- 会員限定
- 2021/05/17 掲載
深層強化学習とは? AlphaGo(アルファ碁)の仕組み
連載:図でわかる3分間AIキソ講座
ディープラーニングが世間一般に知られれるようになったのは、2016年に登場した「AlphaGo(アルファ碁)」という囲碁AIがプロ棋士を破ってからではないでしょうか。グーグルが開発したAlphaGoにはディープラーニングと強化学習を組み合わせた「深層強化学習」が使われており、囲碁に限らずさまざまなゲームにおいて圧倒的な強さを見せつけています。本記事では、「深層強化学習とはどんな技術なのか」を解説していきます。
合同会社Noteip代表。ライター。米国の大学でコンピューターサイエンスを専攻し、卒業後は国内の一部上場企業でIT関連製品の企画・マーケティングなどに従事。退職後はライターとして書籍や記事の執筆、WEBコンテンツの制作に関わっている。人工知能の他に科学・IT・軍事・医療関連のトピックを扱っており、研究機関・大学における研究支援活動も行っている。著書『近未来のコア・テクノロジー(翔泳社)』『図解これだけは知っておきたいAIビジネス入門(成美堂)』、執筆協力『マンガでわかる人工知能(池田書店)』など。
強化学習とディープラーニングを組み合わせた「深層強化学習」
強化学習とは、AI(人工知能)に試行錯誤をさせ、正解や目標に近づいたら報酬を与える学習法です。動物のしつけに似ていると言われる学習法で、おもにゲームやルート探索など「目的を達成するための答えが1つではない」といったようなケースで用いられる学習法です。それでは、ディープラーニングと組み合わせた「深層強化学習」はどうでしょうか。深層強化学習の場合、ディープラーニングによって抽出した対象物の特徴は「目標に近づくための手がかり」として使われます。前回の記事で触れた画像認識の領域では、ディープラーニングによって「動物や生き物の特徴」を見つける仕組みを解説しましたが、それをゲーム内の「スコアを上げるためのアクションの特徴」に置き換えたというわけです。
