- 会員限定
- 2023/12/18 07:10 掲載
拡散モデルとは?Stable Diffusionなど「画像生成AIの学習モデル」をわかりやすく解説
画像生成AIの存在はすでに当たり前のものになりつつあります。広告やメディアに掲載されているイラストや写真のほか、私たちが普段使っている検索エンジンやブラウザにも搭載されるようになり、気軽に新しい画像を作れるようになりました。このような画像生成AIの急速な普及の背景にあるのが、画像生成AIの学習モデルに採用された「拡散モデル」の存在です。現在、ほとんどの画像生成AIサービスに採用されている「Stable Diffusion」もこの拡散モデルの1つです。本記事では、拡散モデルとは何か、仕組みや事例についてやさしく解説していきます。
合同会社Noteip代表。ライター。米国の大学でコンピューターサイエンスを専攻し、卒業後は国内の一部上場企業でIT関連製品の企画・マーケティングなどに従事。退職後はライターとして書籍や記事の執筆、WEBコンテンツの制作に関わっている。人工知能の他に科学・IT・軍事・医療関連のトピックを扱っており、研究機関・大学における研究支援活動も行っている。著書『近未来のコア・テクノロジー(翔泳社)』『図解これだけは知っておきたいAIビジネス入門(成美堂)』、執筆協力『マンガでわかる人工知能(池田書店)』など。

拡散モデルとは? データの破壊と修復を学ぶモデル
