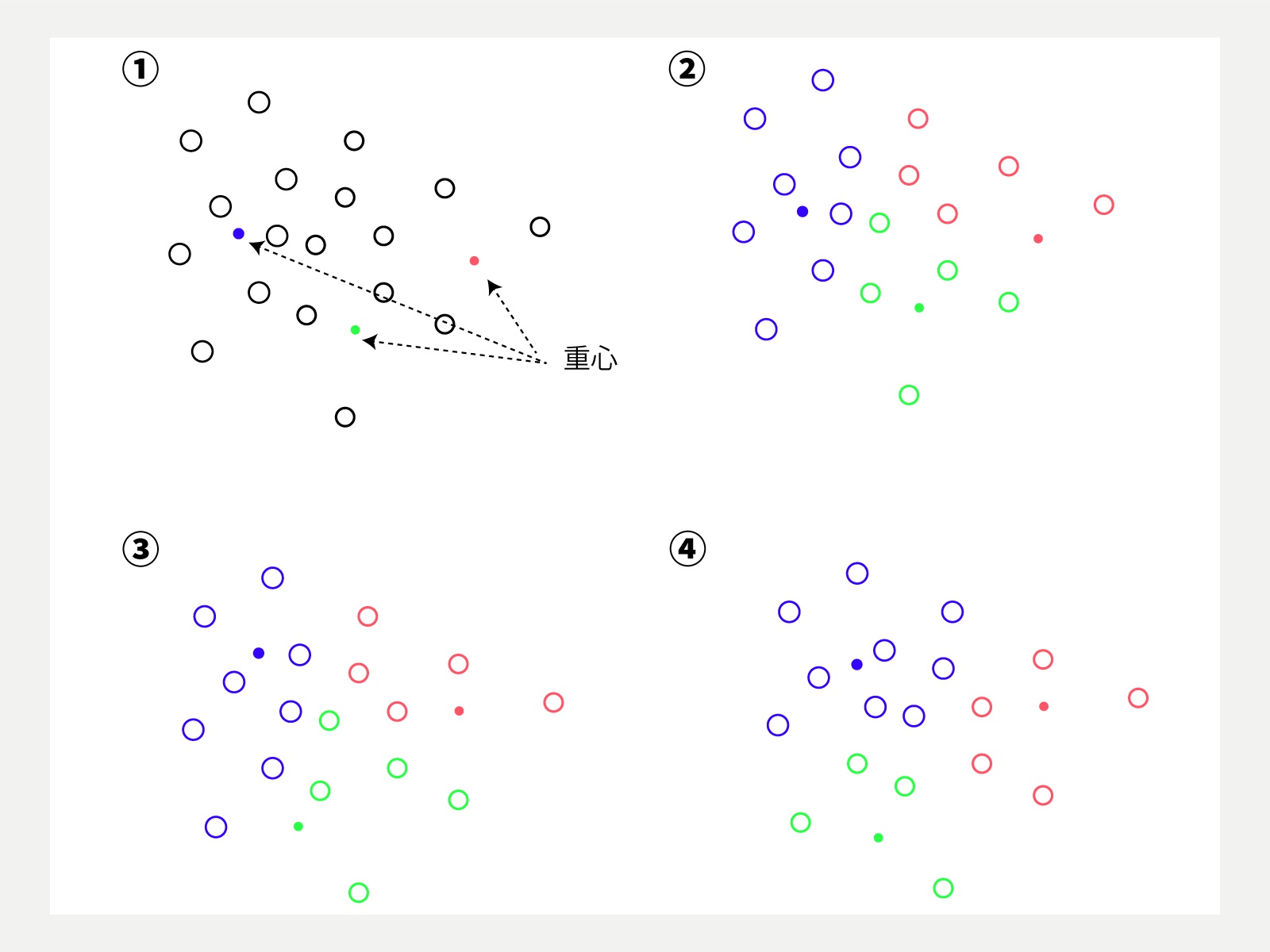
つまり、ラベルなしに分類できる。既知の学習データ(特徴量とラベルのセット)をもとに学習する教師あり学習に対する優位性はそこで、未知のデータに対する学習が可能だということが教師なし学習の最大のポテンシャルだ。
【次ページ】実ビジネスでの活用事例とは?
AI・生成AIのおすすめコンテンツ
関連タグ
タグをフォローすると最新情報が表示されます
AI・生成AIの関連コンテンツ
あなたの投稿
PR
PR
PR