たとえば、猫と関連性の高い特徴を「瞳や耳の形、毛並み」だとするならば、囲碁における勝利と関連性の高い特徴は「敵の石を囲む」になるというわけです。その上で、敵の石をどうやって囲めば勝利に近づくか、不利な状況でどう打てば危機を脱することができるか、などを強化学習によって学んでいくことになります。
深層強化学習で行われていることは、「現状の確認」→「行動と変化」→「評価と報酬」の繰り返しです。このあたりの考え方は人間にも似ている部分があるはずです。しかし、AIによる試行錯誤の回数は人間の比ではありません。数万回から数百万回というレベルで学習を繰り返し、効率的なプレイスタイルを模索していくのです。
人間の場合、経験から「こうした方が良いかな」と最適な行動の目算をつけることが多いですが、AIの場合は割とランダムに行動することも多いため、明らかに無駄な試行も少なくありません。ところが、こうしたランダムな試行の中に人間には見つけられなかった意外な行動などが含まれています。繰り返していくうちにそうした意外な一手が増えていき、人間以上のプレイヤーになれるのです。

(Photo/Getty Images)
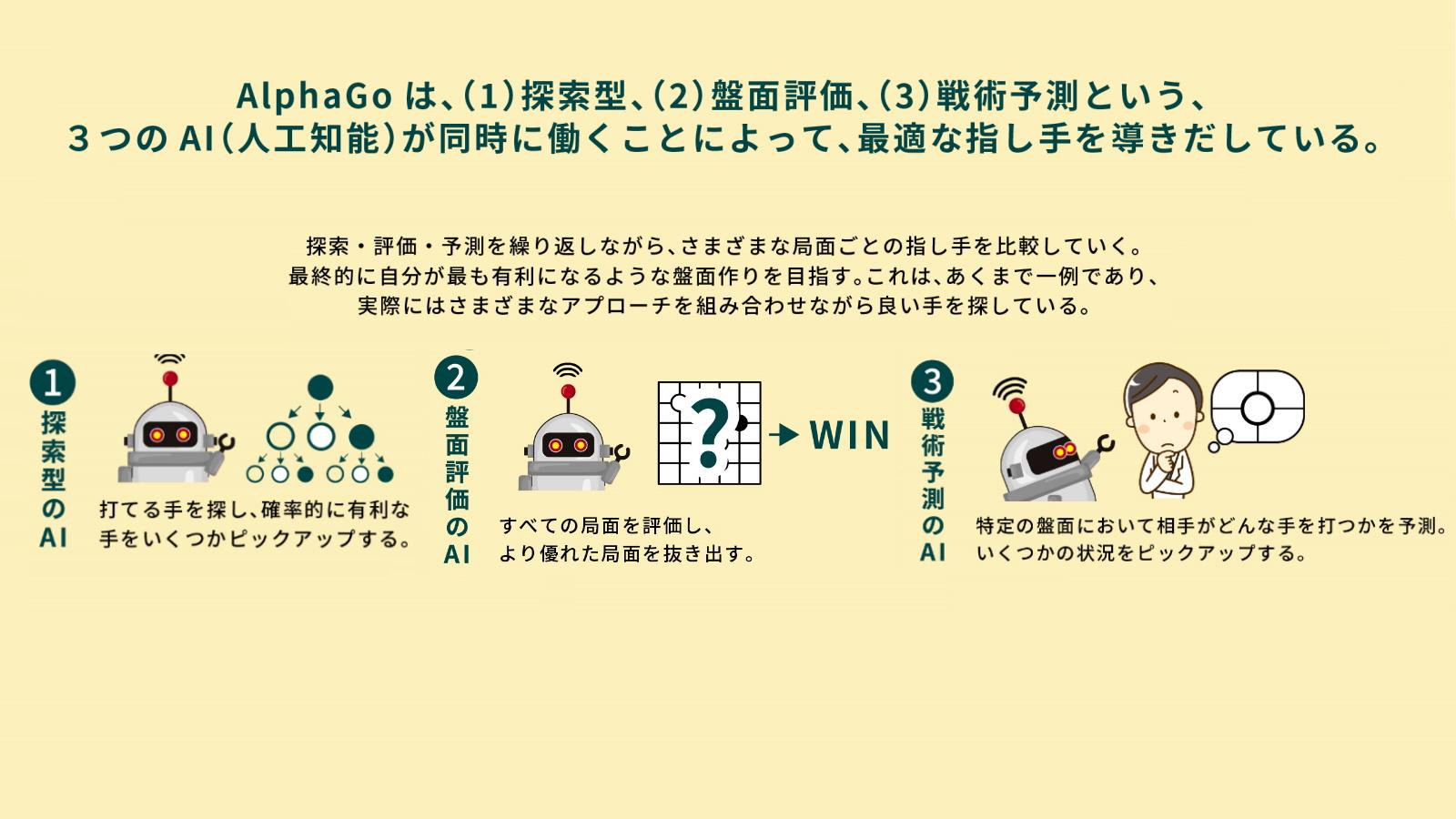
3つのAIを搭載した「AlphaGo」のカラクリ
AlphaGoを例に、少し具体的な深層強化学習の使い方を見ていきましょう。実は、AlphaGoには3つのAIが搭載されています。1つは探索型のAIで、「モンテカルロ木探索」と呼ばれる「統計的に勝つ確率の高い一手」を計算してくれるアルゴリズムを使っています。これはどちらかと言えば、明らかな正解が存在する詰碁のような状況に対応します。
ただ、モンテカルロ木探索は、ある程度盤面が絞り込まれていないと使えません。そこで登場するのが深層強化学習を使った2つのAIです。これはそれぞれ「盤面評価」と「戦術予測」を実行するAIで、同時に別々の目的を持った分析をしています。