拡散モデル(Diffusion Model)とは、画像生成AIに採用されている学習モデルの1つであり、データの拡散過程(ノイズが付与されて破壊される過程)を学習したモデルのことです。学習した拡散過程を元にして、破壊されたデータ(ノイズデータ)に対して逆拡散過程を施して修復することで、データを元に戻す、もしくは類似のデータを生成することができます。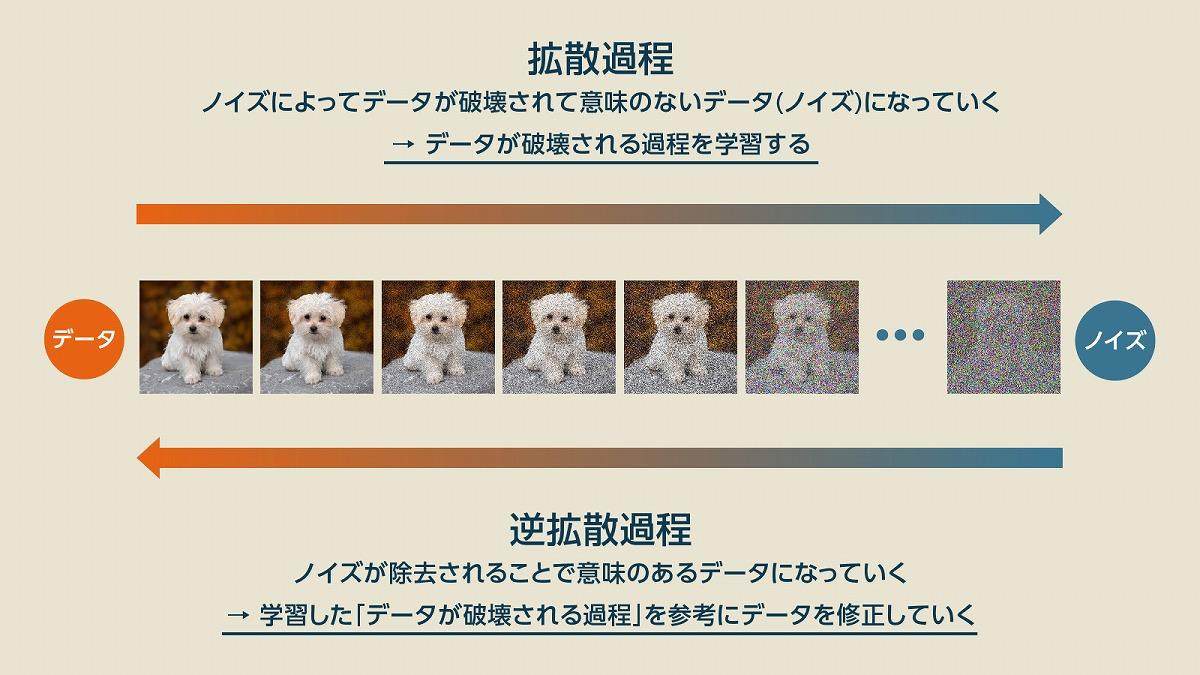
(出典:筆者作成)
これでどうやって画像が生成できるようになるのかという疑問が湧いてきますが、これを理解するヒントは「オートエンコーダー」にありました。オートエンコーダーというのは、入力したデータとまったく同じデータを出力する装置ですが、入力データをよりシンプルで抽象的な「低次元」の情報に変換するという過程を経て出力しています。
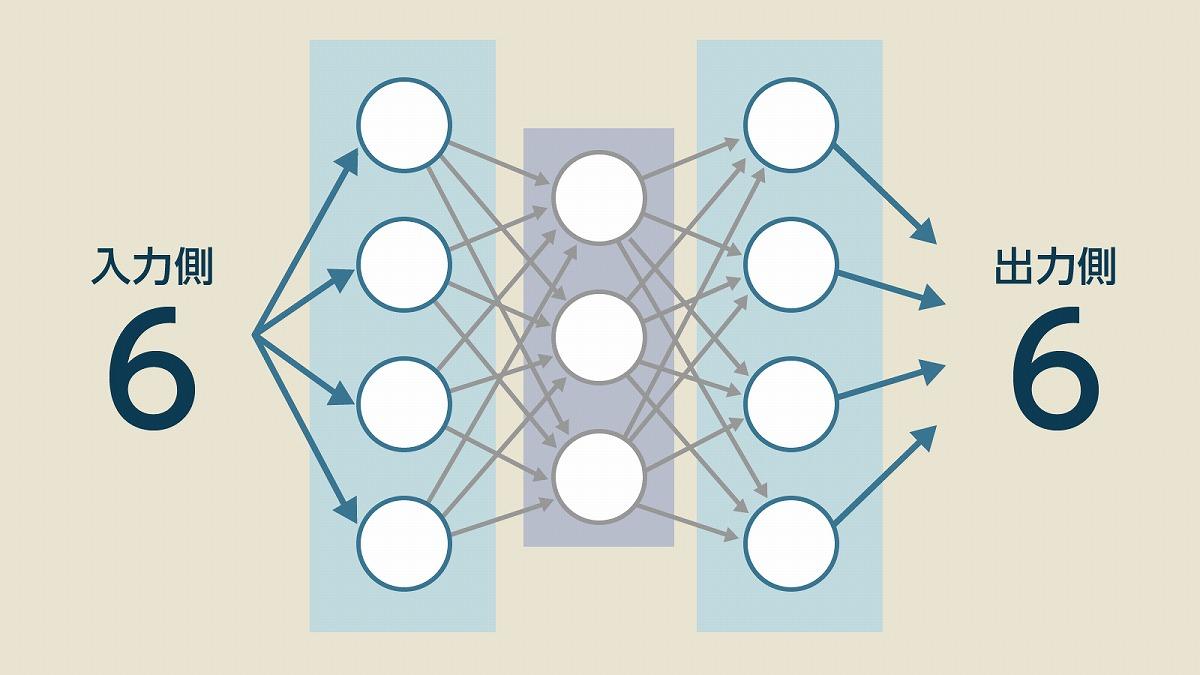
(出典:筆者作成)
ファイルを圧縮して解凍するようなイメージが近いですが、これができるのはデータの持つ「特徴」や「意味」というのを理解できているからです。そのデータが持っている「本来の意味」や「抽象的な概念」を理解していれば、詳細な情報が不足していても元のデータに近い形への修復は可能です。
実際に、オートエンコーダーの原理を応用した生成AIとして「変分オートエンコーダー」なども開発されており、どちらも画像の概念を学んでいるという点で拡散モデルと比較される点の多い技術です。
