- 会員限定
- 2023/11/22 07:10 掲載
自動機械学習(AutoML)とは?データサイエンティストの仕事が激減するほどの実力とは
ありとあらゆるツールやシステムに何らかの機械学習技術が取り入れられるようになり、従来はデータサイエンティストによって行われてきた「データ収集・学習・分析」も効率化が進み、ある種の機械学習ルーティンが作られるようになりました。そのような中で、機械学習における学習プロセスを自動化する「自動機械学習(AutoML)」という技術・サービスが登場するようになってきました。今回は、AutoMLという技術について解説します。
合同会社Noteip代表。ライター。米国の大学でコンピューターサイエンスを専攻し、卒業後は国内の一部上場企業でIT関連製品の企画・マーケティングなどに従事。退職後はライターとして書籍や記事の執筆、WEBコンテンツの制作に関わっている。人工知能の他に科学・IT・軍事・医療関連のトピックを扱っており、研究機関・大学における研究支援活動も行っている。著書『近未来のコア・テクノロジー(翔泳社)』『図解これだけは知っておきたいAIビジネス入門(成美堂)』、執筆協力『マンガでわかる人工知能(池田書店)』など。

AutoMLとは?
AutoMLとは「Automated Machine Learning」の略で、日本語では「自動機械学習」という意味になります。要するに、機械学習のプロセスを自動化する技術です。ただ、AutoMLが指す自動化にもさまざまなものがあり、機械学習プロセスのすべてを自動化するものもあれば、一部を自動化するものもあり、用途や扱うデータによって使い方は変わります。AutoMLで自動化できる「機械学習のプロセス」
機械学習のプロセスは大きく分けて下記のようなステップに分けられます。この中でAutoMLが自動化するのは主に「データの前処理」から「運用と再学習」までのステップとなります。
■機械学習のプロセス(イメージ)
- 「データの収集」
- 「アノテーション(ラベル付け)」
- 「データの前処理」※
- 「特徴量エンジニアリング」※
- 「データを使った学習」※
- 「学習結果の評価と調整」※
- 「運用と再学習」※
※AutoMLの対象とする領域
機械学習における「データ収集」の工程は、集めるデータによって使える方法がまったく異なります。Web上のデータを収集する場合は「スクレイピング」などの技術や専用のツールを使ってデータを集めることが多いですが、AutoMLの多くはそうした収集の自動化はサポートしていません。
次に、収集したデータに対して、そのデータが何を示すのかといったメタデータやラベルを付与する「アノテーション」という作業を行います。この作業も扱うデータによって使えるツールがまったくことなり、人力で行われることも多く、ほとんどのAutoMLの範疇外です。
生成AIで1分にまとめた動画
このようなデータ収集に関する前工程はすべての機械学習プロセスで必要になるわけではありませんが、少なくともこれに類する作業が終わっていなければそれは「学習データ」としては使いにくいものになります。
ただ、学習データとしては使いにくい非構造化データやラベルの不要な教師なし学習のアルゴリズムに対応したAutoMLであれば、収集したデータを直接流し込んで使うことも可能なので要確認です。
AutoMLにも色々な種類があるため、一概に「こういう作業をしている」とは言えませんが、多くの機械学習に共通しているのが、この「データの前処理」「特徴量エンジニアリング」「データを使った学習」「学習結果の評価と調整」「運用と再学習」の5つのステップです。ここからは1つずつ、その仕組みを見ていきます。