盤面評価のAIは、戦況の良し悪しを判断します。盤面と勝利(目的)の関係性について考えていると言えるでしょう。盤面を見て「負けそうな特徴が多い」とか「勝てそうな特徴が多い」というのを見つけ出してくれます。その上で、自分がどこに打てば「勝てそうな特徴の盤面を作れるか」を考えるわけです。
それだけでもある程度の成果は得られますが、そこに「戦術予測」を加えます。こちらは「盤面がこれからどのような展開になるのか」予測します。つまり、盤面と未来の状況についての関係性について考えるのです。
次に自分が打つ手に対して、相手は自分が不利になる(相手が勝つ)ような盤面を作ろうとするので、相手がその手を打った想定で次の一手を考えます。シンプルに「今の状況が有利か不利かについて考えるAI」と「これから有利になるか不利になるかについて考えるAI」と考えても良いでしょう。この2種類を使うことで「有利に見えても逆転されかねない局面」や「不利に見えても逆転ができる局面」を見つけ出すことができるようになるのです。
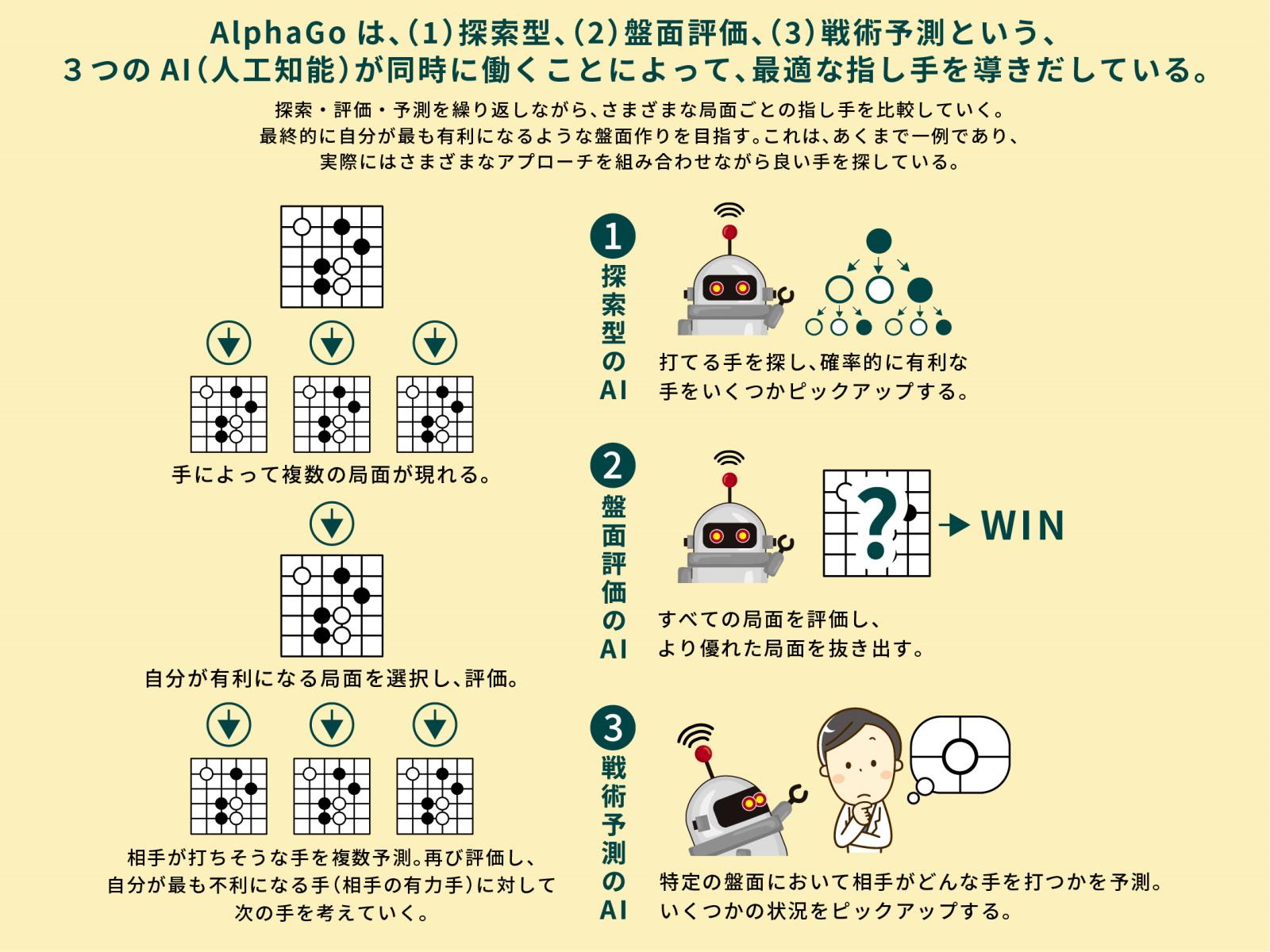
そして、このプロセスに若干のランダム性を加えます。純粋に確率の高い手ばかり打っていると同じようなパターンばかりになってしまって学習の幅が狭まりますし、相手に自分の手を読まやすくなるからです。そうして作られたAlphaGoに人間の棋譜を学ばせ、敵と味方に分かれて何十万回と対戦させることで、優れたAIを作っていくのです。
ただ、グーグルはAlphaGoの進化版である「AlphaZero」を作成し、AlphaGoを破ることに成功しています。こちらは囲碁専用ではなくチェスや将棋もできるAIなのですが、どのゲームでも人間どころか既存の最強クラスのAIよりも強く、しかも棋譜などを学ぶことなく数時間の対戦を繰り返すだけでそこまで成長しました。まるで、なんでもできる天才が初めてやるゲームを脳内シミュレートするだけで誰よりも強くなってしまったかのようです。
【次ページ】深層強化学習はどんな場面で役立つ?
AI・生成AIのおすすめコンテンツ
関連タグ
タグをフォローすると最新情報が表示されます
AI・生成AIの関連コンテンツ
あなたの投稿
PR
PR
PR
