- 2022/10/15 掲載
Amazon DynamoDBとは何かをわかりやすく図解、どう使う?テーブル設計の方法とは
連載:全部わかるAWS入門
Amazon DynamoDBとは、可用性(Availability)とネットワーク分断耐性(Partition Tolerance)を重視したAP型と呼ばれるデータベースの代表例です。クラウド環境ならではの水平スケーラビリティに優れた特徴を持っています。ここではAmazon DynamoDBをどう使うのがよいのか?わかりやすく解説していきます。
川畑 光平(かわばた・こうへい)
エグゼクティブ ITスペシャリスト、ソフトウェアアーキテクト・デジタルテクノロジーストラテジスト(クラウド)。金融機関システム業務アプリケーション開発・システム基盤担当、ソフトウェア開発自動化、デジタル技術関連の研究開発を経て、クラウド技術に関する研究開発・推進に従事。
AWS Partner Ambassadors / APN AWS Top Engineers since 2019。
菊地 貴彰(きくち・たかあき)
シニアITスペシャリスト(クラウド)。システム基盤担当として公共、金融、法人の各業界のシステム開発に従事。現在は学生時代の専攻である機械学習のノウハウを活かしつつ、デジタル技術やAgile開発プロセスを用いたシステム開発を中心に担当。AWS Partner Ambassadors、APN AWS Top Engineers、APN ALL AWS Certifications Engineersに選出。
真中 俊輝(まなか・としき)
NTTデータに入社後、クラウドを中心とした公共、金融、法人のシステム開発の支援やクラウド人材の育成を担当。2019-2020年にAWS APN Top Engineersに選出。
本記事は『AWSの基本・仕組み・重要用語が全部わかる教科書』の内容を一部再構成したものです。
Amazon DynamoDB の概要
Amazon DynamoDBは、可用性(Availability)とネットワーク分断耐性(Partition Tolerance)を重視したAP型データベースの代表例で、クラウド環境ならではの水平スケーラビリティに優れた特徴を持っています。その特性をよく理解して、大規模分散処理構成のユースケースで活用しましょう。水平スケーラビリティとは、サーバなどのリソースの数を増やしてシステム全体のパフォーマンスを高める手法のことです。既存のリソースの性能を向上することでシステムのパフォーマンスを高める手法のことを、垂直スケーラビリティといいます。
ここがポイント
- AP型データベースは、複数のアベイラビリティゾーンにまたがってデータを分散して保存するアーキテクチャで構成されている。そのため単一障害点がなく、特に書き込み処理の水平スケーラビリティに優れた特性を持つ
- AP型データベースを使いこなすうえで押さえておくべき重要な概念として、各ノードに配置される「データ」と「キー」の関係性と、データ読み書きにおける結果整合性がある
- AP型データベースでは、RDBで可能だった複雑な検索やテーブル結合などは実行できない。代わりにインデックスを駆使したり、不足する機能に代替する処理をアプリケーションで実装したりする必要がある