ただ、拡散モデルの場合は「多少破損」というレベルではなく、完全に破損して跡形がないレベルにまでデータを破壊します。つまり、これを修復できるということはデータの概念を正しく理解した上で「ゼロから生成する」のと変わりません。
データのすべてを破壊する過程をひたすら学習させ続け、改めてゼロから作り直せるようになるまで訓練することで画像の作り方を覚えさせるというわけです。人間であれば、なかなかの過酷なトレーニングです。
これができるようになると、画像生成は簡単です。データを生成する元になるノイズ(ランダムデータ)を毎回異なる状態にして画像を作らせると、同じようなプロセスで画像を作っていても、それぞれ少し異なる画像ができあがります。
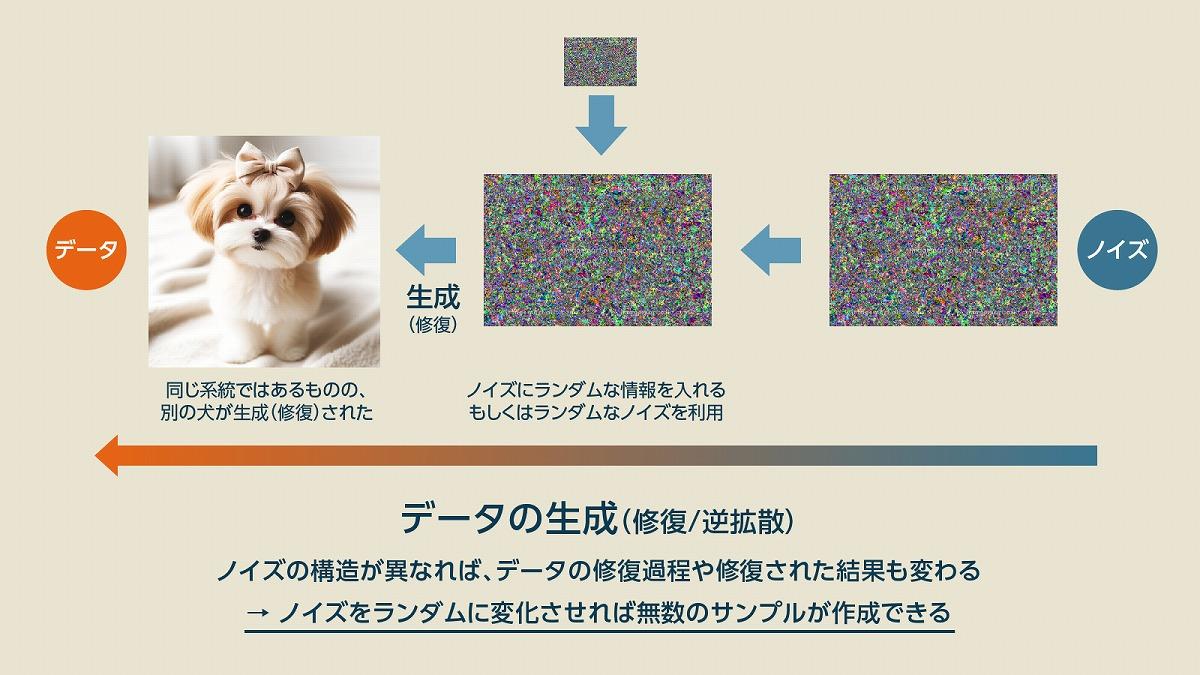
(出典:筆者作成)
このようにして作られたデータはノイズを変えれば毎回異なる画像になるため、大量の画像を瞬時に生成することができるようになります。しかし、これだけではただのサンプル画像の生成マシンに過ぎません。私たちが使っている「プロンプトを入れれば好きな画像を作れる生成AI」にたどり着くには、もうワンステップ必要です。
関連用語(1):Text to Image、VLM
私たちが画像生成AIでイメージする、「プロンプト(指示)を入力すれば、指示通りの画像を作ってくれるアプローチ」のことを「Text to Image(t2i)」と呼びます。また、テキストではなく「ベースとなる画像」と似たような画像を作るアプローチは「Image to Image (i2i)」と呼びます。