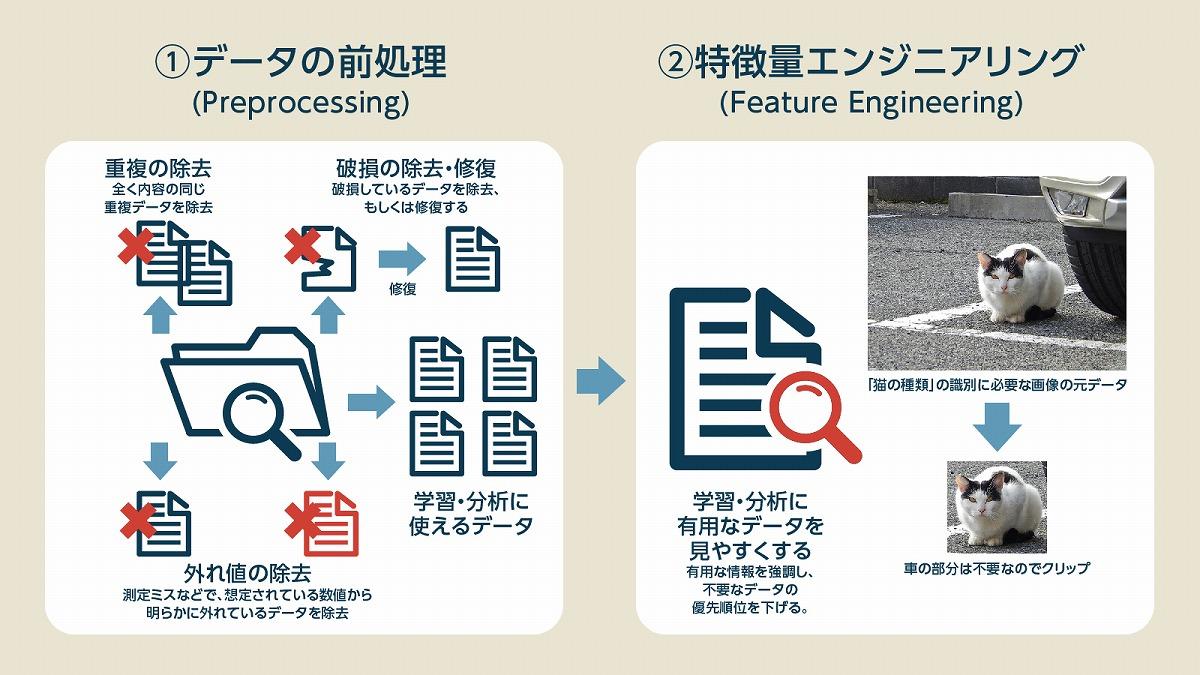
プロセス(1):データ前処理
収集されたデータから不要なものを除去し、破損したデータを修復するプロセスが「前処理」と呼ばれるものです。料理で例えるなら、じゃがいもの芽を取ったり皮を剥いたりするようなイメージでしょうか。どんな料理をするにしても、食材を料理に使うためには最低限必要な作業になります。ただ、データセンターや業者からデータを入手している場合、データ収集ツールが前処理に対応している場合、アノテーションツールが前処理まで行っている場合など、最初から前処理が終わっているようなケースも少なくありません。とはいえ、本当に前処理が終わっているのかどうかの確認も含めて必要不可欠なプロセスです。
ここで不要なデータや誤ったデータが混入していると、学習の精度が落ち、分析結果も不正確になる可能性があります。すべてのデータをチェックする必要があり、かなりの労力を必要とする作業ですが、AutoMLで自動化することで大幅に作業を効率化できます。
(出典:筆者作成)
プロセス(2):特徴量エンジニアリング
次に、特徴抽出、および特徴量エンジニアリングと呼ばれる「学習に使いやすいデータを作る作業」を行います。学習の精度を上げつつ、少ないデータで効率よく学習するために必要な作業です。先程の料理の例え話に合わせるなら、食材を食べやすい大きさにカットして、下味をつけるようなイメージでしょうか。前処理と似ているように思われるかもしれませんが、前処理では「データの内容を詳しく見る」ようなことはしていません。あくまでデータは元データのままで保持され、綺麗な食材を用意するまでが前処理です。
しかし、このステップではデータを特徴が分かりやすい形に修正したり、特徴だけを取り出したり、バイアスを含むデータに調整を加えたりします。こうしたプロセスを行うことで本当に必要なデータを使って効率的に学習ができるようになるほか、データに含まれる不必要なバイアスを除去することも可能です。
たとえば、画像認識で猫の種類を識別するためのモデルを作りたい場合には、データの背景情報を減らすのも特徴を強調するための1つの手段です。猫の画像には多かれ少なかれ「床や地面」が含まれているわけですが、その情報まで学習してしまうと「青い空に向かって飛び上がる猫」を猫ではないと認識する可能性が高まります。背景情報が除去されていれば、こうしたリスクは下がります。もちろん、タスクによっては背景が重要になる場合もあるため、すべての画像から背景を除去すれば良いというわけではありません。
こうしたタスクに必要とされる重要な特徴を見やすくして使いやすくするプロセスのことを「特徴量エンジニアリング」と呼びます。このプロセスでは、データに含まれる「どの特徴を強調するか」という点を決めることが難しく、ここで誤った処理を施せば逆にバイアスを強める結果にもなります。
このようなタスクは、今まではまさにデータサイエンティストの仕事とされていました。しかし、こうしたタスクも簡略化・自動化することが可能になっており、このプロセスをうまく進められることがAutoMLの性能を大きく分けるポイントになります。 【次ページ】AutoMLのプロセスの残り3つ、市場規模、事例3選をまとめて解説
AI・生成AIのおすすめコンテンツ
関連タグ
タグをフォローすると最新情報が表示されます
AI・生成AIの関連コンテンツ
あなたの投稿
PR
PR
PR