- DynamoDBは、特に項目・属性の定義が必要ないスキーマレスのテーブル構造を持つ。属性は項目ごとに異なっても問題ない
- DynamoDBは、読み書き処理に関する結果整合性をオプションで選択できる。処理の重要性に応じて使い分ける
- DynamoDBには、条件付き書き込み、DAX、DynamoDB Streamsといった固有の機能がある。さまざまな処理で活用できるので、一通り内容を押さえておく
AP型データベースのアーキテクチャ
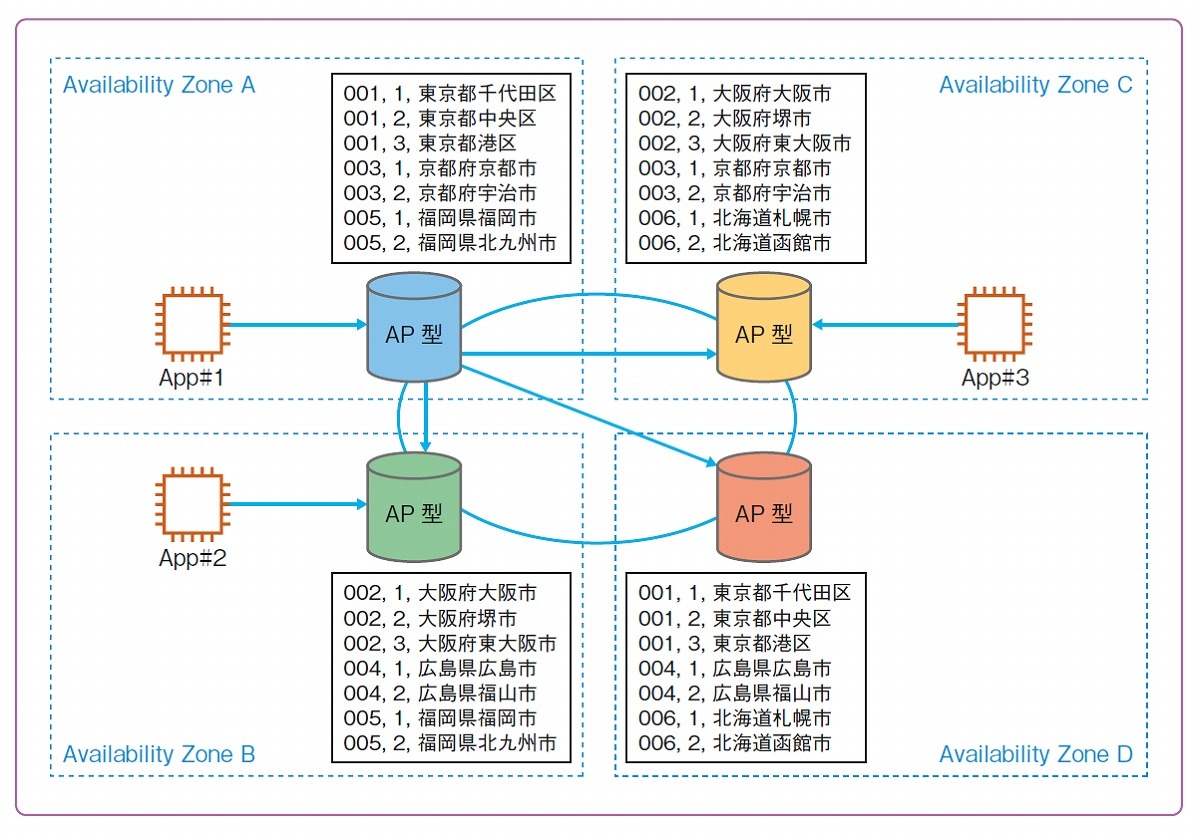
最初に、AP型データベースに共通する特徴を押さえておきましょう。AP型のNoSQLデータベースは、一貫性(Consistency)が下がる代わりに、可用性(Availability)とネットワーク分断耐性(Partition Tolerance)を高めています。具体的には、次のイメージのように複数のアベイラビリティゾーンにデータベースを配置し、各ノードにデータを分散して配置することで実現しています。

画像をクリックすると購入ページに移動します
ただし、ノードの故障や通信のエラーにより、複数のノード間で整合性のとれない(一貫性を損なう)ケースが発生します。
その回避策として、読み込み時に最新のデータで古いノードのデータを更新するReadRepair機能や、Quorumを使って結果整合性をとる方法(簡単にいえば、不整合が出た場合に、なるべく多くの一致したデータを判定する多数決に似た手法)で対応しています。
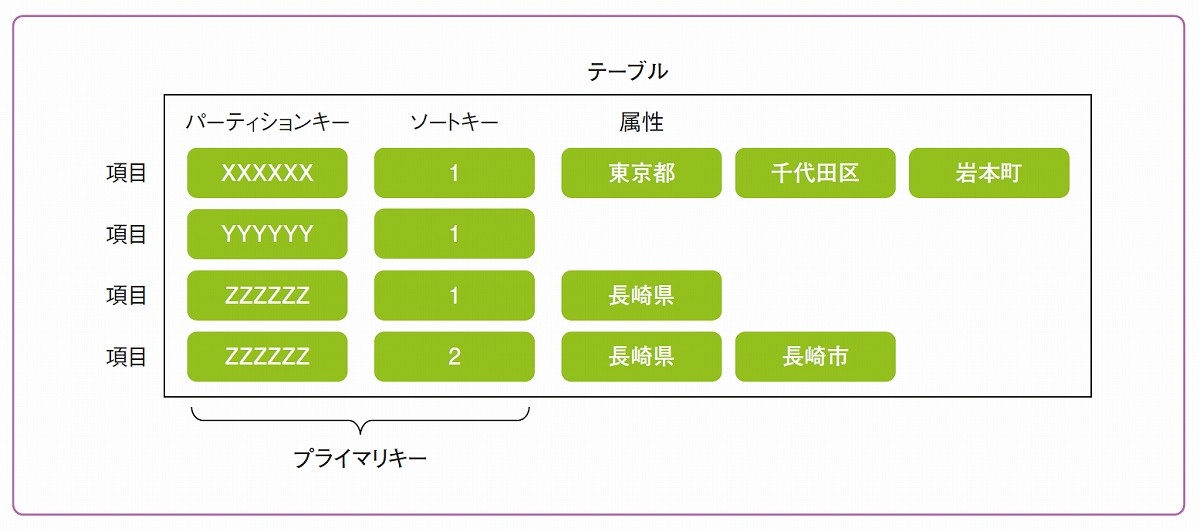
AP型データベースを理解するうえで、押さえておかなければならないのが、各ノードに配置される「データ」と「キー」の概念です。DynamoDBでは「Consistent Hashing」と呼ばれるアルゴリズムにより、各ノードと配置されるデータを決定しています。例えば、先の図では都道府県と市/区は1:Nの関係であり、都道府県を区別するキーを「親キー」、市や区を区別するキーを「子キー」とします。DynamoDBで親キーをパーティションキー(Partition Key)、子キーをソートキー(Sort Key)と呼びます。
Memo
DynamoDBでは以前、パーティションキーは「ハッシュキー(Hash Key)」、ソートキーは「レンジキー(Range Key)」という名称で呼ばれていました。また現在、パーティションキーとソートキーを合わせて「プライマリキー(Primary Key)」と呼んでいます。
DynamoDBでは以前、パーティションキーは「ハッシュキー(Hash Key)」、ソートキーは「レンジキー(Range Key)」という名称で呼ばれていました。また現在、パーティションキーとソートキーを合わせて「プライマリキー(Primary Key)」と呼んでいます。
これらのキーに対して、次のルールを押さえておくことが必要です。
- 親キーで配置されるノードが決定する
- ノード内のデータ順序を決定する子キーを任意に設定できる
- 子キーを作成しない場合は、親キーでデータを一意に特定できるようにする必要がある