まずはText to Imageについて説明しましょう。Text to Imageで重要になるのは「VLM(Visual Language Model)」と呼ばれる画像とテキストの関係性を学習したマルチモーダルな学習モデルの存在です。
このVLMでは、画像とそれに関係するテキスト(タグ・ラベル・アノテーション)を学習しています。ここでは画像認識モデルのように「画像を見たら正解となるテキストを出力する」といったような学習は行われません。あくまで画像とテキストの関係性を学習し、テキスト情報が付与された「画像の概念」のような情報を扱っているため、汎用的なVLMは拡散モデル以外の用途にも使われています。
そして、プロンプトなどを通じてVLMはテキストと画像の関係性を表す情報を出力し、その情報を拡散モデルのノイズデータに追加します。これにより、ノイズデータは一見すると意味のないデータでありながら「画像の概念情報」を持つノイズになります。このノイズは「言葉」でもなければ「画像」でもなく、抽象的な数字の羅列で表現された「潜在的な何かしらの意味を持つノイズ」に変わります。このような情報を潜在変数、情報が扱われる場所を潜在空間と呼びます。
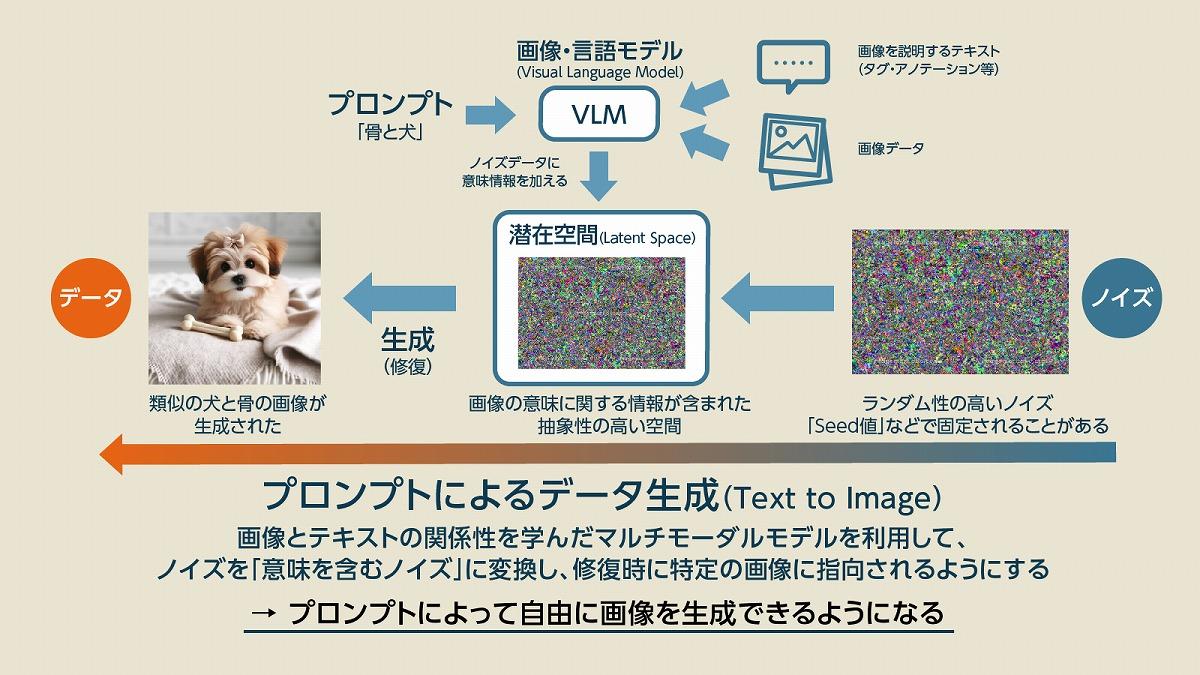
(出典:筆者作成)
潜在空間は人間で言えば、頭の中にある漠然とした抽象的な「なんとなくのイメージ」に近いです。言葉にもできないし、絵で書くことも難しいけど、頭の中では理解しているので、問題や課題を与えられればタスクをこなせるといった状態です。
