- 会員限定
- 2019/05/13 07:10 掲載
5分でわかる自然言語処理:人工知能の「文字認識」の仕組みとは
手書き文字を認識するカギはディープラーニング
人工知能関連技術の中でも特に関心が高く応用範囲の広い技術が、文字認識や文章理解に関する「自然言語処理」に関する技術です。この技術は単に人間と機械がコミュニケーションを取る手助けをするだけにとどまらず、情報の収集や検索、書類のデータ化にも役立ちます。事務的な「データ入力」「コールセンター」といったサポート業務から「マーケティング」「経営戦略」にまで幅広く生かせる人工知能による文字認識や文章理解について数学的な用語は一切使わず、2回にわたってやさしく解説していきます。
合同会社Noteip代表。ライター。米国の大学でコンピューターサイエンスを専攻し、卒業後は国内の一部上場企業でIT関連製品の企画・マーケティングなどに従事。退職後はライターとして書籍や記事の執筆、WEBコンテンツの制作に関わっている。人工知能の他に科学・IT・軍事・医療関連のトピックを扱っており、研究機関・大学における研究支援活動も行っている。著書『近未来のコア・テクノロジー(翔泳社)』『図解これだけは知っておきたいAIビジネス入門(成美堂)』、執筆協力『マンガでわかる人工知能(池田書店)』など。

(©Elnur - Fotolia)
人工知能はどうやって文字を認識している?

原理的にはマスを黒く塗って絵を作る「ピクロス」と同じで、コンピューターが「A」を「A」、もしくは「あ」は「あ」であると認識して表示しているわけではありません。この時点での文字は、コンピューターにとっては黒点の集まりに過ぎません。
連載一覧
また、ここでいう「文字認識」はいわゆる「光学文字認識」(OCR:Optical Character Recognition)のことです。紙や印刷物に書かれた文字をスキャンしてテキスト化する技術といえばピンと来るのではないでしょうか。
私たち人間が紙などに書かれた情報を理解できるのは、紙に反射した光の情報を見て「文字」「背景」「インクの染み」を認識しているわけで、実質的には光の情報です。それゆえに、光学文字認識が手書き文字を含めさまざまな文字認識技術の基礎になっています。
この光学文字認識では、文字の持つ「直線」「曲線」「交点」などの特徴を数学的な比率で表して理想的な文字と比較したり、ディープラーニングを応用したり、さまざまな形で捉えていきます。
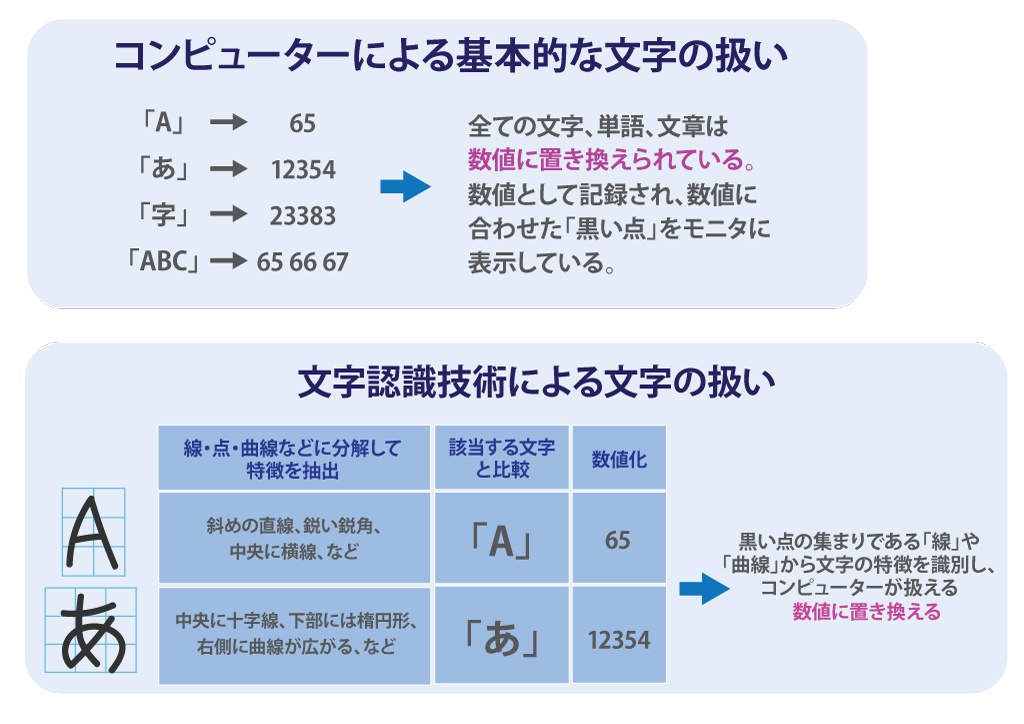
簡単そうに聞こえますが、同じ文字であっても「インクの色」「紙の色」「電灯の色」で受け取る光が違います。光から得られる情報というのは0と1で扱えるデジタルデータではありません。それぞれにわずかな違いの存在するアナログデータなのです。
顔認証システムなどが明かりによって顔が認識できたりできなかったりするのはその典型です。さらにそれが、手書き文字ともなる厄介です。「文字の形」「文字の角度」はもちろんのこと、「インクの染み」「書き間違い」のほか、筆記体や行書体で見られる「線のつながり」が当たり前のように発生するため、簡単には行きません。
【次ページ】人工知能が文字の特徴を見つける方法
AI・生成AIのおすすめコンテンツ
関連タグ
タグをフォローすると最新情報が表示されます
AI・生成AIの関連コンテンツ
あなたの投稿
PR
PR
PR