- キーにはインデックスを設定できる
こうしたデータを分散して保持するAP型の仕組みを踏まえると、当然、RDBで当たり前にできていた次のようなことができなくなります。
| ● RDBと比較した場合のAP型データベースの制約 | |
| 制約 | 理由 |
| テーブル間の結合ができない | データが分散して配置されているので、「データ同士を結合して射影する」といった操作はできない |
| 外部キーがない | キーはパーティションキーとソートキーに限定される |
| 条件指定は基本的に、プライマリキー以外は使用できない | データが分散して配置されているので、プライマリキー以外で検索をかけることができない。それ以外の項目で検索が必要な場合は、インデックスを作成する、もしくはソートキーを指定する(ただし、ソートキーのみの検索は性能上問題が出る可能性がある) |
| 副問合せができない | データが分散して配置されるので、検索結果のデータを条件とすることができない |
| GROUP BYなどの集約関数が存在しない | データが分散して配置されるので、集約に必要なデータが検索時に足りない |
| OR、NOTなどの論理演算子はなくANDのみ | データベースの性質上、サポートしない |
このように、AP型のNoSQLデータベースを、RDBの代替として考えるには機能制約が相応にあります。RDBで実現できる機能を使いたい場合は、RDBを導入すべきであり、NoSQLデータベースは、その特性を生かしたユースケースに対して導入を検討すべきです。
ただし、AP型NoSQLデータベースを導入する場合でも、前述の表に記載されているさまざまな機能要件を求められるケースもあります。アプリケーションの設計時に制約をしっかりと意識し、データベースの機能に委ねるべきか、不足する機能に代替する処理をアプリケーションで実装すべきかを判断できるようにしておきましょう。
DynamoDBの概要と特徴
DynamoDBは、AWSが提供するAP型NoSQLデータベースのマネージドサービスです。項目・属性の定義が必要ないスキーマレスのテーブル構成をとります。スキーマレスということもあり、値の厳密な設計が不要な他に、属性は項目ごとに異なっても問題ありません。パーティションキーで配置するノードが決定し、ソートキーでノード内でのデータ順序が決定するため、注文と注文明細のような1対多のデータ構造でもそのまま保存することができます。キーの判定には関係演算子(<、>、<=、>=)や等値系演算子(==、!=)が利用可能です。
なお、DynamoDBのデータサイズ上限は1項目あたり400KBです。バイナリデータなどサイズの大きくなりがちなデータは保存できないので注意が必要です。
DynamoDBはリージョンごとにデータベースが構築されるサービスであり、3箇所の異なるアベイラビリティゾーンにデータがレプリケーションされます。結果整合性に関しては、オプションで選択可能です。
| ● DynamoDBの結果整合性オプション | ||
| 結果整合性のオプション | 動作 | |
| 読み込み | 結果整合性のある読み込み | 2/3の読み込みで結果が一致した場合、正常応答 |
| 強い読み込み整合性 | すべてのReadRepairが完了している状態で結果を応答 | |