この潜在空間の情報をベースに拡散モデルが画像を生成すると、ノイズに付与された「概念情報」の部分に応じた画像が生成されるようになるのです。つまり、画像の作り方を覚えた拡散モデルに、画像の概念を理解しているVLMを組み合わせて画像を生成しているのがText to Imageというわけです。
関連用語(2):Image to Image
次にImage to Imageの説明です。Image to Imageでは、最初の入力画像にノイズを加えて潜在空間のノイズデータに変換します。このときにVLMなどを使って、プロンプトなどの指示情報を追加することで潜在空間の情報を変化させます。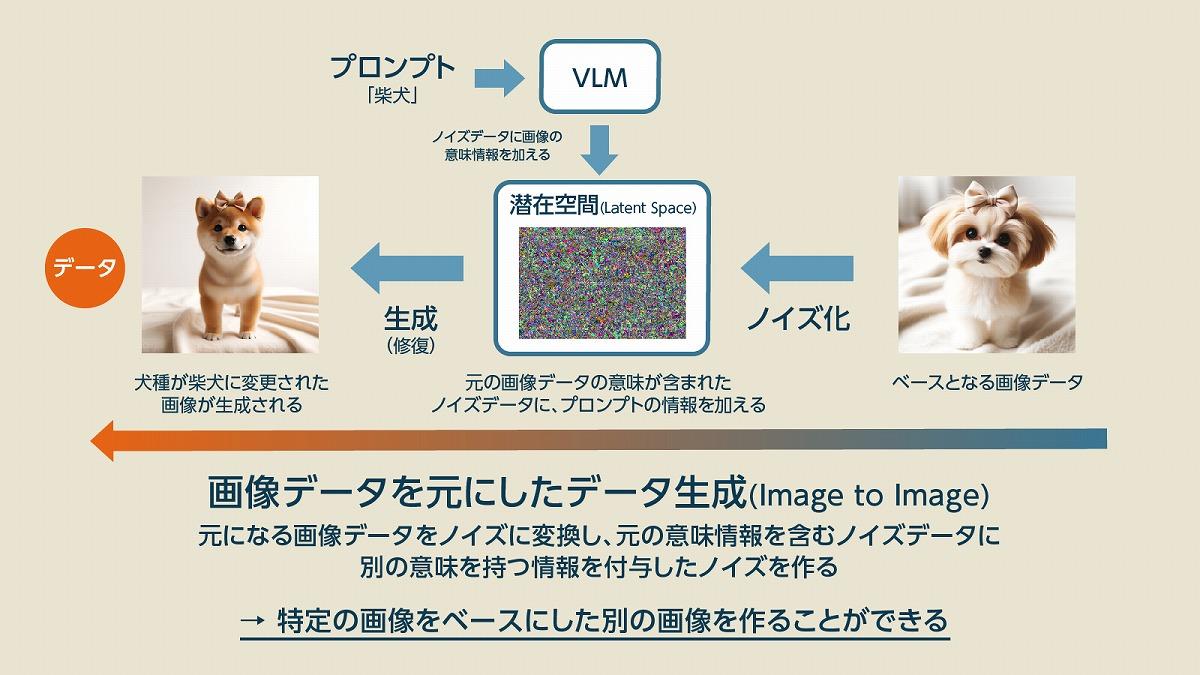
(出典:筆者作成)
そして、潜在空間の中で「別の意味を加えられたノイズデータ」を拡散モデルによって画像化することで、元の画像に似ているものの、少し異なる画像データが生まれるというわけです。
Text to Imageでも、Image to Imageでも、潜在空間という「漠然とした抽象的な脳内空間」の中で画像や言葉の概念を処理しているという点が特徴的です。この潜在的な情報空間は、ニューラルネットワークではベクトルなどのやや低次元の数列で表現される事が多く、比較的扱いやすいことから説明可能AIへの応用なども検討されており、マルチモーダル型のAIでは極めて重要な要素になりつつあります。
類似の生成AI「GAN」とは何が違う?