| トランザクション読み込み | 直列化可能分離レベル(SERIALIZABLE)でデータを読み取るオプション | |
| 書き込み | 結果整合性のある書き込み | 2/3以上の書き込みが成功した場合、正常応答 |
| トランザクション書き込み | すべての書き込みが成功した場合、正常応答 | |
DynamoDBではテーブル単位で読み書きのパフォーマンスをスループットとして定義します。読み取りのスループットを「読み込みキャパシティユニット」(Read Capacity Units:RCUs)と呼び、書き込みスループットを「書き込みキャパシティユニット」(Write Capacity Units:WCUs)と呼びます。RCUsとWCUsはそれぞれ次のように定義されています。
| ● キャパシティユニットの定義 | |
| 種類 | 説明 |
| RCUs |
|
| WCUs |
|
例えば、3KBのデータを読み込むリクエストが毎秒1000回あるのであれば、1000RCUsです。仮に6KBのデータだとすると、ブロック単位の4KBを超えているので、2ブロック(8KB)が必要です。
すなわち、2倍のRCUsとして計算し、2000RCUsとなります。結果整合性のある読み込みの場合、スループットが2倍になるのでRCUsは半分で済み、3KBだと500RCUs、6KBだと1000RCUsです。
書き込みも計算方法は同様で、3KBのデータを書き込むリクエストが毎秒10回あるとすると、30WCUsです。トランザクション書き込みはスループットが半分になるので、倍の60WCUsが必要になります。
DynamoDBにはその他に、次のような特徴・機能があります。
| ● DynamoDBの特徴 | |
| 特徴 | 説明 |
| フィルタを使った読み込み | クエリやスキャンした結果にフィルタを設定し、結果を絞り込む機能 |
| 条件付き書き込み | データの有無や項目値に応じた条件を設定でき、該当したとき更新を行う機能 |
| TTL (TimeToLive) |
データ属性にTTLを設定し、有効期限を過ぎると自動的にテーブルからデータを削除する機能 |
| DAX (DynamoDB Accelator) |
マルチアベイラビリティゾーン構成で自動フェイルオーバー機能をもつインメモリキャッシュ |
| DynamoDB Streams | DynamoDB で行われたデータの追加・変更・削除履歴を記録する機能。更新前のデータを残す、更新前後のデータ双方残すなどのオプションも選択できる |
| クロスリージョン レプリケーション |
リージョンをまたいでDynamoDBを構築する機能。リージョンを超えて1つのテーブルが構築されるわけではなく、DynamoDBのレプリカが別のリージョンに構成されるイメージ。更新は双方同期される |
| DynamoDB Trigger | DynamoDBへのデータ更新をきっかけにLambdaファンクションを実行する機能。別のテーブルの更新や監査ログの保存、プッシュ通知などの用途で利用可能 |
押さえておきたい プライマリキーとセカンダリインデックス
データを一意に識別するためのプライマリキー(PrimaryKey)は、パーティションキー(PartitionKey)単独、あるいはソートキー(SortKey)との組み合わせで構成されます。DynamoDBはスキーマレスの構造を取るので、プライマリキーに該当する属性以外は事前に定義しておく必要はありません。
検索には基本的にプライマリキーを用いますが、任意の属性をパーティションキーとするグローバルセカンダリインデックス(GlobalSecondaryIndex:GSI)と、パーティションキーと別の属性とを組み合わせて作成するローカルセカンダリインデックス(LocalSecondaryIndex:LSI)が利用できます。
ただし、セカンダリインデックスを使用するには、上記のキャパシティユニットやインデックスを保存するためのストレージが別途必要になるので注意が必要です。
データを一意に識別するためのプライマリキー(PrimaryKey)は、パーティションキー(PartitionKey)単独、あるいはソートキー(SortKey)との組み合わせで構成されます。DynamoDBはスキーマレスの構造を取るので、プライマリキーに該当する属性以外は事前に定義しておく必要はありません。
検索には基本的にプライマリキーを用いますが、任意の属性をパーティションキーとするグローバルセカンダリインデックス(GlobalSecondaryIndex:GSI)と、パーティションキーと別の属性とを組み合わせて作成するローカルセカンダリインデックス(LocalSecondaryIndex:LSI)が利用できます。
ただし、セカンダリインデックスを使用するには、上記のキャパシティユニットやインデックスを保存するためのストレージが別途必要になるので注意が必要です。
DynamoDBの利用料金
DynamoDBの利用では、2種類の課金体系があります。リクエスト数に応じた従量課金となる「オンデマンドキャパシティモード」と、キャパシティユニットの設定値に応じて時間単位の従量課金となる「プロビジョンドキャパシティモード」です。いずれかのモードの料金に加えて、データベースに保存するデータ量や利用した機能に応じて料金が発生します。| ● DynamoDBの利用料金 | |
| 項目 | 内容 |
| オンデマンド キャパシティモード |
|
| プロビジョンド キャパシティモード |
|
| データベースストレージ | データ量に応じた従量課金 |
| バックアップストレージ・ データ復元 |
データ量に応じた従量課金 |
| データ転送量 |
|
| グローバルテーブル (クロスリージョンレプリケーション) |
|
| DAX | インスタンスタイプに応じた従量課金 |
| DynamoDB Stream | Streamからの読み込みリクエスト数に応じた従量課金 |
| DynamoDB Trigger | AWS Lambdaファンクションのリクエスト回数と実行時間に応じた従量課金 |
詳細はAWSのサイトでも確認することができます。
クラウドのおすすめコンテンツ
Googleで見つけやすく
共有する
-
0
-
1
-
0
-
0
-
0
関連タグ
タグをフォローすると最新情報が表示されます
あなたの投稿
おすすめのコメント
PR
PR
PR