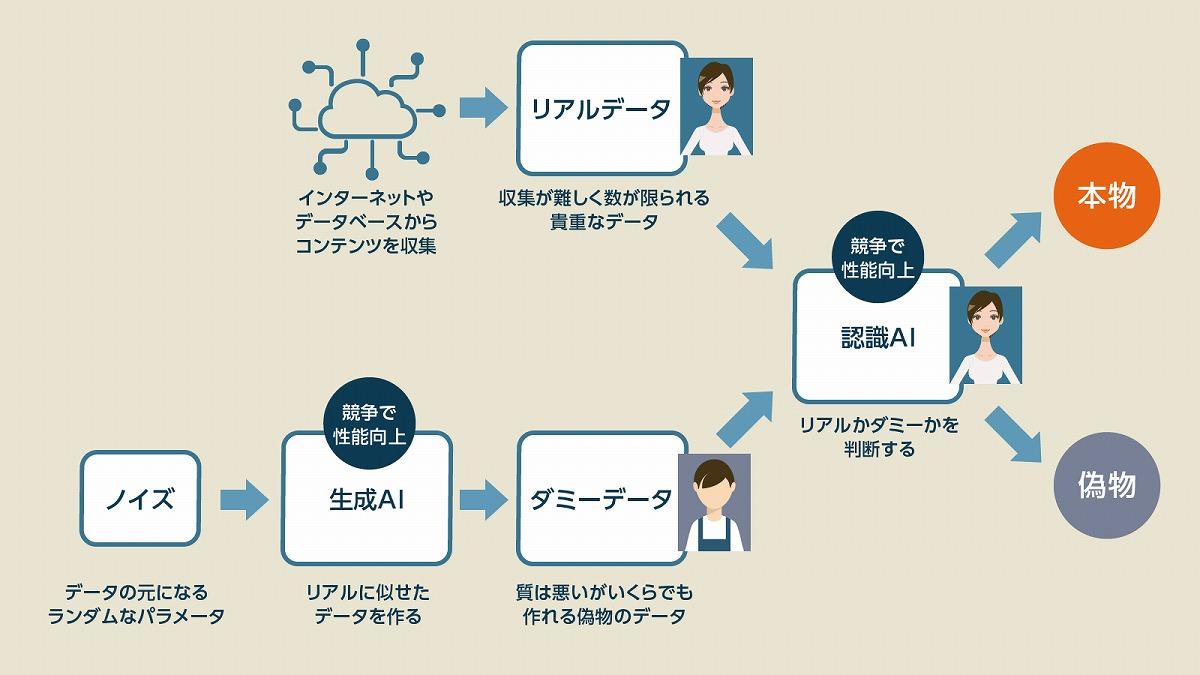
拡散モデルと類似の生成AIにGAN(敵対的生成ネットワーク)があり、こちらも画像生成AIなどで注目されました。こちらは画像を生成する「生成AI」の画像を、画像を識別する「認識AI」が、本物か偽物かを見抜けるかといった手法で双方のAIを学習させていく手法です。こちらの手法は、拡散モデルやオートエンコーダーのような「画像の概念」を学ばせるような手法ではなく、どちらかと言えば「現実の画像と比較しながら間違った場所を修正していく」という、“美しい絵を書くための丁寧なアプローチ”と言えます。
結果的にGANは拡散モデルに比べると美しく写実的な画像を生成でき、現実の写真やイラストと区別がつかないような精巧な画像をつくれるようになります。しかし、画像の概念を学んでいるわけではないので応用が苦手で多様性に乏しく、プロンプトから自由に画像を生成するといった使い方はやや難しい傾向にあります。
(出典:筆者作成)
一方で、拡散モデルは精巧な画像を作るという意味ではGANに及びませんが、あらゆる要求に答えられる多様性を持つため「平均点」が極めて高く、GANが苦手とするあらゆる領域で高いスコアを出せます。ただ、生成プロセスにかかる計算量が高くなりがちで、時間がかかるというのが欠点です。GPUの高性能化によって軽減されてはいるものの、拡散モデルに残された課題の1つとなっています。 【次ページ】【拡散モデル事例】Stable Diffusion、DALL-E、Midjourney、Adobe Fireflyを解説
AI・生成AIのおすすめコンテンツ
関連タグ
タグをフォローすると最新情報が表示されます
AI・生成AIの関連コンテンツ
あなたの投稿
PR
PR
PR
